 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocs2Synth: A Synthetic Data Trained Retriever Framework for Scanned Visually Rich Documents Understanding
Jan 18, 2026Document understanding (VRDU) in regulated domains is particularly challenging, since scanned documents often contain sensitive, evolving, and domain specific knowledge. This leads to two major challenges: the lack of manual annotations for model adaptation and the difficulty for pretrained models to stay up-to-date with domain-specific facts. While Multimodal Large Language Models (MLLMs) show strong zero-shot abilities, they still suffer from hallucination and limited domain grounding. In contrast, discriminative Vision-Language Pre-trained Models (VLPMs) provide reliable grounding but require costly annotations to cover new domains. We introduce Docs2Synth, a synthetic-supervision framework that enables retrieval-guided inference for private and low-resource domains. Docs2Synth automatically processes raw document collections, generates and verifies diverse QA pairs via an agent-based system, and trains a lightweight visual retriever to extract domain-relevant evidence. During inference, the retriever collaborates with an MLLM through an iterative retrieval--generation loop, reducing hallucination and improving response consistency. We further deliver Docs2Synth as an easy-to-use Python package, enabling plug-and-play deployment across diverse real-world scenarios. Experiments on multiple VRDU benchmarks show that Docs2Synth substantially enhances grounding and domain generalization without requiring human annotations.
Multimodal Commonsense Knowledge Distillation for Visual Question Answering
Nov 05, 2024Existing Multimodal Large Language Models (MLLMs) and Visual Language Pretrained Models (VLPMs) have shown remarkable performances in the general Visual Question Answering (VQA). However, these models struggle with VQA questions that require external commonsense knowledge due to the challenges in generating high-quality prompts and the high computational costs of fine-tuning. In this work, we propose a novel graph-based multimodal commonsense knowledge distillation framework that constructs a unified relational graph over commonsense knowledge, visual objects and questions through a Graph Convolutional Network (GCN) following a teacher-student environment. This proposed framework is flexible with any type of teacher and student models without further fine-tuning, and has achieved competitive performances on the ScienceQA dataset.
'No' Matters: Out-of-Distribution Detection in Multimodality Long Dialogue
Oct 31, 2024



Out-of-distribution (OOD) detection in multimodal contexts is essential for identifying deviations in combined inputs from different modalities, particularly in applications like open-domain dialogue systems or real-life dialogue interactions. This paper aims to improve the user experience that involves multi-round long dialogues by efficiently detecting OOD dialogues and images. We introduce a novel scoring framework named Dialogue Image Aligning and Enhancing Framework (DIAEF) that integrates the visual language models with the novel proposed scores that detect OOD in two key scenarios (1) mismatches between the dialogue and image input pair and (2) input pairs with previously unseen labels. Our experimental results, derived from various benchmarks, demonstrate that integrating image and multi-round dialogue OOD detection is more effective with previously unseen labels than using either modality independently. In the presence of mismatched pairs, our proposed score effectively identifies these mismatches and demonstrates strong robustness in long dialogues. This approach enhances domain-aware, adaptive conversational agents and establishes baselines for future studies.
3M-Health: Multimodal Multi-Teacher Knowledge Distillation for Mental Health Detection
Jul 12, 2024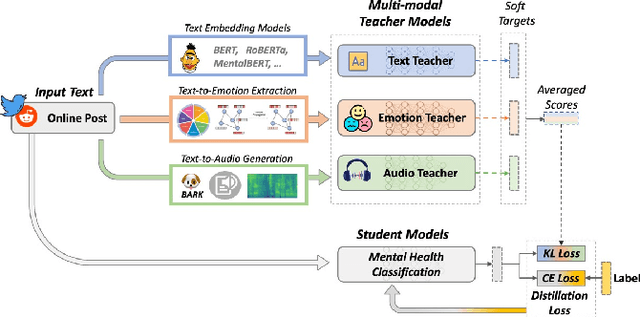
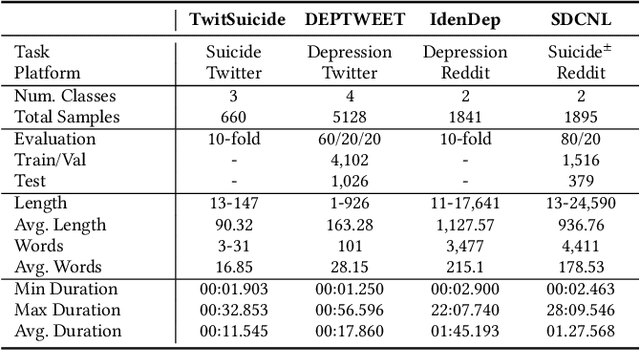
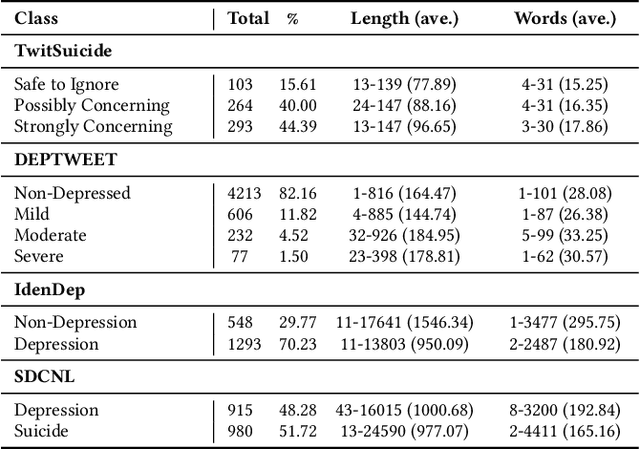
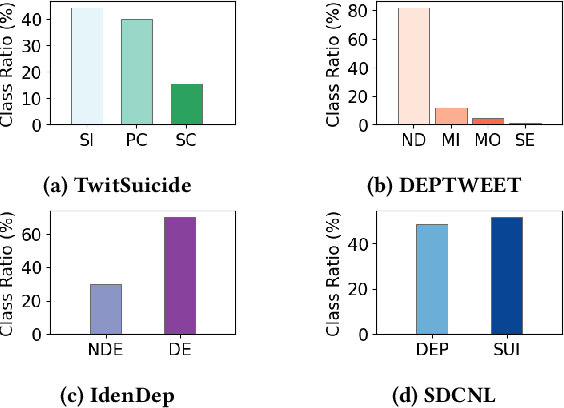
The significance of mental health classification is paramount in contemporary society, where digital platforms serve as crucial sources for monitoring individuals' well-being. However, existing social media mental health datasets primarily consist of text-only samples, potentially limiting the efficacy of models trained on such data. Recognising that humans utilise cross-modal information to comprehend complex situations or issues, we present a novel approach to address the limitations of current methodologies. In this work, we introduce a Multimodal and Multi-Teacher Knowledge Distillation model for Mental Health Classification, leveraging insights from cross-modal human understanding. Unlike conventional approaches that often rely on simple concatenation to integrate diverse features, our model addresses the challenge of appropriately representing inputs of varying natures (e.g., texts and sounds). To mitigate the computational complexity associated with integrating all features into a single model, we employ a multimodal and multi-teacher architecture. By distributing the learning process across multiple teachers, each specialising in a particular feature extraction aspect, we enhance the overall mental health classification performance. Through experimental validation, we demonstrate the efficacy of our model in achieving improved performance. All relevant codes will be made available upon publication.
PDF-MVQA: A Dataset for Multimodal Information Retrieval in-based Visual Question Answering
Apr 19, 2024



Document Question Answering (QA) presents a challenge in understanding visually-rich documents (VRD), particularly those dominated by lengthy textual content like research journal articles. Existing studies primarily focus on real-world documents with sparse text, while challenges persist in comprehending the hierarchical semantic relations among multiple pages to locate multimodal components. To address this gap, we propose PDF-MVQA, which is tailored for research journal articles, encompassing multiple pages and multimodal information retrieval. Unlike traditional machine reading comprehension (MRC) tasks, our approach aims to retrieve entire paragraphs containing answers or visually rich document entities like tables and figures. Our contributions include the introduction of a comprehensive PDF Document VQA dataset, allowing the examination of semantically hierarchical layout structures in text-dominant documents. We also present new VRD-QA frameworks designed to grasp textual contents and relations among document layouts simultaneously, extending page-level understanding to the entire multi-page document. Through this work, we aim to enhance the capabilities of existing vision-and-language models in handling challenges posed by text-dominant documents in VRD-QA.
Workshop on Document Intelligence Understanding
Jul 31, 2023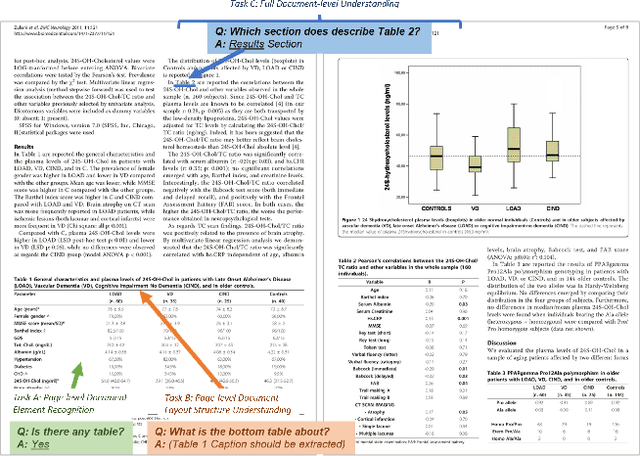


Document understanding and information extraction include different tasks to understand a document and extract valuable information automatically. Recently, there has been a rising demand for developing document understanding among different domains, including business, law, and medicine, to boost the efficiency of work that is associated with a large number of documents. This workshop aims to bring together researchers and industry developers in the field of document intelligence and understanding diverse document types to boost automatic document processing and understanding techniques. We also released a data challenge on the recently introduced document-level VQA dataset, PDFVQA. The PDFVQA challenge examines the structural and contextual understandings of proposed models on the natural full document level of multiple consecutive document pages by including questions with a sequence of answers extracted from multi-pages of the full document. This task helps to boost the document understanding step from the single-page level to the full document level understanding.
PDFVQA: A New Dataset for Real-World VQA on Documents
Apr 24, 2023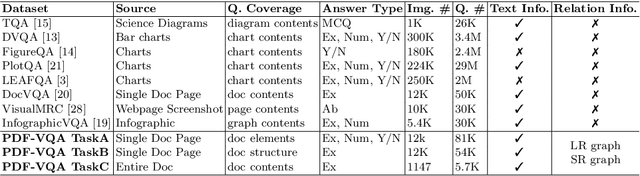
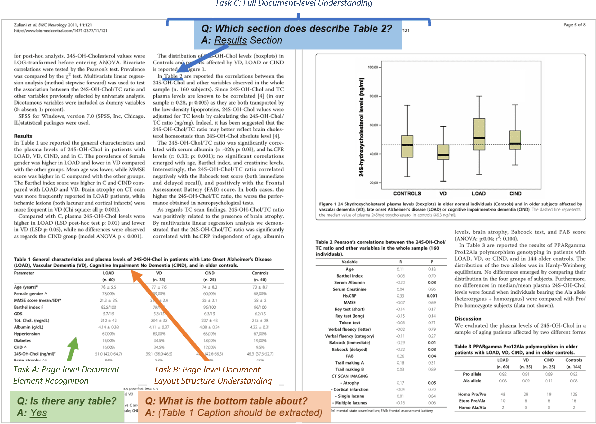
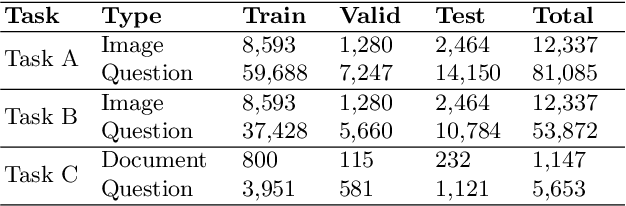
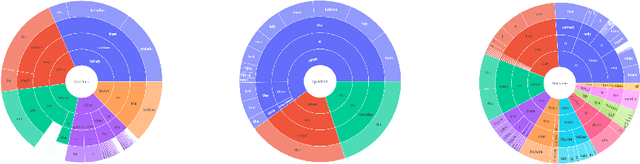
Document-based Visual Question Answering examines the document understanding of document images in conditions of natural language questions. We proposed a new document-based VQA dataset, PDF-VQA, to comprehensively examine the document understanding from various aspects, including document element recognition, document layout structural understanding as well as contextual understanding and key information extraction. Our PDF-VQA dataset extends the current scale of document understanding that limits on the single document page to the new scale that asks questions over the full document of multiple pages. We also propose a new graph-based VQA model that explicitly integrates the spatial and hierarchically structural relationships between different document elements to boost the document structural understanding. The performances are compared with several baselines over different question types and tasks\footnote{The full dataset will be released after paper acceptance.
SceneGATE: Scene-Graph based co-Attention networks for TExt visual question answering
Dec 16, 2022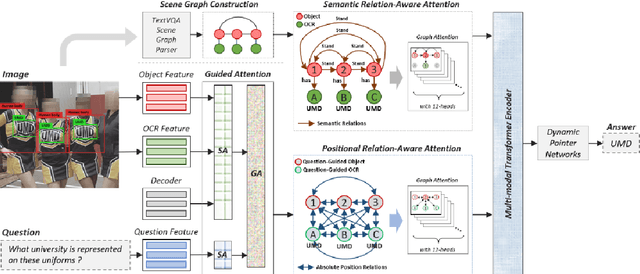
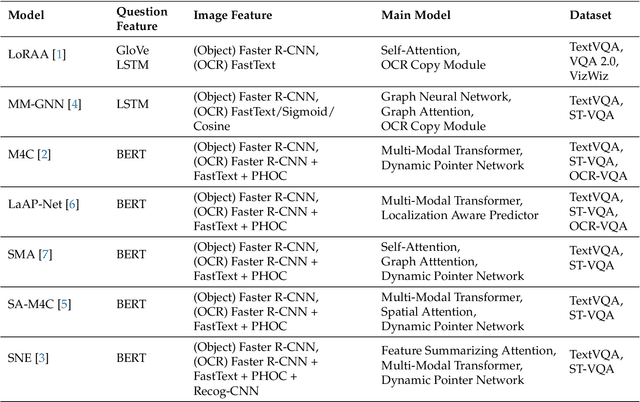

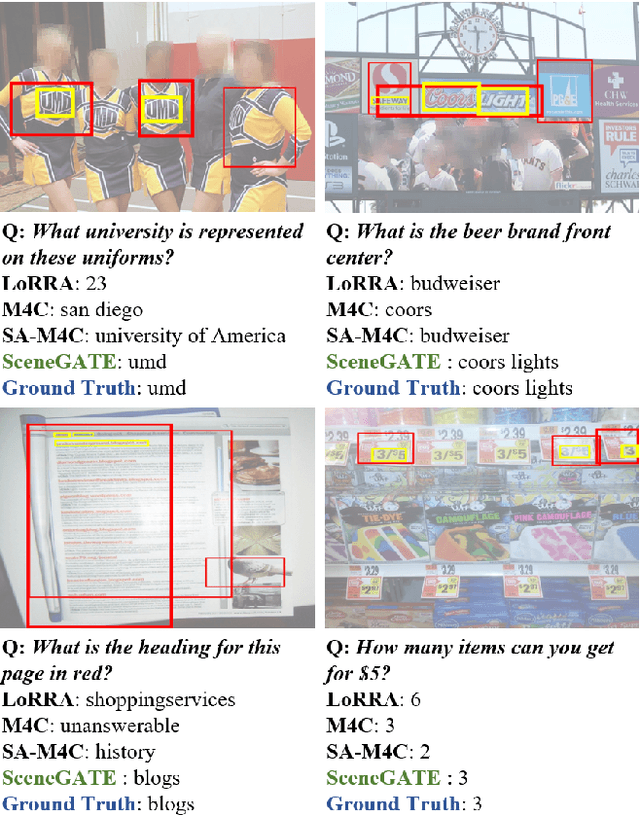
Most TextVQA approaches focus on the integration of objects, scene texts and question words by a simple transformer encoder. But this fails to capture the semantic relations between different modalities. The paper proposes a Scene Graph based co-Attention Network (SceneGATE) for TextVQA, which reveals the semantic relations among the objects, Optical Character Recognition (OCR) tokens and the question words. It is achieved by a TextVQA-based scene graph that discovers the underlying semantics of an image. We created a guided-attention module to capture the intra-modal interplay between the language and the vision as a guidance for inter-modal interactions. To make explicit teaching of the relations between the two modalities, we proposed and integrated two attention modules, namely a scene graph-based semantic relation-aware attention and a positional relation-aware attention. We conducted extensive experiments on two benchmark datasets, Text-VQA and ST-VQA. It is shown that our SceneGATE method outperformed existing ones because of the scene graph and its attention modules.
PiggyBack: Pretrained Visual Question Answering Environment for Backing up Non-deep Learning Professionals
Dec 01, 2022


We propose a PiggyBack, a Visual Question Answering platform that allows users to apply the state-of-the-art visual-language pretrained models easily. The PiggyBack supports the full stack of visual question answering tasks, specifically data processing, model fine-tuning, and result visualisation. We integrate visual-language models, pretrained by HuggingFace, an open-source API platform of deep learning technologies; however, it cannot be runnable without programming skills or deep learning understanding. Hence, our PiggyBack supports an easy-to-use browser-based user interface with several deep learning visual language pretrained models for general users and domain experts. The PiggyBack includes the following benefits: Free availability under the MIT License, Portability due to web-based and thus runs on almost any platform, A comprehensive data creation and processing technique, and ease of use on deep learning-based visual language pretrained models. The demo video is available on YouTube and can be found at https://youtu.be/iz44RZ1lF4s.
Doc-GCN: Heterogeneous Graph Convolutional Networks for Document Layout Analysis
Aug 22, 2022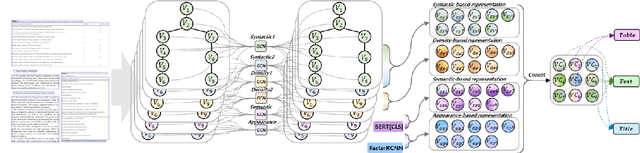


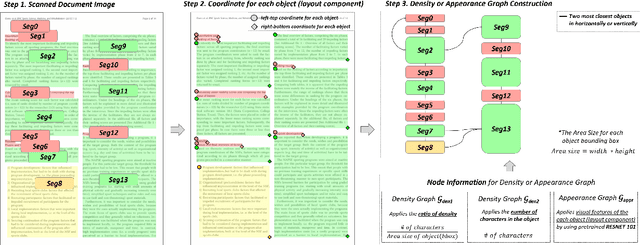
Recognizing the layout of unstructured digital documents is crucial when parsing the documents into the structured, machine-readable format for downstream applications. Recent studies in Document Layout Analysis usually rely on computer vision models to understand documents while ignoring other information, such as context information or relation of document components, which are vital to capture. Our Doc-GCN presents an effective way to harmonize and integrate heterogeneous aspects for Document Layout Analysis. We first construct graphs to explicitly describe four main aspects, including syntactic, semantic, density, and appearance/visual information. Then, we apply graph convolutional networks for representing each aspect of information and use pooling to integrate them. Finally, we aggregate each aspect and feed them into 2-layer MLPs for document layout component classification. Our Doc-GCN achieves new state-of-the-art results in three widely used DLA datasets.