 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Task Performance with Interpretable Models via Sparse Auto-Encoders
Jul 08, 2025



Large Language Models (LLMs) are traditionally viewed as black-box algorithms, therefore reducing trustworthiness and obscuring potential approaches to increasing performance on downstream tasks. In this work, we apply an effective LLM decomposition method using a dictionary-learning approach with sparse autoencoders. This helps extract monosemantic features from polysemantic LLM neurons. Remarkably, our work identifies model-internal misunderstanding, allowing the automatic reformulation of the prompts with additional annotations to improve the interpretation by LLMs. Moreover, this approach demonstrates a significant performance improvement in downstream tasks, such as mathematical reasoning and metaphor detection.
MCAD: Multi-teacher Cross-modal Alignment Distillation for efficient image-text retrieval
Oct 30, 2023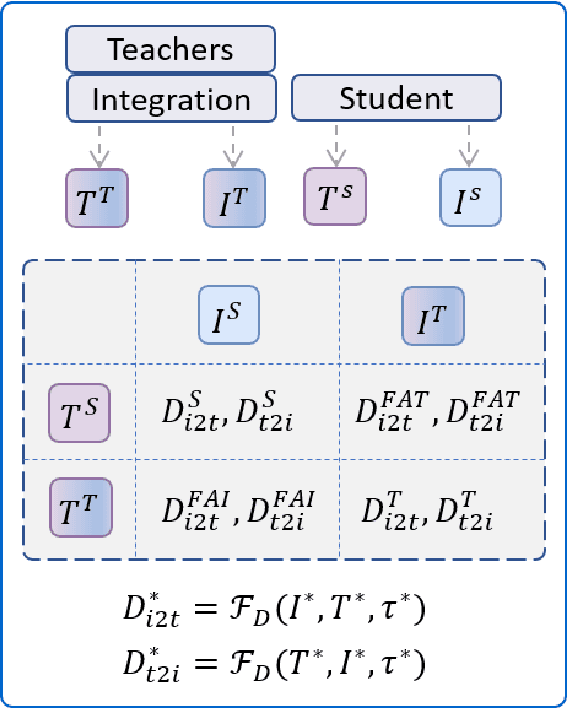
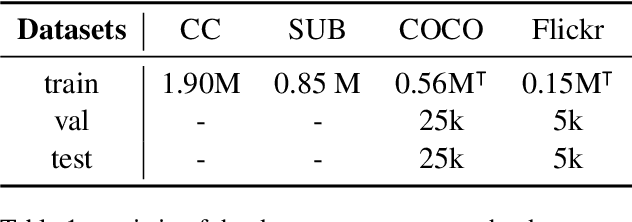
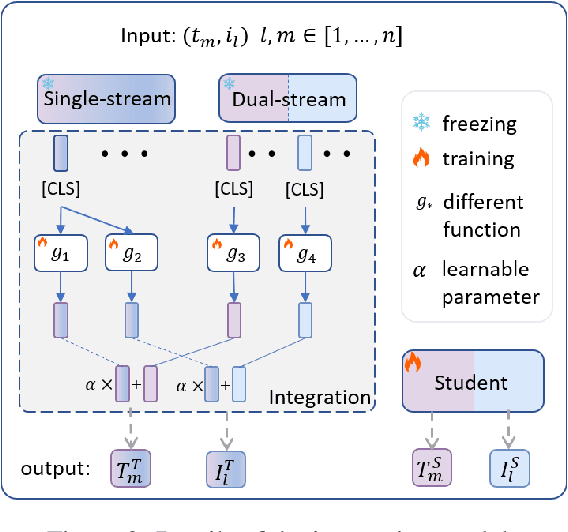
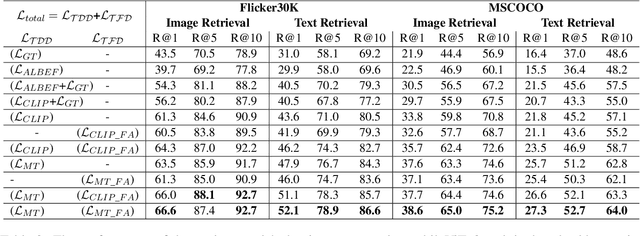
With the success of large-scale visual-language pretraining models and the wide application of image-text retrieval in industry areas, reducing the model size and streamlining their terminal-device deployment have become urgently necessary. The mainstream model structures for image-text retrieval are single-stream and dual-stream, both aiming to close the semantic gap between visual and textual modalities. Dual-stream models excel at offline indexing and fast inference, while single-stream models achieve more accurate cross-model alignment by employing adequate feature fusion. We propose a multi-teacher cross-modality alignment distillation (MCAD) technique to integrate the advantages of single-stream and dual-stream models. By incorporating the fused single-stream features into the image and text features of the dual-stream model, we formulate new modified teacher features and logits. Then, we conduct both logit and feature distillation to boost the capability of the student dual-stream model, achieving high retrieval performance without increasing inference complexity. Extensive experiments demonstrate the remarkable performance and high efficiency of MCAD on image-text retrieval tasks. Furthermore, we implement a mobile CLIP model on Snapdragon clips with only 93M running memory and 30ms search latency, without apparent performance degradation of the original large CLIP.
Prompt Space Optimizing Few-shot Reasoning Success with Large Language Models
Jun 06, 2023Prompt engineering is an essential technique for enhancing the abilities of large language models (LLMs) by providing explicit and specific instructions. It enables LLMs to excel in various tasks, such as arithmetic reasoning, question answering, summarization, relation extraction, machine translation, and sentiment analysis. Researchers have been actively exploring different prompt engineering strategies, such as Chain of Thought (CoT), Zero-CoT, and In-context learning. However, an unresolved problem arises from the fact that current approaches lack a solid theoretical foundation for determining optimal prompts. To address this issue in prompt engineering, we propose a new and effective approach called Prompt Space. Our methodology utilizes text embeddings to obtain basis vectors by matrix decomposition, and then constructs a space for representing all prompts. Prompt Space significantly outperforms state-of-the-art prompt paradigms on ten public reasoning benchmarks. Notably, without the help of the CoT method and the prompt "Let's think step by step", Prompt Space shows superior performance over the few-shot method. Overall, our approach provides a robust and fundamental theoretical framework for selecting simple and effective prompts. This advancement marks a significant step towards improving prompt engineering for a wide variety of applications in LLMs.