 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCAD: Multi-teacher Cross-modal Alignment Distillation for efficient image-text retrieval
Oct 30, 2023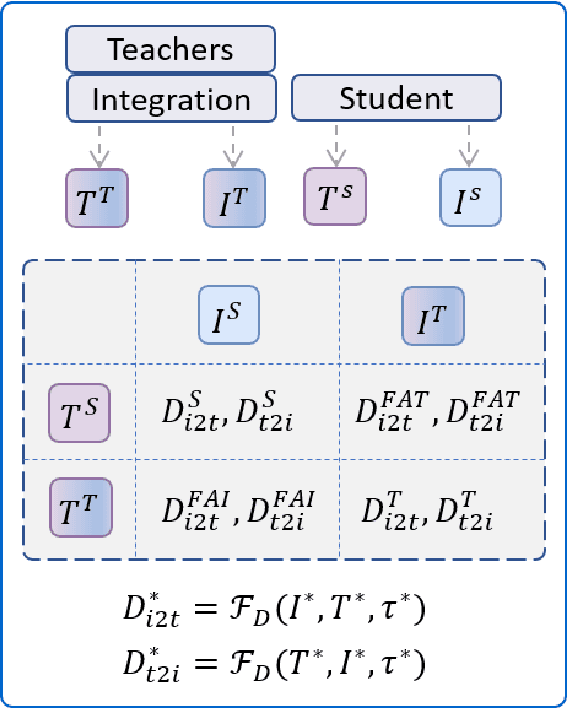
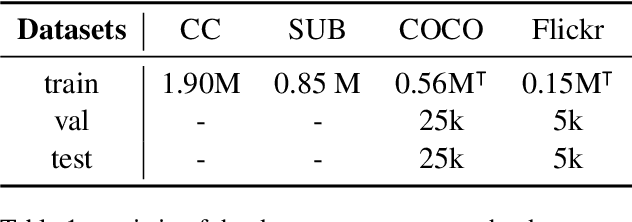
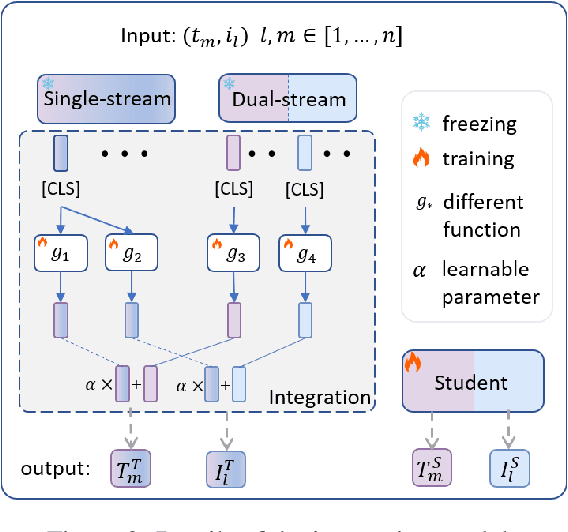
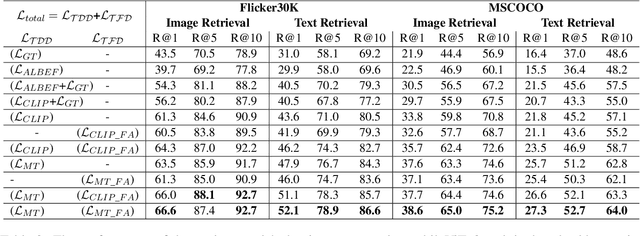
With the success of large-scale visual-language pretraining models and the wide application of image-text retrieval in industry areas, reducing the model size and streamlining their terminal-device deployment have become urgently necessary. The mainstream model structures for image-text retrieval are single-stream and dual-stream, both aiming to close the semantic gap between visual and textual modalities. Dual-stream models excel at offline indexing and fast inference, while single-stream models achieve more accurate cross-model alignment by employing adequate feature fusion. We propose a multi-teacher cross-modality alignment distillation (MCAD) technique to integrate the advantages of single-stream and dual-stream models. By incorporating the fused single-stream features into the image and text features of the dual-stream model, we formulate new modified teacher features and logits. Then, we conduct both logit and feature distillation to boost the capability of the student dual-stream model, achieving high retrieval performance without increasing inference complexity. Extensive experiments demonstrate the remarkable performance and high efficiency of MCAD on image-text retrieval tasks. Furthermore, we implement a mobile CLIP model on Snapdragon clips with only 93M running memory and 30ms search latency, without apparent performance degradation of the original large CLIP.
Edit Everything: A Text-Guided Generative System for Images Editing
Apr 27, 2023



We introduce a new generative system called Edit Everything, which can take image and text inputs and produce image outputs. Edit Everything allows users to edit images using simple text instructions. Our system designs prompts to guide the visual module in generating requested images. Experiments demonstrate that Edit Everything facilitates the implementation of the visual aspects of Stable Diffusion with the use of Segment Anything model and CLIP. Our system is publicly available at https://github.com/DefengXie/Edit_Everything.
Combining Improvements for Exploiting Dependency Trees in Neural Semantic Parsing
Dec 25, 2021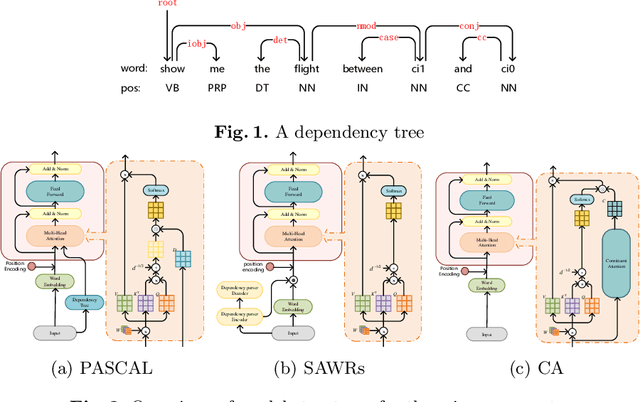
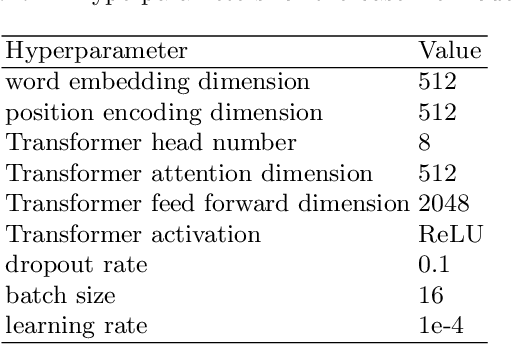
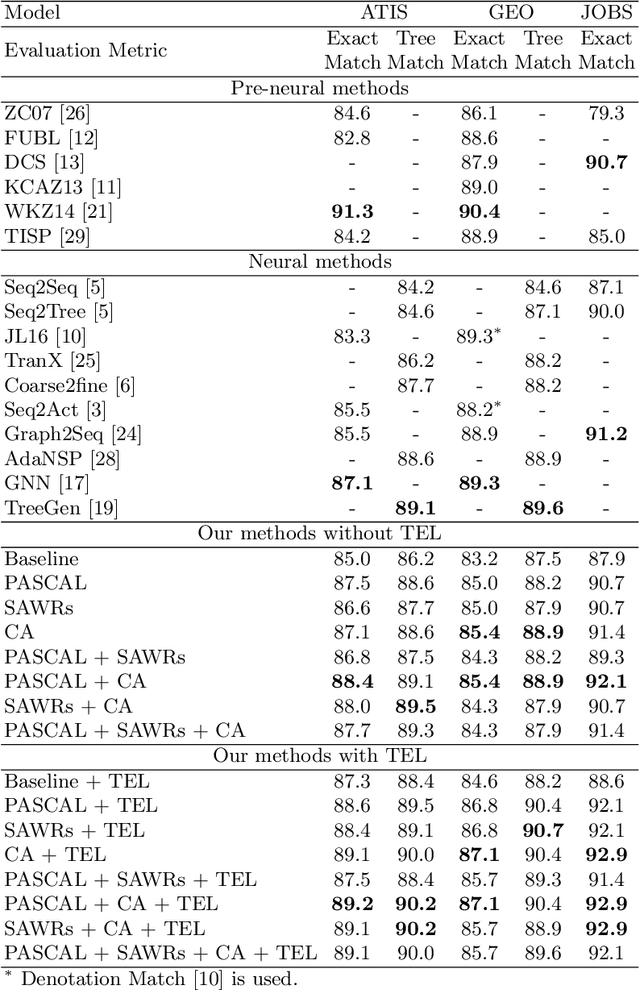
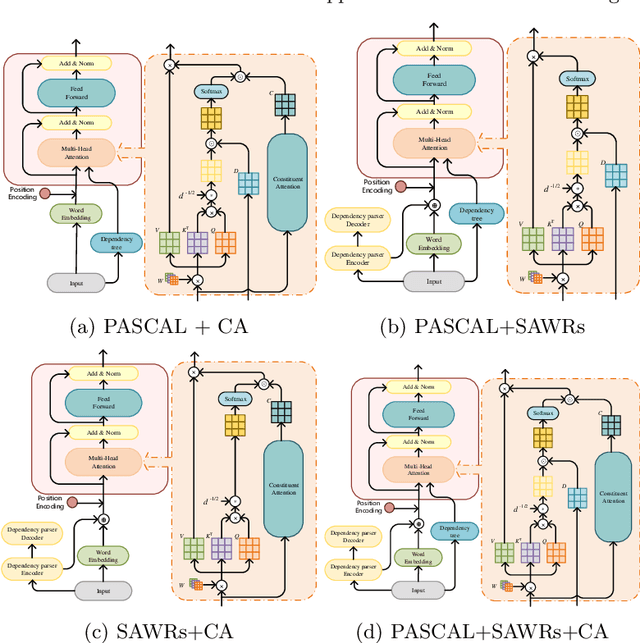
The dependency tree of a natural language sentence can capture the interactions between semantics and words. However, it is unclear whether those methods which exploit such dependency information for semantic parsing can be combined to achieve further improvement and the relationship of those methods when they combine. In this paper, we examine three methods to incorporate such dependency information in a Transformer based semantic parser and empirically study their combinations. We first replace standard self-attention heads in the encoder with parent-scaled self-attention (PASCAL) heads, i.e., the ones that can attend to the dependency parent of each token. Then we concatenate syntax-aware word representations (SAWRs), i.e., the intermediate hidden representations of a neural dependency parser, with ordinary word embedding to enhance the encoder. Later, we insert the constituent attention (CA) module to the encoder, which adds an extra constraint to attention heads that can better capture the inherent dependency structure of input sentences. Transductive ensemble learning (TEL) is used for model aggregation, and an ablation study is conducted to show the contribution of each method. Our experiments show that CA is complementary to PASCAL or SAWRs, and PASCAL + CA provides state-of-the-art performance among neural approaches on ATIS, GEO, and JOBS.