 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneGATE: Scene-Graph based co-Attention networks for TExt visual question answering
Dec 16, 2022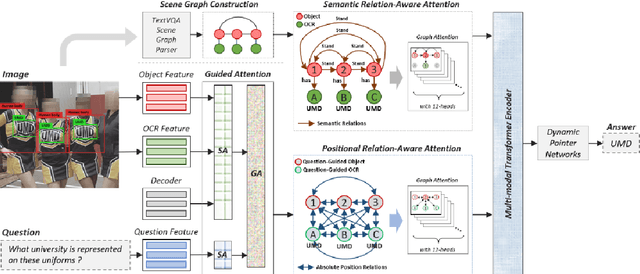
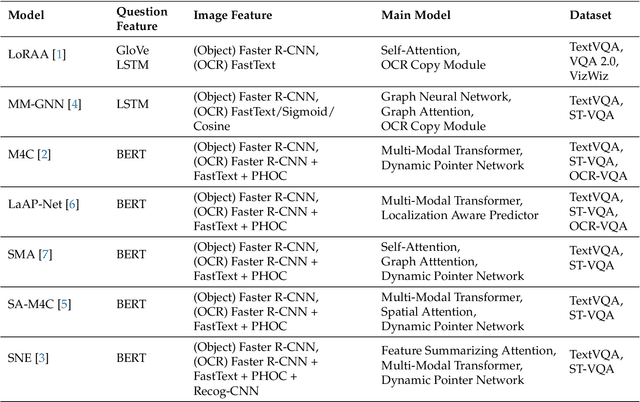

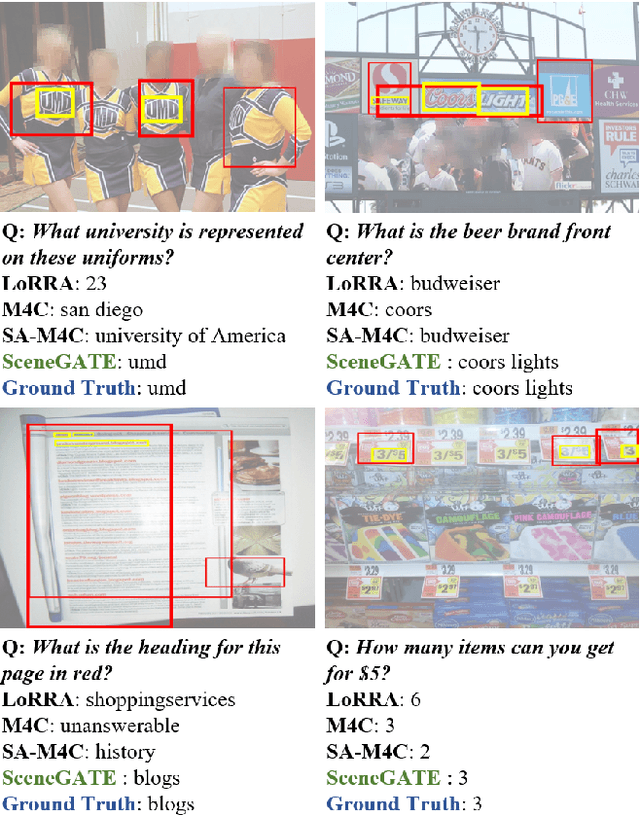
Most TextVQA approaches focus on the integration of objects, scene texts and question words by a simple transformer encoder. But this fails to capture the semantic relations between different modalities. The paper proposes a Scene Graph based co-Attention Network (SceneGATE) for TextVQA, which reveals the semantic relations among the objects, Optical Character Recognition (OCR) tokens and the question words. It is achieved by a TextVQA-based scene graph that discovers the underlying semantics of an image. We created a guided-attention module to capture the intra-modal interplay between the language and the vision as a guidance for inter-modal interactions. To make explicit teaching of the relations between the two modalities, we proposed and integrated two attention modules, namely a scene graph-based semantic relation-aware attention and a positional relation-aware attention. We conducted extensive experiments on two benchmark datasets, Text-VQA and ST-VQA. It is shown that our SceneGATE method outperformed existing ones because of the scene graph and its attention modules.