 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-Coder: Advancing Competitive Programming with Fully Synthetic Tasks, Solutions, and Tests
Jan 11, 2026Competitive programming presents great challenges for Code LLMs due to its intensive reasoning demands and high logical complexity. However, current Code LLMs still rely heavily on real-world data, which limits their scalability. In this paper, we explore a fully synthetic approach: training Code LLMs with entirely generated tasks, solutions, and test cases, to empower code reasoning models without relying on real-world data. To support this, we leverage feature-based synthesis to propose a novel data synthesis pipeline called SynthSmith. SynthSmith shows strong potential in producing diverse and challenging tasks, along with verified solutions and tests, supporting both supervised fine-tuning and reinforcement learning. Based on the proposed synthetic SFT and RL datasets, we introduce the X-Coder model series, which achieves a notable pass rate of 62.9 avg@8 on LiveCodeBench v5 and 55.8 on v6, outperforming DeepCoder-14B-Preview and AReal-boba2-14B despite having only 7B parameters. In-depth analysis reveals that scaling laws hold on our synthetic dataset, and we explore which dimensions are more effective to scale. We further provide insights into code-centric reinforcement learning and highlight the key factors that shape performance through detailed ablations and analysis. Our findings demonstrate that scaling high-quality synthetic data and adopting staged training can greatly advance code reasoning, while mitigating reliance on real-world coding data.
A.S.E: A Repository-Level Benchmark for Evaluating Security in AI-Generated Code
Aug 25, 2025The increasing adoption of large language models (LLMs) in software engineering necessitates rigorous security evaluation of their generated code. However, existing benchmarks are inadequate, as they focus on isolated code snippets, employ unstable evaluation methods that lack reproducibility, and fail to connect the quality of input context with the security of the output. To address these gaps, we introduce A.S.E (AI Code Generation Security Evaluation), a benchmark for repository-level secure code generation. A.S.E constructs tasks from real-world repositories with documented CVEs, preserving full repository context like build systems and cross-file dependencies. Its reproducible, containerized evaluation framework uses expert-defined rules to provide stable, auditable assessments of security, build quality, and generation stability. Our evaluation of leading LLMs on A.S.E reveals three key findings: (1) Claude-3.7-Sonnet achieves the best overall performance. (2) The security gap between proprietary and open-source models is narrow; Qwen3-235B-A22B-Instruct attains the top security score. (3) Concise, ``fast-thinking'' decoding strategies consistently outperform complex, ``slow-thinking'' reasoning for security patching.
PeRL: Permutation-Enhanced Reinforcement Learning for Interleaved Vision-Language Reasoning
Jun 17, 2025Inspired by the impressive reasoning capabilities demonstrated by reinforcement learning approaches like DeepSeek-R1, recent emerging research has begun exploring the use of reinforcement learning (RL) to enhance vision-language models (VLMs) for multimodal reasoning tasks. However, most existing multimodal reinforcement learning approaches remain limited to spatial reasoning within single-image contexts, yet still struggle to generalize to more complex and real-world scenarios involving multi-image positional reasoning, where understanding the relationships across images is crucial. To address this challenge, we propose a general reinforcement learning approach PeRL tailored for interleaved multimodal tasks, and a multi-stage strategy designed to enhance the exploration-exploitation trade-off, thereby improving learning efficiency and task performance. Specifically, we introduce permutation of image sequences to simulate varied positional relationships to explore more spatial and positional diversity. Furthermore, we design a rollout filtering mechanism for resampling to focus on trajectories that contribute most to learning optimal behaviors to exploit learned policies effectively. We evaluate our model on 5 widely-used multi-image benchmarks and 3 single-image benchmarks. Our experiments confirm that PeRL trained model consistently surpasses R1-related and interleaved VLM baselines by a large margin, achieving state-of-the-art performance on multi-image benchmarks, while preserving comparable performance on single-image tasks.
Zero-P-to-3: Zero-Shot Partial-View Images to 3D Object
May 29, 2025



Generative 3D reconstruction shows strong potential in incomplete observations. While sparse-view and single-image reconstruction are well-researched, partial observation remains underexplored. In this context, dense views are accessible only from a specific angular range, with other perspectives remaining inaccessible. This task presents two main challenges: (i) limited View Range: observations confined to a narrow angular scope prevent effective traditional interpolation techniques that require evenly distributed perspectives. (ii) inconsistent Generation: views created for invisible regions often lack coherence with both visible regions and each other, compromising reconstruction consistency. To address these challenges, we propose \method, a novel training-free approach that integrates the local dense observations and multi-source priors for reconstruction. Our method introduces a fusion-based strategy to effectively align these priors in DDIM sampling, thereby generating multi-view consistent images to supervise invisible views. We further design an iterative refinement strategy, which uses the geometric structures of the object to enhance reconstruction quality. Extensive experiments on multiple datasets show the superiority of our method over SOTAs, especially in invisible regions.
IterPref: Focal Preference Learning for Code Generation via Iterative Debugging
Mar 04, 2025



Preference learning enhances Code LLMs beyond supervised fine-tuning by leveraging relative quality comparisons. Existing methods construct preference pairs from candidates based on test case success, treating the higher pass rate sample as positive and the lower as negative. However, this approach does not pinpoint specific errors in the code, which prevents the model from learning more informative error correction patterns, as aligning failing code as a whole lacks the granularity needed to capture meaningful error-resolution relationships. To address these issues, we propose IterPref, a new preference alignment framework that mimics human iterative debugging to refine Code LLMs. IterPref explicitly locates error regions and aligns the corresponding tokens via a tailored DPO algorithm. To generate informative pairs, we introduce the CodeFlow dataset, where samples are iteratively refined until passing tests, with modifications capturing error corrections. Extensive experiments show that a diverse suite of Code LLMs equipped with IterPref achieves significant performance gains in code generation and improves on challenging tasks like BigCodeBench. In-depth analysis reveals that IterPref yields fewer errors. Our code and data will be made publicaly available.
EpiCoder: Encompassing Diversity and Complexity in Code Generation
Jan 08, 2025Effective instruction tuning is indispensable for optimizing code LLMs, aligning model behavior with user expectations and enhancing model performance in real-world applications. However, most existing methods focus on code snippets, which are limited to specific functionalities and rigid structures, restricting the complexity and diversity of the synthesized data. To address these limitations, we introduce a novel feature tree-based synthesis framework inspired by Abstract Syntax Trees (AST). Unlike AST, which captures syntactic structure of code, our framework models semantic relationships between code elements, enabling the generation of more nuanced and diverse data. The feature tree is constructed from raw data and refined iteratively to increase the quantity and diversity of the extracted features. This process enables the identification of more complex patterns and relationships within the code. By sampling subtrees with controlled depth and breadth, our framework allows precise adjustments to the complexity of the generated code, supporting a wide range of tasks from simple function-level operations to intricate multi-file scenarios. We fine-tuned widely-used base models to create the EpiCoder series, achieving state-of-the-art performance at both the function and file levels across multiple benchmarks. Notably, empirical evidence indicates that our approach shows significant potential in synthesizing highly complex repository-level code data. Further analysis elucidates the merits of this approach by rigorously assessing data complexity and diversity through software engineering principles and LLM-as-a-judge method.
Velocitune: A Velocity-based Dynamic Domain Reweighting Method for Continual Pre-training
Nov 21, 2024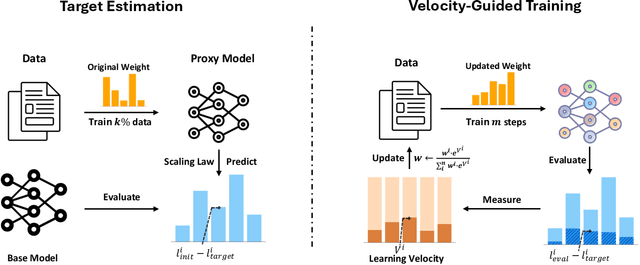
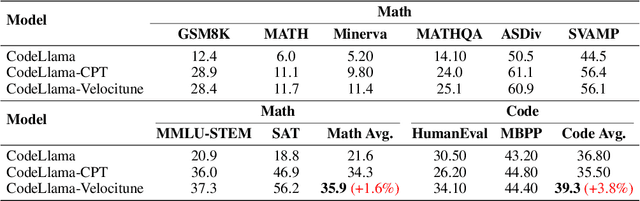
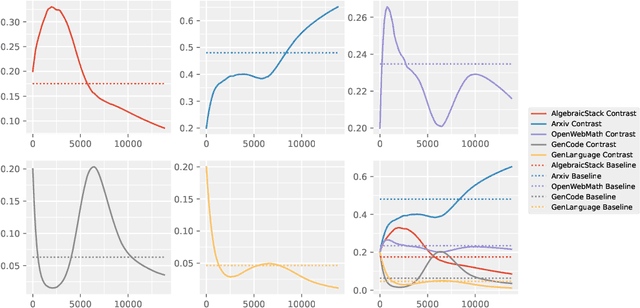
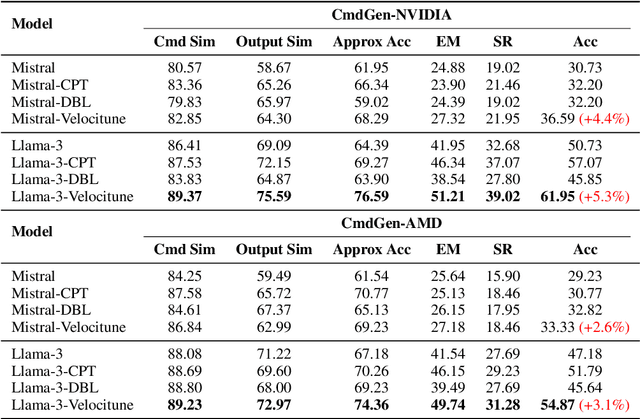
It is well-known that a diverse corpus is critical for training large language models, which are typically constructed from a mixture of various domains. In general, previous efforts resort to sampling training data from different domains with static proportions, as well as adjusting data proportions during training. However, few methods have addressed the complexities of domain-adaptive continual pre-training. To fill this gap, we propose Velocitune, a novel framework dynamically assesses learning velocity and adjusts data proportions accordingly, favoring slower-learning domains while shunning faster-learning ones, which is guided by a scaling law to indicate the desired learning goal for each domain with less associated cost. To evaluate the effectiveness of Velocitune, we conduct experiments in a reasoning-focused dataset with CodeLlama, as well as in a corpus specialised for system command generation with Llama3 and Mistral. Velocitune achieves performance gains in both math and code reasoning tasks and command-line generation benchmarks. Further analysis reveals that key factors driving Velocitune's effectiveness include target loss prediction and data ordering.
On the Evaluation Consistency of Attribution-based Explanations
Jul 28, 2024
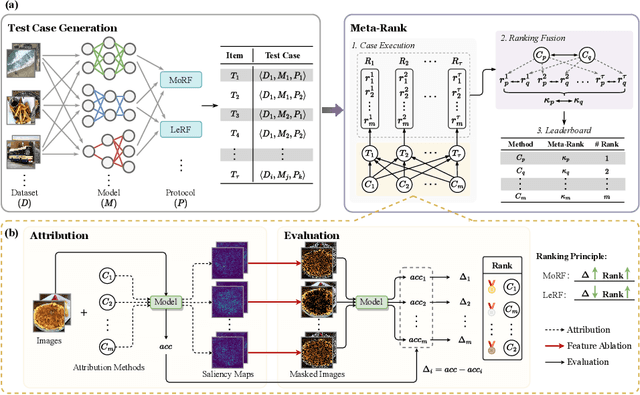
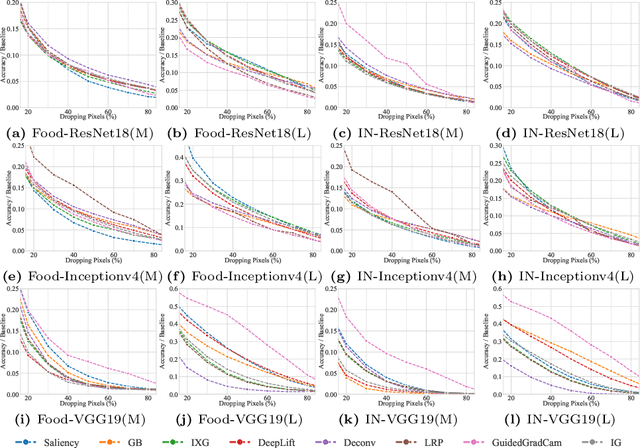
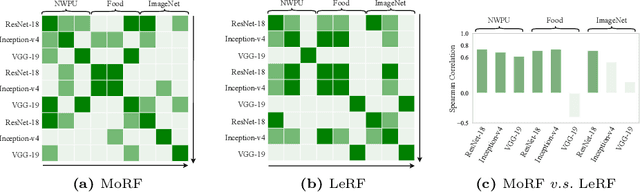
Attribution-based explanations are garnering increasing attention recently and have emerged as the predominant approach towards \textit{eXplanable Artificial Intelligence}~(XAI). However, the absence of consistent configurations and systematic investigations in prior literature impedes comprehensive evaluations of existing methodologies. In this work, we introduce {Meta-Rank}, an open platform for benchmarking attribution methods in the image domain. Presently, Meta-Rank assesses eight exemplary attribution methods using six renowned model architectures on four diverse datasets, employing both the \textit{Most Relevant First} (MoRF) and \textit{Least Relevant First} (LeRF) evaluation protocols. Through extensive experimentation, our benchmark reveals three insights in attribution evaluation endeavors: 1) evaluating attribution methods under disparate settings can yield divergent performance rankings; 2) although inconsistent across numerous cases, the performance rankings exhibit remarkable consistency across distinct checkpoints along the same training trajectory; 3) prior attempts at consistent evaluation fare no better than baselines when extended to more heterogeneous models and datasets. Our findings underscore the necessity for future research in this domain to conduct rigorous evaluations encompassing a broader range of models and datasets, and to reassess the assumptions underlying the empirical success of different attribution methods. Our code is publicly available at \url{https://github.com/TreeThree-R/Meta-Rank}.
Gradient-Mask Tuning Elevates the Upper Limits of LLM Performance
Jun 21, 2024Large language models (LLMs) have revolutionized lots of fields of research. Although it is well-known that fine-tuning is essential for enhancing the capabilities of LLMs, existing research suggests that there is potential redundancy in the fine-tuning process and therefore proposes to update only a subset of parameters. However, these methods fail to leverage the task-specific information to identify important parameters during training. Based on the insight that gradients inherently contain information on task-specific data, we propose Gradient-Mask Tuning (GMT), a method that selectively updates parameters during training based on their gradient information. Specifically, we compute the absolute values of the gradients and apply masking to those with relatively smaller magnitudes. Our empirical results across various tasks demonstrate that GMT not only outperforms traditional fine-tuning methods but also elevates the upper limits of LLM performance. Further analysis indicates that GMT exhibits insensitivity to mask ratio and possesses computational efficiency comparable to vanilla SFT.
PruningBench: A Comprehensive Benchmark of Structural Pruning
Jun 18, 2024



Structural pruning has emerged as a promising approach for producing more efficient models. Nevertheless, the community suffers from a lack of standardized benchmarks and metrics, leaving the progress in this area not fully comprehended. To fill this gap, we present the first comprehensive benchmark, termed \textit{PruningBench}, for structural pruning. PruningBench showcases the following three characteristics: 1) PruningBench employs a unified and consistent framework for evaluating the effectiveness of diverse structural pruning techniques; 2) PruningBench systematically evaluates 16 existing pruning methods, encompassing a wide array of models (e.g., CNNs and ViTs) and tasks (e.g., classification and detection); 3) PruningBench provides easily implementable interfaces to facilitate the implementation of future pruning methods, and enables the subsequent researchers to incorporate their work into our leaderboards. We provide an online pruning platform http://pruning.vipazoo.cn for customizing pruning tasks and reproducing all results in this paper. Codes will be made publicly available.