 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVMF-GOS: Geometry-guided virtual Outlier Synthesis for Long-Tailed OOD Detection
Feb 05, 2026Out-of-Distribution (OOD) detection under long-tailed distributions is a highly challenging task because the scarcity of samples in tail classes leads to blurred decision boundaries in the feature space. Current state-of-the-art (sota) methods typically employ Outlier Exposure (OE) strategies, relying on large-scale real external datasets (such as 80 Million Tiny Images) to regularize the feature space. However, this dependence on external data often becomes infeasible in practical deployment due to high data acquisition costs and privacy sensitivity. To this end, we propose a novel data-free framework aimed at completely eliminating reliance on external datasets while maintaining superior detection performance. We introduce a Geometry-guided virtual Outlier Synthesis (GOS) strategy that models statistical properties using the von Mises-Fisher (vMF) distribution on a hypersphere. Specifically, we locate a low-likelihood annulus in the feature space and perform directional sampling of virtual outliers in this region. Simultaneously, we introduce a new Dual-Granularity Semantic Loss (DGS) that utilizes contrastive learning to maximize the distinction between in-distribution (ID) features and these synthesized boundary outliers. Extensive experiments on benchmarks such as CIFAR-LT demonstrate that our method outperforms sota approaches that utilize external real images.
SimRPD: Optimizing Recruitment Proactive Dialogue Agents through Simulator-Based Data Evaluation and Selection
Jan 08, 2026Task-oriented proactive dialogue agents play a pivotal role in recruitment, particularly for steering conversations towards specific business outcomes, such as acquiring social-media contacts for private-channel conversion. Although supervised fine-tuning and reinforcement learning have proven effective for training such agents, their performance is heavily constrained by the scarcity of high-quality, goal-oriented domain-specific training data. To address this challenge, we propose SimRPD, a three-stage framework for training recruitment proactive dialogue agents. First, we develop a high-fidelity user simulator to synthesize large-scale conversational data through multi-turn online dialogue. Then we introduce a multi-dimensional evaluation framework based on Chain-of-Intention (CoI) to comprehensively assess the simulator and effectively select high-quality data, incorporating both global-level and instance-level metrics. Finally, we train the recruitment proactive dialogue agent on the selected dataset. Experiments in a real-world recruitment scenario demonstrate that SimRPD outperforms existing simulator-based data selection strategies, highlighting its practical value for industrial deployment and its potential applicability to other business-oriented dialogue scenarios.
GenX: Mastering Code and Test Generation with Execution Feedback
Dec 18, 2024



Recent advancements in language modeling have enabled the translation of natural language into code, and the use of execution feedback to improve code generation. However, these methods often rely heavily on pre-existing test cases, which may not always be available or comprehensive. In this work, we propose a novel approach that concurrently trains a code generation model and a test generation model, utilizing execution feedback to refine and enhance the performance of both. We introduce two strategies for test and code data augmentation and a new scoring function for code and test ranking. We experiment on the APPS dataset and demonstrate that our approach can effectively generate and augment test cases, filter and synthesize correct code solutions, and rank the quality of generated code and tests. The results demonstrate that our models, when iteratively trained with an increasing number of test cases and code solutions, outperform those trained on the original dataset.
InsCL: A Data-efficient Continual Learning Paradigm for Fine-tuning Large Language Models with Instructions
Mar 18, 2024



Instruction tuning effectively optimizes Large Language Models (LLMs) for downstream tasks. Due to the changing environment in real-life applications, LLMs necessitate continual task-specific adaptation without catastrophic forgetting. Considering the heavy computational cost, replay-based Continual Learning (CL) methods are the simplest and most widely used for LLMs to address the forgetting issue. However, traditional replay-based methods do not fully utilize instructions to customize the replay strategy. In this work, we propose a novel paradigm called Instruction-based Continual Learning (InsCL). InsCL dynamically replays previous data based on task similarity, calculated by Wasserstein Distance with instructions. Moreover, we further introduce an Instruction Information Metric (InsInfo) to quantify the complexity and diversity of instructions. According to InsInfo, InsCL guides the replay process more inclined to high-quality data. We conduct extensive experiments over 16 tasks with different training orders, observing consistent performance improvements of InsCL. When all tasks have been trained, InsCL achieves performance gains of 3.0 Relative Gain compared with Random Replay, and 27.96 Relative Gain compared with No Replay.
"My nose is running.""Are you also coughing?": Building A Medical Diagnosis Agent with Interpretable Inquiry Logics
May 02, 2022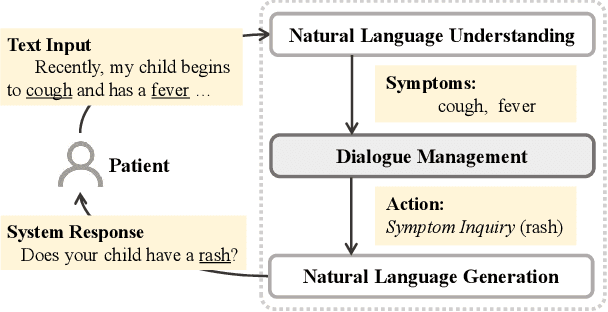
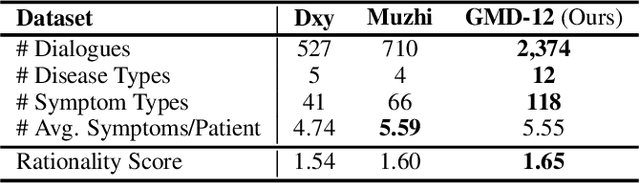
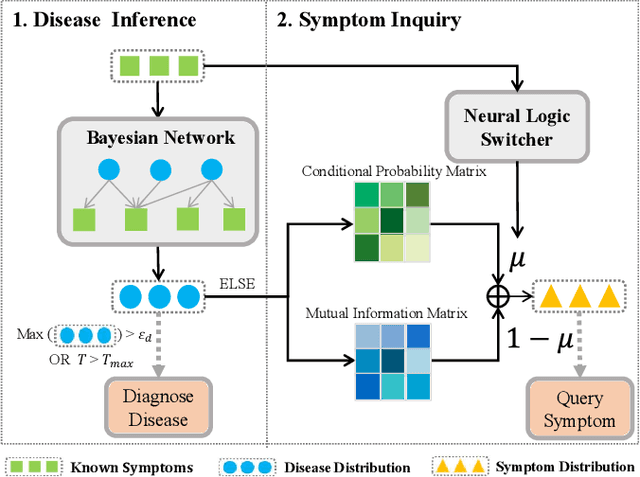
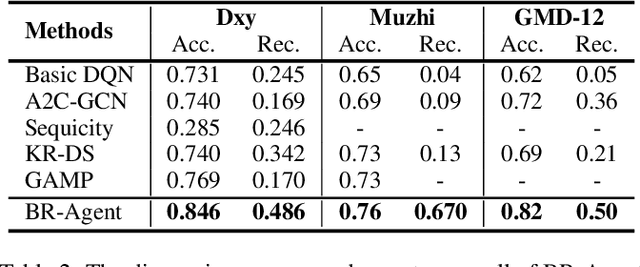
With the rise of telemedicine, the task of developing Dialogue Systems for Medical Diagnosis (DSMD) has received much attention in recent years. Different from early researches that needed to rely on extra human resources and expertise to help construct the system, recent researches focused on how to build DSMD in a purely data-driven manner. However, the previous data-driven DSMD methods largely overlooked the system interpretability, which is critical for a medical application, and they also suffered from the data sparsity issue at the same time. In this paper, we explore how to bring interpretability to data-driven DSMD. Specifically, we propose a more interpretable decision process to implement the dialogue manager of DSMD by reasonably mimicking real doctors' inquiry logics, and we devise a model with highly transparent components to conduct the inference. Moreover, we collect a new DSMD dataset, which has a much larger scale, more diverse patterns and is of higher quality than the existing ones. The experiments show that our method obtains 7.7%, 10.0%, 3.0% absolute improvement in diagnosis accuracy respectively on three datasets, demonstrating the effectiveness of its rational decision process and model design. Our codes and the GMD-12 dataset are available at https://github.com/lwgkzl/BR-Agent.
Imperfect also Deserves Reward: Multi-Level and Sequential Reward Modeling for Better Dialog Management
Apr 10, 2021For task-oriented dialog systems, training a Reinforcement Learning (RL) based Dialog Management module suffers from low sample efficiency and slow convergence speed due to the sparse rewards in RL.To solve this problem, many strategies have been proposed to give proper rewards when training RL, but their rewards lack interpretability and cannot accurately estimate the distribution of state-action pairs in real dialogs. In this paper, we propose a multi-level reward modeling approach that factorizes a reward into a three-level hierarchy: domain, act, and slot. Based on inverse adversarial reinforcement learning, our designed reward model can provide more accurate and explainable reward signals for state-action pairs.Extensive evaluations show that our approach can be applied to a wide range of reinforcement learning-based dialog systems and significantly improves both the performance and the speed of convergence.
* 9 pages