 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Prompt itself: the Hierarchical Attribution Prompt Optimization
Jan 06, 2026Optimization is fundamental across numerous disciplines, typically following an iterative process of refining an initial solution to enhance performance. This principle is equally critical in prompt engineering, where designing effective prompts for large language models constitutes a complex optimization challenge. A structured optimization approach requires automated or semi-automated procedures to develop improved prompts, thereby reducing manual effort, improving performance, and yielding an interpretable process. However, current prompt optimization methods often induce prompt drift, where new prompts fix prior failures but impair performance on previously successful tasks. Additionally, generating prompts from scratch can compromise interpretability. To address these limitations, this study proposes the Hierarchical Attribution Prompt Optimization (HAPO) framework, which introduces three innovations: (1) a dynamic attribution mechanism targeting error patterns in training data and prompting history, (2) semantic-unit optimization for editing functional prompt segments, and (3) multimodal-friendly progression supporting both end-to-end LLM and LLM-MLLM workflows. Applied in contexts like single/multi-image QA (e.g., OCRV2) and complex task analysis (e.g., BBH), HAPO demonstrates enhanced optimization efficiency, outperforming comparable automated prompt optimization methods and establishing an extensible paradigm for scalable prompt engineering.
Mobile-Agent-RAG: Driving Smart Multi-Agent Coordination with Contextual Knowledge Empowerment for Long-Horizon Mobile Automation
Nov 15, 2025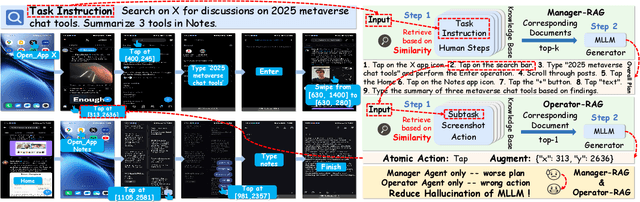
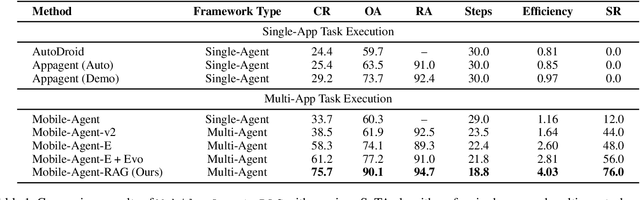
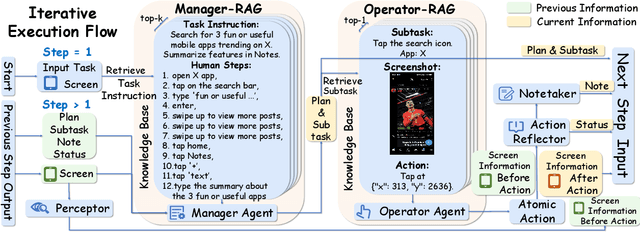
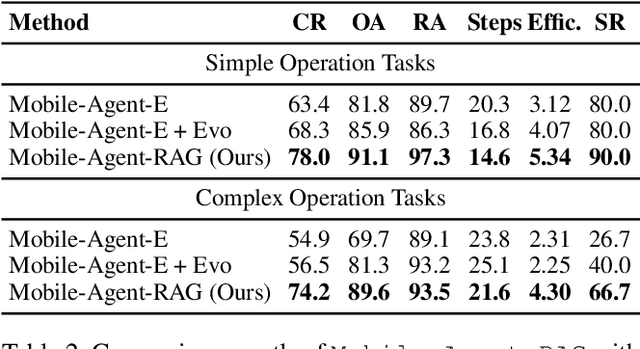
Mobile agents show immense potential, yet current state-of-the-art (SoTA) agents exhibit inadequate success rates on real-world, long-horizon, cross-application tasks. We attribute this bottleneck to the agents' excessive reliance on static, internal knowledge within MLLMs, which leads to two critical failure points: 1) strategic hallucinations in high-level planning and 2) operational errors during low-level execution on user interfaces (UI). The core insight of this paper is that high-level planning and low-level UI operations require fundamentally distinct types of knowledge. Planning demands high-level, strategy-oriented experiences, whereas operations necessitate low-level, precise instructions closely tied to specific app UIs. Motivated by these insights, we propose Mobile-Agent-RAG, a novel hierarchical multi-agent framework that innovatively integrates dual-level retrieval augmentation. At the planning stage, we introduce Manager-RAG to reduce strategic hallucinations by retrieving human-validated comprehensive task plans that provide high-level guidance. At the execution stage, we develop Operator-RAG to improve execution accuracy by retrieving the most precise low-level guidance for accurate atomic actions, aligned with the current app and subtask. To accurately deliver these knowledge types, we construct two specialized retrieval-oriented knowledge bases. Furthermore, we introduce Mobile-Eval-RAG, a challenging benchmark for evaluating such agents on realistic multi-app, long-horizon tasks. Extensive experiments demonstrate that Mobile-Agent-RAG significantly outperforms SoTA baselines, improving task completion rate by 11.0% and step efficiency by 10.2%, establishing a robust paradigm for context-aware, reliable multi-agent mobile automation.
OwlCap: Harmonizing Motion-Detail for Video Captioning via HMD-270K and Caption Set Equivalence Reward
Aug 27, 2025
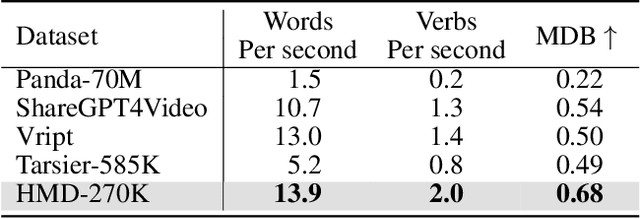
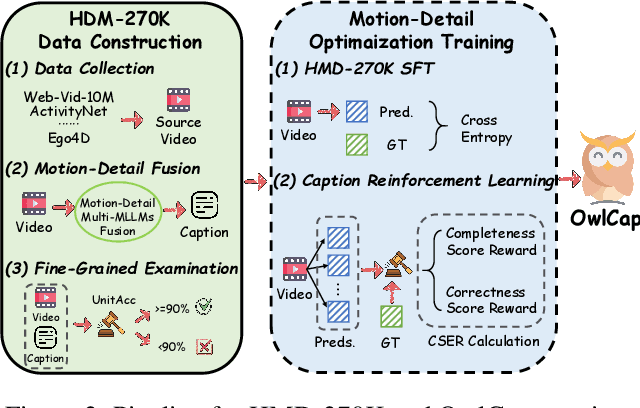
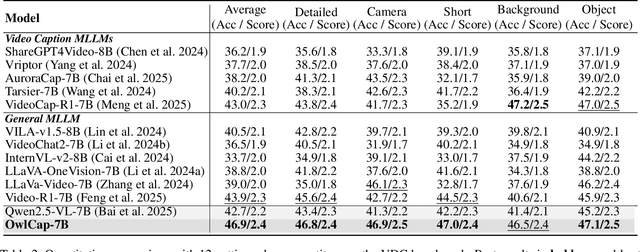
Video captioning aims to generate comprehensive and coherent descriptions of the video content, contributing to the advancement of both video understanding and generation. However, existing methods often suffer from motion-detail imbalance, as models tend to overemphasize one aspect while neglecting the other. This imbalance results in incomplete captions, which in turn leads to a lack of consistency in video understanding and generation. To address this issue, we propose solutions from two aspects: 1) Data aspect: We constructed the Harmonizing Motion-Detail 270K (HMD-270K) dataset through a two-stage pipeline: Motion-Detail Fusion (MDF) and Fine-Grained Examination (FGE). 2) Optimization aspect: We introduce the Caption Set Equivalence Reward (CSER) based on Group Relative Policy Optimization (GRPO). CSER enhances completeness and accuracy in capturing both motion and details through unit-to-set matching and bidirectional validation. Based on the HMD-270K supervised fine-tuning and GRPO post-training with CSER, we developed OwlCap, a powerful video captioning multi-modal large language model (MLLM) with motion-detail balance. Experimental results demonstrate that OwlCap achieves significant improvements compared to baseline models on two benchmarks: the detail-focused VDC (+4.2 Acc) and the motion-focused DREAM-1K (+4.6 F1). The HMD-270K dataset and OwlCap model will be publicly released to facilitate video captioning research community advancements.
Efficient Agent: Optimizing Planning Capability for Multimodal Retrieval Augmented Generation
Aug 12, 2025Multimodal Retrieval-Augmented Generation (mRAG) has emerged as a promising solution to address the temporal limitations of Multimodal Large Language Models (MLLMs) in real-world scenarios like news analysis and trending topics. However, existing approaches often suffer from rigid retrieval strategies and under-utilization of visual information. To bridge this gap, we propose E-Agent, an agent framework featuring two key innovations: a mRAG planner trained to dynamically orchestrate multimodal tools based on contextual reasoning, and a task executor employing tool-aware execution sequencing to implement optimized mRAG workflows. E-Agent adopts a one-time mRAG planning strategy that enables efficient information retrieval while minimizing redundant tool invocations. To rigorously assess the planning capabilities of mRAG systems, we introduce the Real-World mRAG Planning (RemPlan) benchmark. This novel benchmark contains both retrieval-dependent and retrieval-independent question types, systematically annotated with essential retrieval tools required for each instance. The benchmark's explicit mRAG planning annotations and diverse question design enhance its practical relevance by simulating real-world scenarios requiring dynamic mRAG decisions. Experiments across RemPlan and three established benchmarks demonstrate E-Agent's superiority: 13% accuracy gain over state-of-the-art mRAG methods while reducing redundant searches by 37%.
X2Edit: Revisiting Arbitrary-Instruction Image Editing through Self-Constructed Data and Task-Aware Representation Learning
Aug 11, 2025Existing open-source datasets for arbitrary-instruction image editing remain suboptimal, while a plug-and-play editing module compatible with community-prevalent generative models is notably absent. In this paper, we first introduce the X2Edit Dataset, a comprehensive dataset covering 14 diverse editing tasks, including subject-driven generation. We utilize the industry-leading unified image generation models and expert models to construct the data. Meanwhile, we design reasonable editing instructions with the VLM and implement various scoring mechanisms to filter the data. As a result, we construct 3.7 million high-quality data with balanced categories. Second, to better integrate seamlessly with community image generation models, we design task-aware MoE-LoRA training based on FLUX.1, with only 8\% of the parameters of the full model. To further improve the final performance, we utilize the internal representations of the diffusion model and define positive/negative samples based on image editing types to introduce contrastive learning. Extensive experiments demonstrate that the model's editing performance is competitive among many excellent models. Additionally, the constructed dataset exhibits substantial advantages over existing open-source datasets. The open-source code, checkpoints, and datasets for X2Edit can be found at the following link: https://github.com/OPPO-Mente-Lab/X2Edit.
Dynamic-I2V: Exploring Image-to-Video Generaion Models via Multimodal LLM
May 26, 2025



Recent advancements in image-to-video (I2V) generation have shown promising performance in conventional scenarios. However, these methods still encounter significant challenges when dealing with complex scenes that require a deep understanding of nuanced motion and intricate object-action relationships. To address these challenges, we present Dynamic-I2V, an innovative framework that integrates Multimodal Large Language Models (MLLMs) to jointly encode visual and textual conditions for a diffusion transformer (DiT) architecture. By leveraging the advanced multimodal understanding capabilities of MLLMs, our model significantly improves motion controllability and temporal coherence in synthesized videos. The inherent multimodality of Dynamic-I2V further enables flexible support for diverse conditional inputs, extending its applicability to various downstream generation tasks. Through systematic analysis, we identify a critical limitation in current I2V benchmarks: a significant bias towards favoring low-dynamic videos, stemming from an inadequate balance between motion complexity and visual quality metrics. To resolve this evaluation gap, we propose DIVE - a novel assessment benchmark specifically designed for comprehensive dynamic quality measurement in I2V generation. In conclusion, extensive quantitative and qualitative experiments confirm that Dynamic-I2V attains state-of-the-art performance in image-to-video generation, particularly revealing significant improvements of 42.5%, 7.9%, and 11.8% in dynamic range, controllability, and quality, respectively, as assessed by the DIVE metric in comparison to existing methods.
MergeVQ: A Unified Framework for Visual Generation and Representation with Disentangled Token Merging and Quantization
Apr 01, 2025Masked Image Modeling (MIM) with Vector Quantization (VQ) has achieved great success in both self-supervised pre-training and image generation. However, most existing methods struggle to address the trade-off in shared latent space for generation quality vs. representation learning and efficiency. To push the limits of this paradigm, we propose MergeVQ, which incorporates token merging techniques into VQ-based generative models to bridge the gap between image generation and visual representation learning in a unified architecture. During pre-training, MergeVQ decouples top-k semantics from latent space with the token merge module after self-attention blocks in the encoder for subsequent Look-up Free Quantization (LFQ) and global alignment and recovers their fine-grained details through cross-attention in the decoder for reconstruction. As for the second-stage generation, we introduce MergeAR, which performs KV Cache compression for efficient raster-order prediction. Extensive experiments on ImageNet verify that MergeVQ as an AR generative model achieves competitive performance in both visual representation learning and image generation tasks while maintaining favorable token efficiency and inference speed. The code and model will be available at https://apexgen-x.github.io/MergeVQ.
Improved Visual-Spatial Reasoning via R1-Zero-Like Training
Apr 01, 2025Increasing attention has been placed on improving the reasoning capacities of multi-modal large language models (MLLMs). As the cornerstone for AI agents that function in the physical realm, video-based visual-spatial intelligence (VSI) emerges as one of the most pivotal reasoning capabilities of MLLMs. This work conducts a first, in-depth study on improving the visual-spatial reasoning of MLLMs via R1-Zero-like training. Technically, we first identify that the visual-spatial reasoning capacities of small- to medium-sized Qwen2-VL models cannot be activated via Chain of Thought (CoT) prompts. We then incorporate GRPO training for improved visual-spatial reasoning, using the carefully curated VSI-100k dataset, following DeepSeek-R1-Zero. During the investigation, we identify the necessity to keep the KL penalty (even with a small value) in GRPO. With just 120 GPU hours, our vsGRPO-2B model, fine-tuned from Qwen2-VL-2B, can outperform the base model by 12.1% and surpass GPT-4o. Moreover, our vsGRPO-7B model, fine-tuned from Qwen2-VL-7B, achieves performance comparable to that of the best open-source model LLaVA-NeXT-Video-72B. Additionally, we compare vsGRPO to supervised fine-tuning and direct preference optimization baselines and observe strong performance superiority. The code and dataset will be available soon.
H2VU-Benchmark: A Comprehensive Benchmark for Hierarchical Holistic Video Understanding
Mar 31, 2025With the rapid development of multimodal models, the demand for assessing video understanding capabilities has been steadily increasing. However, existing benchmarks for evaluating video understanding exhibit significant limitations in coverage, task diversity, and scene adaptability. These shortcomings hinder the accurate assessment of models' comprehensive video understanding capabilities. To tackle this challenge, we propose a hierarchical and holistic video understanding (H2VU) benchmark designed to evaluate both general video and online streaming video comprehension. This benchmark contributes three key features: Extended video duration: Spanning videos from brief 3-second clips to comprehensive 1.5-hour recordings, thereby bridging the temporal gaps found in current benchmarks. Comprehensive assessment tasks: Beyond traditional perceptual and reasoning tasks, we have introduced modules for countercommonsense comprehension and trajectory state tracking. These additions test the models' deep understanding capabilities beyond mere prior knowledge. Enriched video data: To keep pace with the rapid evolution of current AI agents, we have expanded first-person streaming video datasets. This expansion allows for the exploration of multimodal models' performance in understanding streaming videos from a first-person perspective. Extensive results from H2VU reveal that existing multimodal large language models (MLLMs) possess substantial potential for improvement in our newly proposed evaluation tasks. We expect that H2VU will facilitate advancements in video understanding research by offering a comprehensive and in-depth analysis of MLLMs.
Layton: Latent Consistency Tokenizer for 1024-pixel Image Reconstruction and Generation by 256 Tokens
Mar 12, 2025



Image tokenization has significantly advanced visual generation and multimodal modeling, particularly when paired with autoregressive models. However, current methods face challenges in balancing efficiency and fidelity: high-resolution image reconstruction either requires an excessive number of tokens or compromises critical details through token reduction. To resolve this, we propose Latent Consistency Tokenizer (Layton) that bridges discrete visual tokens with the compact latent space of pre-trained Latent Diffusion Models (LDMs), enabling efficient representation of 1024x1024 images using only 256 tokens-a 16 times compression over VQGAN. Layton integrates a transformer encoder, a quantized codebook, and a latent consistency decoder. Direct application of LDM as the decoder results in color and brightness discrepancies. Thus, we convert it to latent consistency decoder, reducing multi-step sampling to 1-2 steps for direct pixel-level supervision. Experiments demonstrate Layton's superiority in high-fidelity reconstruction, with 10.8 reconstruction Frechet Inception Distance on MSCOCO-2017 5K benchmark for 1024x1024 image reconstruction. We also extend Layton to a text-to-image generation model, LaytonGen, working in autoregression. It achieves 0.73 score on GenEval benchmark, surpassing current state-of-the-art methods. Project homepage: https://github.com/OPPO-Mente-Lab/Layton