 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGame-MUG: Multimodal Oriented Game Situation Understanding and Commentary Generation Dataset
Apr 30, 2024
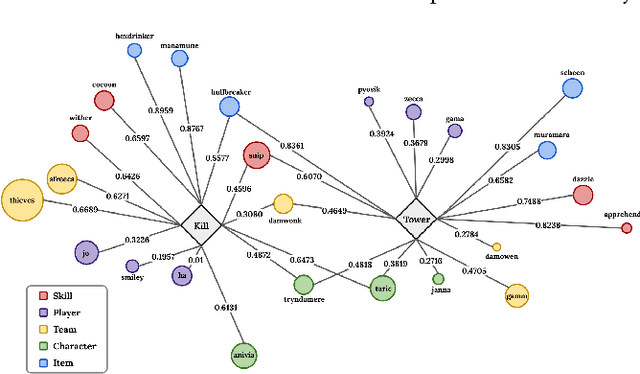
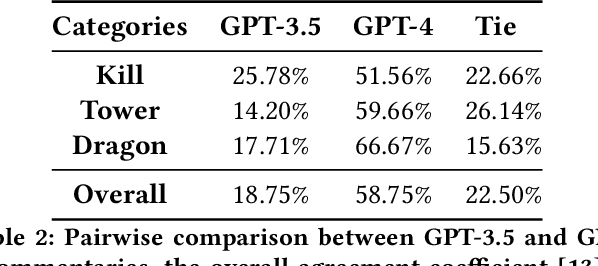
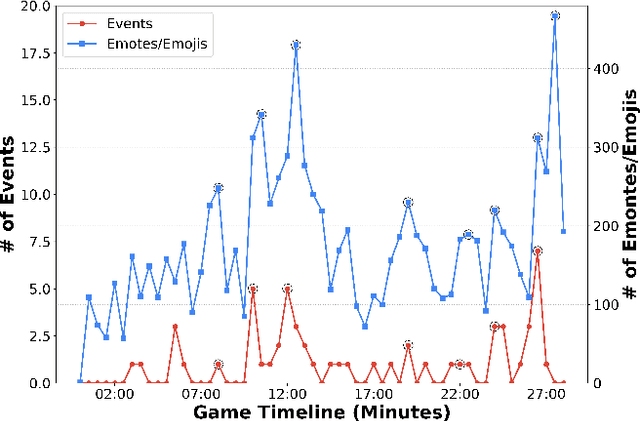
The dynamic nature of esports makes the situation relatively complicated for average viewers. Esports broadcasting involves game expert casters, but the caster-dependent game commentary is not enough to fully understand the game situation. It will be richer by including diverse multimodal esports information, including audiences' talks/emotions, game audio, and game match event information. This paper introduces GAME-MUG, a new multimodal game situation understanding and audience-engaged commentary generation dataset and its strong baseline. Our dataset is collected from 2020-2022 LOL game live streams from YouTube and Twitch, and includes multimodal esports game information, including text, audio, and time-series event logs, for detecting the game situation. In addition, we also propose a new audience conversation augmented commentary dataset by covering the game situation and audience conversation understanding, and introducing a robust joint multimodal dual learning model as a baseline. We examine the model's game situation/event understanding ability and commentary generation capability to show the effectiveness of the multimodal aspects coverage and the joint integration learning approach.
MCAD: Multi-teacher Cross-modal Alignment Distillation for efficient image-text retrieval
Oct 30, 2023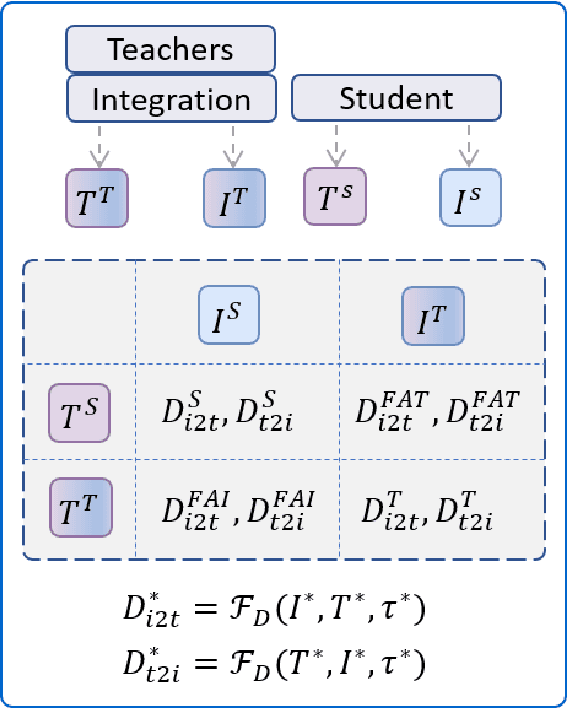
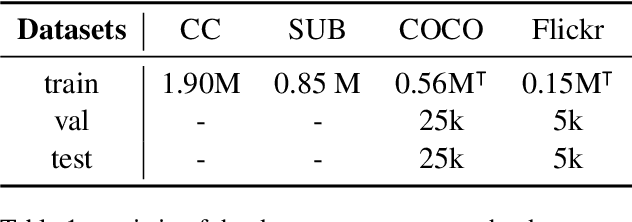
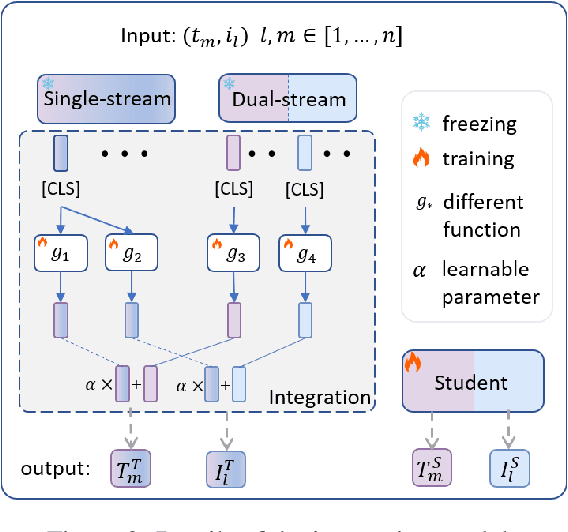
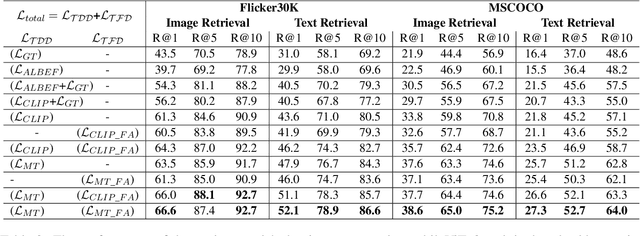
With the success of large-scale visual-language pretraining models and the wide application of image-text retrieval in industry areas, reducing the model size and streamlining their terminal-device deployment have become urgently necessary. The mainstream model structures for image-text retrieval are single-stream and dual-stream, both aiming to close the semantic gap between visual and textual modalities. Dual-stream models excel at offline indexing and fast inference, while single-stream models achieve more accurate cross-model alignment by employing adequate feature fusion. We propose a multi-teacher cross-modality alignment distillation (MCAD) technique to integrate the advantages of single-stream and dual-stream models. By incorporating the fused single-stream features into the image and text features of the dual-stream model, we formulate new modified teacher features and logits. Then, we conduct both logit and feature distillation to boost the capability of the student dual-stream model, achieving high retrieval performance without increasing inference complexity. Extensive experiments demonstrate the remarkable performance and high efficiency of MCAD on image-text retrieval tasks. Furthermore, we implement a mobile CLIP model on Snapdragon clips with only 93M running memory and 30ms search latency, without apparent performance degradation of the original large CLIP.