 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFiLoRA: Focus-and-Ignore LoRA for Controllable Feature Reliance
Feb 02, 2026Multimodal foundation models integrate heterogeneous signals across modalities, yet it remains poorly understood how their predictions depend on specific internal feature groups and whether such reliance can be deliberately controlled. Existing studies of shortcut and spurious behavior largely rely on post hoc analyses or feature removal, offering limited insight into whether reliance can be modulated without altering task semantics. We introduce FiLoRA (Focus-and-Ignore LoRA), an instruction-conditioned, parameter-efficient adaptation framework that enables explicit control over internal feature reliance while keeping the predictive objective fixed. FiLoRA decomposes adaptation into feature group-aligned LoRA modules and applies instruction-conditioned gating, allowing natural language instructions to act as computation-level control signals rather than task redefinitions. Across text--image and audio--visual benchmarks, we show that instruction-conditioned gating induces consistent and causal shifts in internal computation, selectively amplifying or suppressing core and spurious feature groups without modifying the label space or training objective. Further analyses demonstrate that FiLoRA yields improved robustness under spurious feature interventions, revealing a principled mechanism to regulate reliance beyond correlation-driven learning.
'No' Matters: Out-of-Distribution Detection in Multimodality Long Dialogue
Oct 31, 2024



Out-of-distribution (OOD) detection in multimodal contexts is essential for identifying deviations in combined inputs from different modalities, particularly in applications like open-domain dialogue systems or real-life dialogue interactions. This paper aims to improve the user experience that involves multi-round long dialogues by efficiently detecting OOD dialogues and images. We introduce a novel scoring framework named Dialogue Image Aligning and Enhancing Framework (DIAEF) that integrates the visual language models with the novel proposed scores that detect OOD in two key scenarios (1) mismatches between the dialogue and image input pair and (2) input pairs with previously unseen labels. Our experimental results, derived from various benchmarks, demonstrate that integrating image and multi-round dialogue OOD detection is more effective with previously unseen labels than using either modality independently. In the presence of mismatched pairs, our proposed score effectively identifies these mismatches and demonstrates strong robustness in long dialogues. This approach enhances domain-aware, adaptive conversational agents and establishes baselines for future studies.
ChuLo: Chunk-Level Key Information Representation for Long Document Processing
Oct 14, 2024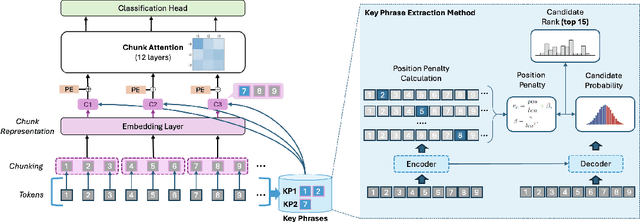
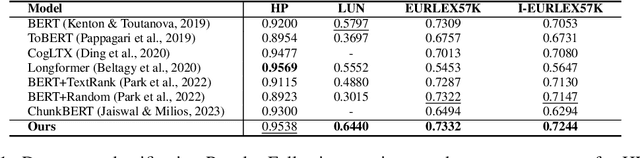
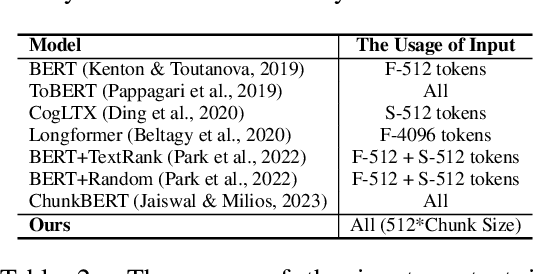
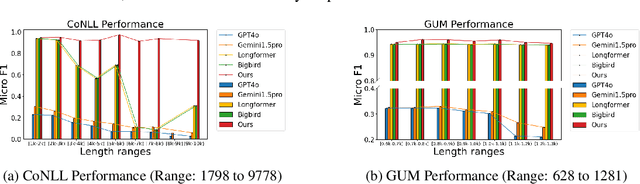
Transformer-based models have achieved remarkable success in various Natural Language Processing (NLP) tasks, yet their ability to handle long documents is constrained by computational limitations. Traditional approaches, such as truncating inputs, sparse self-attention, and chunking, attempt to mitigate these issues, but they often lead to information loss and hinder the model's ability to capture long-range dependencies. In this paper, we introduce ChuLo, a novel chunk representation method for long document classification that addresses these limitations. Our ChuLo groups input tokens using unsupervised keyphrase extraction, emphasizing semantically important keyphrase based chunk to retain core document content while reducing input length. This approach minimizes information loss and improves the efficiency of Transformer-based models. Preserving all tokens in long document understanding, especially token classification tasks, is especially important to ensure that fine-grained annotations, which depend on the entire sequence context, are not lost. We evaluate our method on multiple long document classification tasks and long document token classification tasks, demonstrating its effectiveness through comprehensive qualitative and quantitative analyses.
GEM-VPC: A dual Graph-Enhanced Multimodal integration for Video Paragraph Captioning
Oct 12, 2024



Video Paragraph Captioning (VPC) aims to generate paragraph captions that summarises key events within a video. Despite recent advancements, challenges persist, notably in effectively utilising multimodal signals inherent in videos and addressing the long-tail distribution of words. The paper introduces a novel multimodal integrated caption generation framework for VPC that leverages information from various modalities and external knowledge bases. Our framework constructs two graphs: a 'video-specific' temporal graph capturing major events and interactions between multimodal information and commonsense knowledge, and a 'theme graph' representing correlations between words of a specific theme. These graphs serve as input for a transformer network with a shared encoder-decoder architecture. We also introduce a node selection module to enhance decoding efficiency by selecting the most relevant nodes from the graphs. Our results demonstrate superior performance across benchmark datasets.
Text-guided 3D Human Motion Generation with Keyframe-based Parallel Skip Transformer
May 24, 2024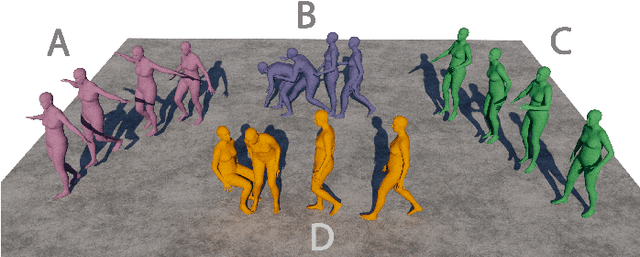

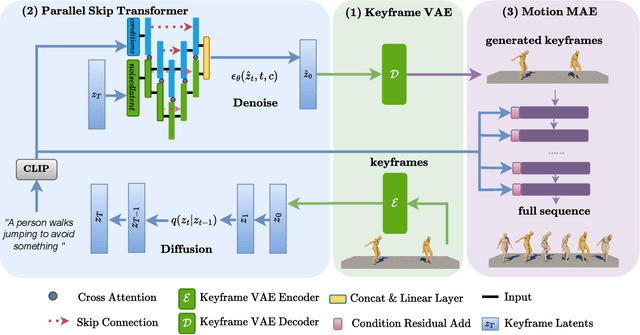
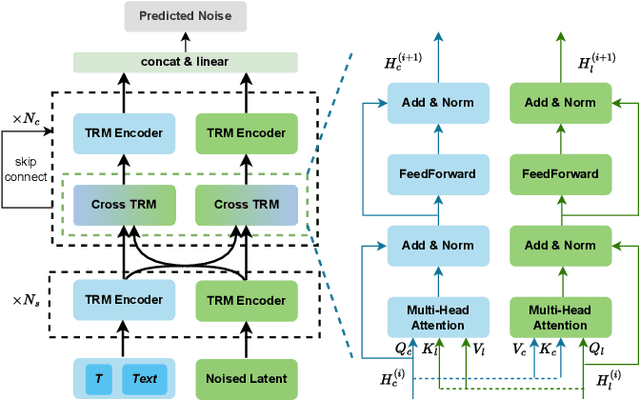
Text-driven human motion generation is an emerging task in animation and humanoid robot design. Existing algorithms directly generate the full sequence which is computationally expensive and prone to errors as it does not pay special attention to key poses, a process that has been the cornerstone of animation for decades. We propose KeyMotion, that generates plausible human motion sequences corresponding to input text by first generating keyframes followed by in-filling. We use a Variational Autoencoder (VAE) with Kullback-Leibler regularization to project the keyframes into a latent space to reduce dimensionality and further accelerate the subsequent diffusion process. For the reverse diffusion, we propose a novel Parallel Skip Transformer that performs cross-modal attention between the keyframe latents and text condition. To complete the motion sequence, we propose a text-guided Transformer designed to perform motion-in-filling, ensuring the preservation of both fidelity and adherence to the physical constraints of human motion. Experiments show that our method achieves state-of-theart results on the HumanML3D dataset outperforming others on all R-precision metrics and MultiModal Distance. KeyMotion also achieves competitive performance on the KIT dataset, achieving the best results on Top3 R-precision, FID, and Diversity metrics.
Game-MUG: Multimodal Oriented Game Situation Understanding and Commentary Generation Dataset
Apr 30, 2024
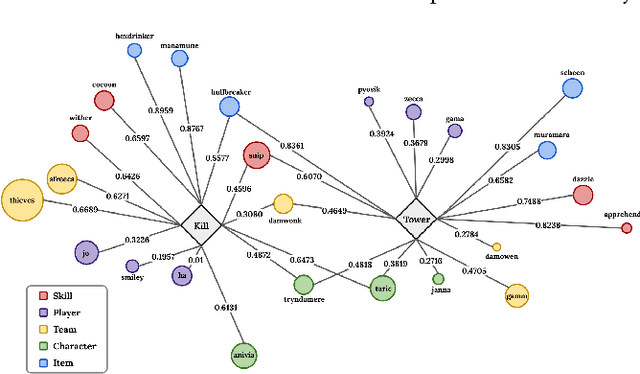
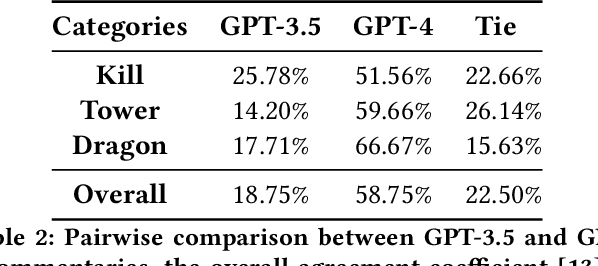
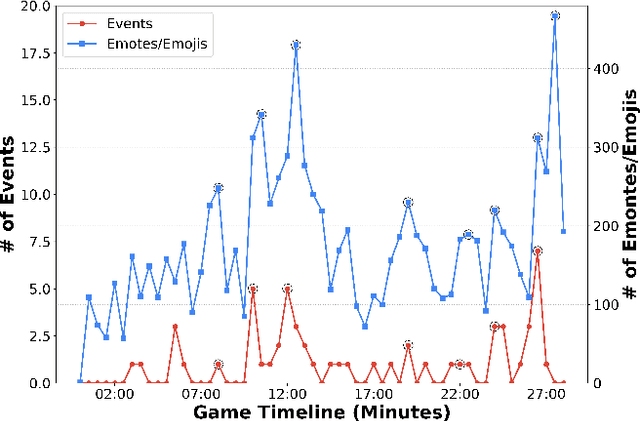
The dynamic nature of esports makes the situation relatively complicated for average viewers. Esports broadcasting involves game expert casters, but the caster-dependent game commentary is not enough to fully understand the game situation. It will be richer by including diverse multimodal esports information, including audiences' talks/emotions, game audio, and game match event information. This paper introduces GAME-MUG, a new multimodal game situation understanding and audience-engaged commentary generation dataset and its strong baseline. Our dataset is collected from 2020-2022 LOL game live streams from YouTube and Twitch, and includes multimodal esports game information, including text, audio, and time-series event logs, for detecting the game situation. In addition, we also propose a new audience conversation augmented commentary dataset by covering the game situation and audience conversation understanding, and introducing a robust joint multimodal dual learning model as a baseline. We examine the model's game situation/event understanding ability and commentary generation capability to show the effectiveness of the multimodal aspects coverage and the joint integration learning approach.
PEACH: Pretrained-embedding Explanation Across Contextual and Hierarchical Structure
Apr 21, 2024In this work, we propose a novel tree-based explanation technique, PEACH (Pretrained-embedding Explanation Across Contextual and Hierarchical Structure), that can explain how text-based documents are classified by using any pretrained contextual embeddings in a tree-based human-interpretable manner. Note that PEACH can adopt any contextual embeddings of the PLMs as a training input for the decision tree. Using the proposed PEACH, we perform a comprehensive analysis of several contextual embeddings on nine different NLP text classification benchmarks. This analysis demonstrates the flexibility of the model by applying several PLM contextual embeddings, its attribute selections, scaling, and clustering methods. Furthermore, we show the utility of explanations by visualising the feature selection and important trend of text classification via human-interpretable word-cloud-based trees, which clearly identify model mistakes and assist in dataset debugging. Besides interpretability, PEACH outperforms or is similar to those from pretrained models.
M3-VRD: Multimodal Multi-task Multi-teacher Visually-Rich Form Document Understanding
Feb 28, 2024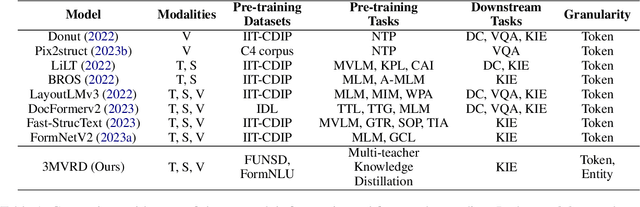
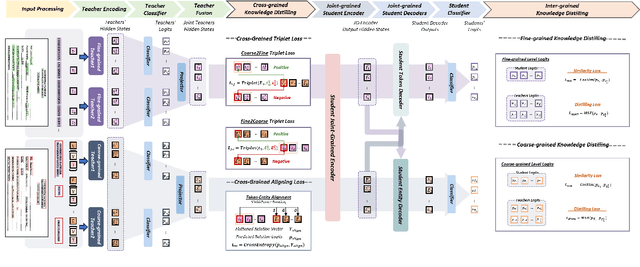
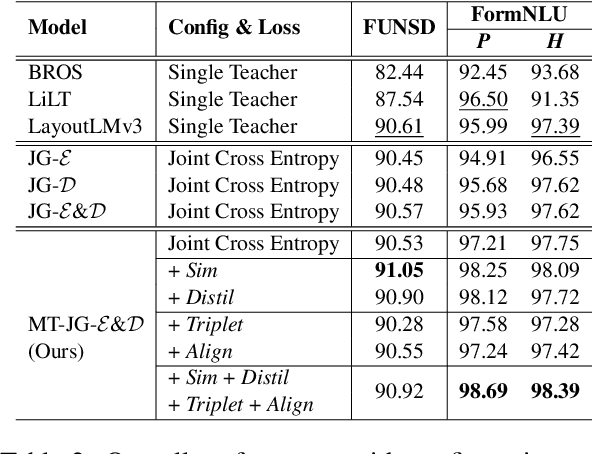
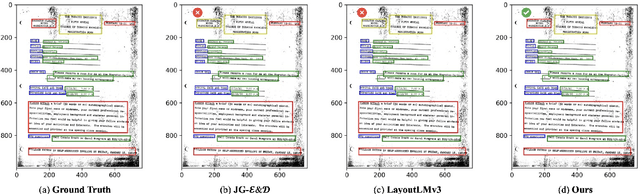
This paper presents a groundbreaking multimodal, multi-task, multi-teacher joint-grained knowledge distillation model for visually-rich form document understanding. The model is designed to leverage insights from both fine-grained and coarse-grained levels by facilitating a nuanced correlation between token and entity representations, addressing the complexities inherent in form documents. Additionally, we introduce new inter-grained and cross-grained loss functions to further refine diverse multi-teacher knowledge distillation transfer process, presenting distribution gaps and a harmonised understanding of form documents. Through a comprehensive evaluation across publicly available form document understanding datasets, our proposed model consistently outperforms existing baselines, showcasing its efficacy in handling the intricate structures and content of visually complex form documents.
SceneGATE: Scene-Graph based co-Attention networks for TExt visual question answering
Dec 16, 2022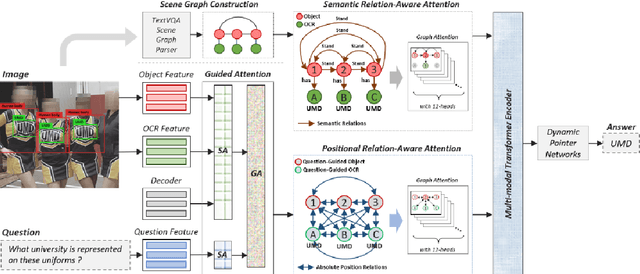

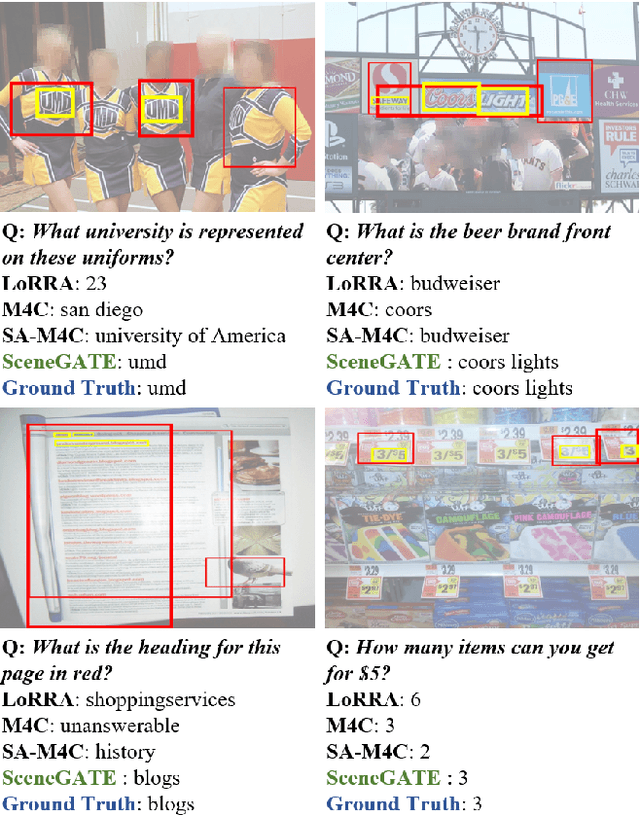
Most TextVQA approaches focus on the integration of objects, scene texts and question words by a simple transformer encoder. But this fails to capture the semantic relations between different modalities. The paper proposes a Scene Graph based co-Attention Network (SceneGATE) for TextVQA, which reveals the semantic relations among the objects, Optical Character Recognition (OCR) tokens and the question words. It is achieved by a TextVQA-based scene graph that discovers the underlying semantics of an image. We created a guided-attention module to capture the intra-modal interplay between the language and the vision as a guidance for inter-modal interactions. To make explicit teaching of the relations between the two modalities, we proposed and integrated two attention modules, namely a scene graph-based semantic relation-aware attention and a positional relation-aware attention. We conducted extensive experiments on two benchmark datasets, Text-VQA and ST-VQA. It is shown that our SceneGATE method outperformed existing ones because of the scene graph and its attention modules.
An Analysis of Deep Reinforcement Learning Agents for Text-based Games
Sep 12, 2022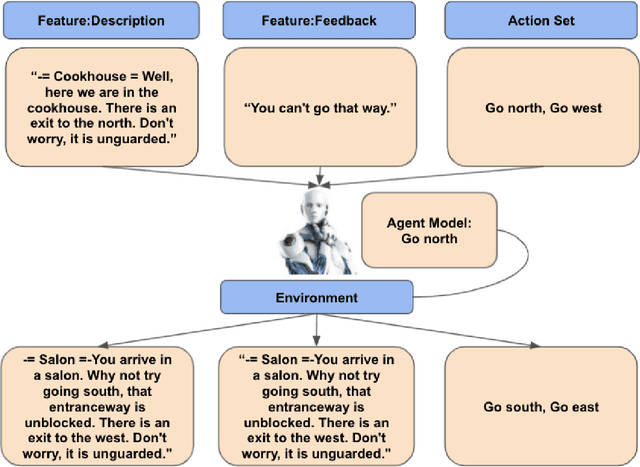
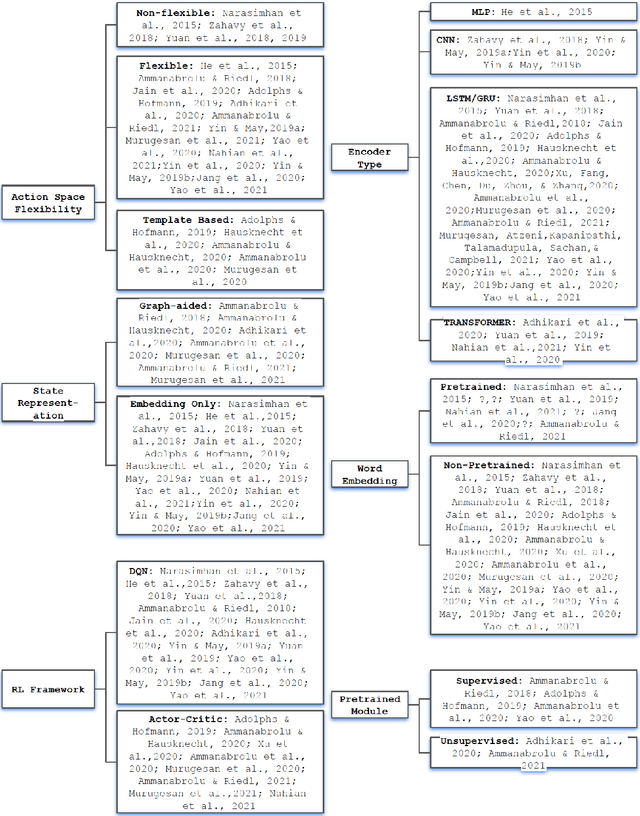
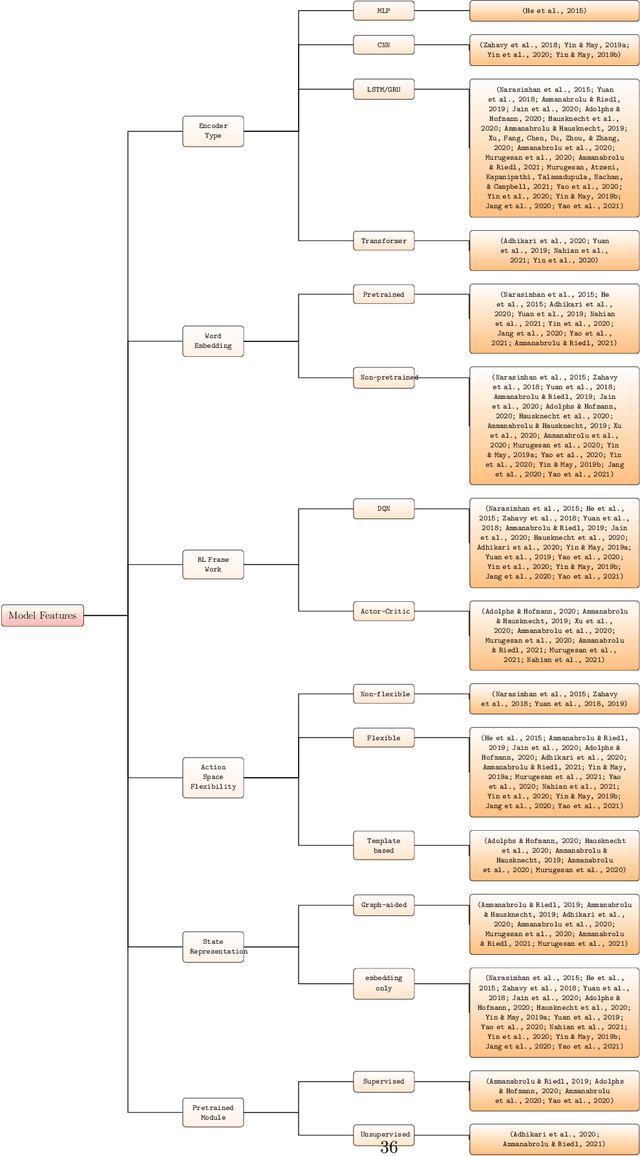
Text-based games(TBG) are complex environments which allow users or computer agents to make textual interactions and achieve game goals.In TBG agent design and training process, balancing the efficiency and performance of the agent models is a major challenge. Finding TBG agent deep learning modules' performance in standardized environments, and testing their performance among different evaluation types is also important for TBG agent research. We constructed a standardized TBG agent with no hand-crafted rules, formally categorized TBG evaluation types, and analyzed selected methods in our environment.