 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDMax: Aggressive Parallel Decoding for dLLMs
Apr 09, 2026We present DMax, a new paradigm for efficient diffusion language models (dLLMs). It mitigates error accumulation in parallel decoding, enabling aggressive decoding parallelism while preserving generation quality. Unlike conventional masked dLLMs that decode through a binary mask-to-token transition, DMax reformulates decoding as a progressive self-refinement from mask embeddings to token embeddings. At the core of our approach is On-Policy Uniform Training, a novel training strategy that efficiently unifies masked and uniform dLLMs, equipping the model to recover clean tokens from both masked inputs and its own erroneous predictions. Building on this foundation, we further propose Soft Parallel Decoding. We represent each intermediate decoding state as an interpolation between the predicted token embedding and the mask embedding, enabling iterative self-revising in embedding space. Extensive experiments across a variety of benchmarks demonstrate the effectiveness of DMax. Compared with the original LLaDA-2.0-mini, our method improves TPF on GSM8K from 2.04 to 5.47 while preserving accuracy. On MBPP, it increases TPF from 2.71 to 5.86 while maintaining comparable performance. On two H200 GPUs, our model achieves an average of 1,338 TPS at batch size 1. Code is available at: https://github.com/czg1225/DMax
Rethinking Token Reduction for Large Vision-Language Models
Mar 23, 2026Large Vision-Language Models (LVLMs) excel in visual understanding and reasoning, but the excessive visual tokens lead to high inference costs. Although recent token reduction methods mitigate this issue, they mainly target single-turn Visual Question Answering (VQA), leaving the more practical multi-turn VQA (MT-VQA) scenario largely unexplored. MT-VQA introduces additional challenges, as subsequent questions are unknown beforehand and may refer to arbitrary image regions, making existing reduction strategies ineffective. Specifically, current approaches fall into two categories: prompt-dependent methods, which bias toward the initial text prompt and discard information useful for subsequent turns; prompt-agnostic ones, which, though technically applicable to multi-turn settings, rely on heuristic reduction metrics such as attention scores, leading to suboptimal performance. In this paper, we propose a learning-based prompt-agnostic method, termed MetaCompress, overcoming the limitations of heuristic designs. We begin by formulating token reduction as a learnable compression mapping, unifying existing formats such as pruning and merging into a single learning objective. Upon this formulation, we introduce a data-efficient training paradigm capable of learning optimal compression mappings with limited computational costs. Extensive experiments on MT-VQA benchmarks and across multiple LVLM architectures demonstrate that MetaCompress achieves superior efficiency-accuracy trade-offs while maintaining strong generalization across dialogue turns. Our code is available at https://github.com/MArSha1147/MetaCompress.
Invisible Safety Threat: Malicious Finetuning for LLM via Steganography
Mar 09, 2026Understanding and addressing potential safety alignment risks in large language models (LLMs) is critical for ensuring their safe and trustworthy deployment. In this paper, we highlight an insidious safety threat: a compromised LLM can maintain a facade of proper safety alignment while covertly generating harmful content. To achieve this, we finetune the model to understand and apply a steganographic technique. At inference time, we input a prompt that contains a steganographically embedded malicious target question along with a plaintext cover question. The model, in turn, produces a target response similarly embedded within a benign-looking cover response. In this process, human observers only see the model being prompted with a cover question and generating a corresponding cover response, while the malicious content is hidden from view. We demonstrate this invisible safety threat on GPT-4.1 despite the OpenAI finetuning API's safeguards. The finetuned model produces steganographic malicious outputs in response to hidden malicious prompts, while the user interface displays only a fully benign cover interaction. We also replicate the attack on three open-source models, Llama-3.3-70B-Instruct, Phi-4, and Mistral-Small-24B-Base-2501, confirming the generality of our method. We quantitatively evaluate our method on the AdvBench dataset, using Llama-Guard-3-8B for content safety classification. Across all four models, all stegotexts containing malicious content are incorrectly classified as safe.
Self-Purification Mitigates Backdoors in Multimodal Diffusion Language Models
Feb 24, 2026Multimodal Diffusion Language Models (MDLMs) have recently emerged as a competitive alternative to their autoregressive counterparts. Yet their vulnerability to backdoor attacks remains largely unexplored. In this work, we show that well-established data-poisoning pipelines can successfully implant backdoors into MDLMs, enabling attackers to manipulate model behavior via specific triggers while maintaining normal performance on clean inputs. However, defense strategies effective to these models are yet to emerge. To bridge this gap, we introduce a backdoor defense framework for MDLMs named DiSP (Diffusion Self-Purification). DiSP is driven by a key observation: selectively masking certain vision tokens at inference time can neutralize a backdoored model's trigger-induced behaviors and restore normal functionality. Building on this, we purify the poisoned dataset using the compromised model itself, then fine-tune the model on the purified data to recover it to a clean one. Given such a specific design, DiSP can remove backdoors without requiring any auxiliary models or clean reference data. Extensive experiments demonstrate that our approach effectively mitigates backdoor effects, reducing the attack success rate (ASR) from over 90% to typically under 5%, while maintaining model performance on benign tasks.
dVoting: Fast Voting for dLLMs
Feb 12, 2026Diffusion Large Language Models (dLLMs) represent a new paradigm beyond autoregressive modeling, offering competitive performance while naturally enabling a flexible decoding process. Specifically, dLLMs can generate tokens at arbitrary positions in parallel, endowing them with significant potential for parallel test-time scaling, which was previously constrained by severe inefficiency in autoregressive modeling. In this work, we introduce dVoting, a fast voting technique that boosts reasoning capability without training, with only an acceptable extra computational overhead. dVoting is motivated by the observation that, across multiple samples for the same prompt, token predictions remain largely consistent, whereas performance is determined by a small subset of tokens exhibiting cross-sample variability. Leveraging the arbitrary-position generation capability of dLLMs, dVoting performs iterative refinement by sampling, identifying uncertain tokens via consistency analysis, regenerating them through voting, and repeating this process until convergence. Extensive evaluations demonstrate that dVoting consistently improves performance across various benchmarks. It achieves gains of 6.22%-7.66% on GSM8K, 4.40%-7.20% on MATH500, 3.16%-14.84% on ARC-C, and 4.83%-5.74% on MMLU. Our code is available at https://github.com/fscdc/dVoting
dParallel: Learnable Parallel Decoding for dLLMs
Sep 30, 2025
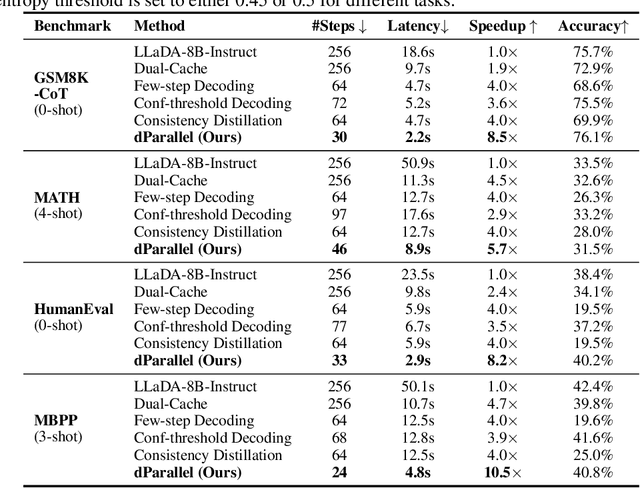
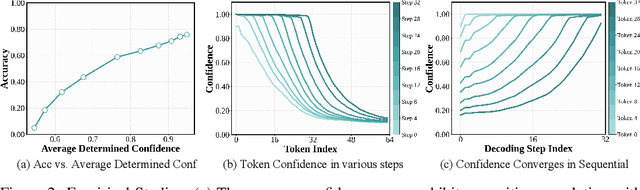
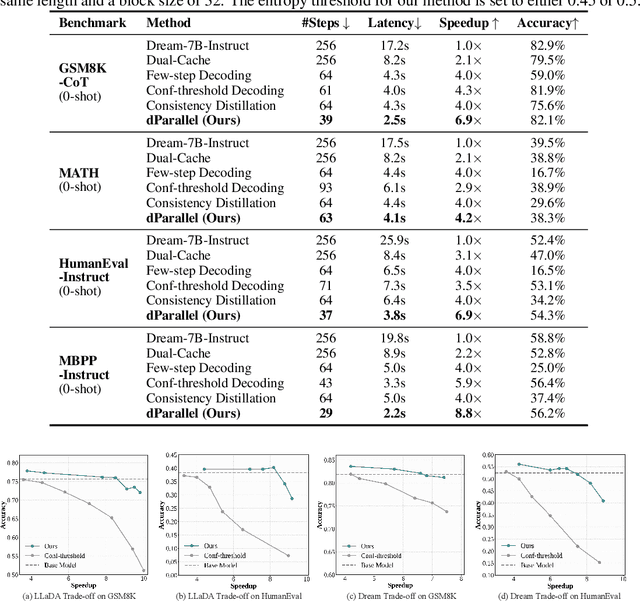
Diffusion large language models (dLLMs) have recently drawn considerable attention within the research community as a promising alternative to autoregressive generation, offering parallel token prediction and lower inference latency. Yet, their parallel decoding potential remains largely underexplored, as existing open-source models still require nearly token-length decoding steps to ensure performance. To address this, we introduce dParallel, a simple and effective method that unlocks the inherent parallelism of dLLMs for fast sampling. We identify that the key bottleneck to parallel decoding arises from the sequential certainty convergence for masked tokens. Building on this insight, we introduce the core of our approach: certainty-forcing distillation, a novel training strategy that distills the model to follow its original sampling trajectories while enforcing it to achieve high certainty on masked tokens more rapidly and in parallel. Extensive experiments across various benchmarks demonstrate that our method can dramatically reduce the number of decoding steps while maintaining performance. When applied to the LLaDA-8B-Instruct model, dParallel reduces decoding steps from 256 to 30 on GSM8K, achieving an 8.5x speedup without performance degradation. On the MBPP benchmark, it cuts decoding steps from 256 to 24, resulting in a 10.5x speedup while maintaining accuracy. Our code is available at https://github.com/czg1225/dParallel
ConciseHint: Boosting Efficient Reasoning via Continuous Concise Hints during Generation
Jun 24, 2025Recent advancements in large reasoning models (LRMs) like DeepSeek-R1 and OpenAI o1 series have achieved notable performance enhancements on complex reasoning tasks by scaling up the generation length by Chain-of-Thought (CoT). However, an emerging issue is their inclination to produce excessively verbose reasoning processes, leading to the inefficiency problem. Existing literature on improving efficiency mainly adheres to the before-reasoning paradigms such as prompting and reasoning or fine-tuning and reasoning, but ignores the promising direction of directly encouraging the model to speak concisely by intervening during the generation of reasoning. In order to fill the blank, we propose a framework dubbed ConciseHint, which continuously encourages the reasoning model to speak concisely by injecting the textual hint (manually designed or trained on the concise data) during the token generation of the reasoning process. Besides, ConciseHint is adaptive to the complexity of the query by adaptively adjusting the hint intensity, which ensures it will not undermine model performance. Experiments on the state-of-the-art LRMs, including DeepSeek-R1 and Qwen-3 series, demonstrate that our method can effectively produce concise reasoning processes while maintaining performance well. For instance, we achieve a reduction ratio of 65\% for the reasoning length on GSM8K benchmark with Qwen-3 4B with nearly no accuracy loss.
Diversity-Guided MLP Reduction for Efficient Large Vision Transformers
Jun 10, 2025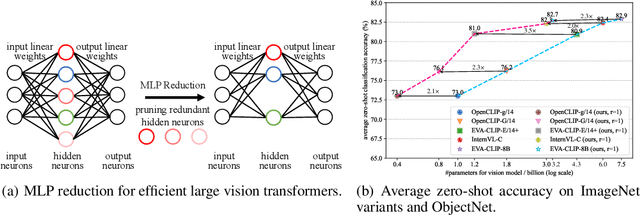
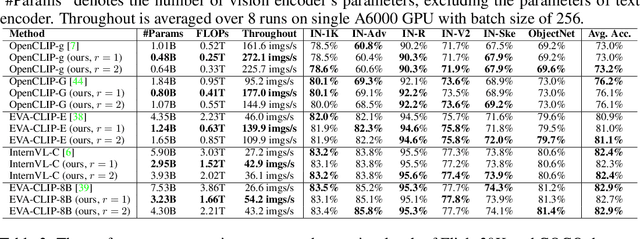
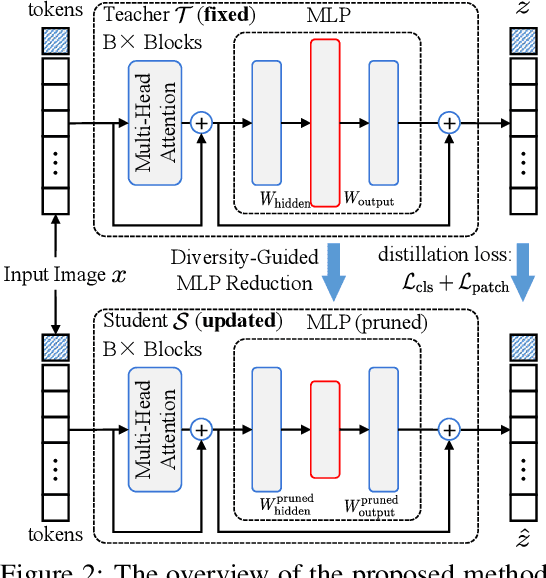
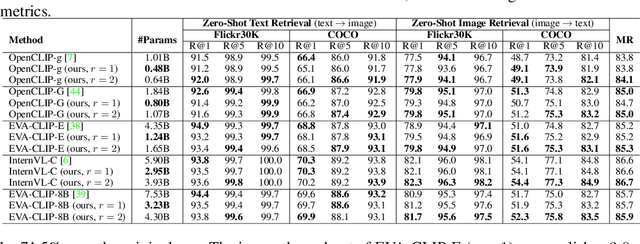
Transformer models achieve excellent scaling property, where the performance is improved with the increment of model capacity. However, large-scale model parameters lead to an unaffordable cost of computing and memory. We analyze popular transformer architectures and find that multilayer perceptron (MLP) modules take up the majority of model parameters. To this end, we focus on the recoverability of the compressed models and propose a Diversity-Guided MLP Reduction (DGMR) method to significantly reduce the parameters of large vision transformers with only negligible performance degradation. Specifically, we conduct a Gram-Schmidt weight pruning strategy to eliminate redundant neurons of MLP hidden layer, while preserving weight diversity for better performance recover during distillation. Compared to the model trained from scratch, our pruned model only requires 0.06\% data of LAION-2B (for the training of large vision transformers) without labels (ImageNet-1K) to recover the original performance. Experimental results on several state-of-the-art large vision transformers demonstrate that our method achieves a more than 57.0\% parameter and FLOPs reduction in a near lossless manner. Notably, for EVA-CLIP-E (4.4B), our method accomplishes a 71.5\% parameter and FLOPs reduction without performance degradation. The source code and trained weights are available at https://github.com/visresearch/DGMR.
PixelThink: Towards Efficient Chain-of-Pixel Reasoning
May 29, 2025Existing reasoning segmentation approaches typically fine-tune multimodal large language models (MLLMs) using image-text pairs and corresponding mask labels. However, they exhibit limited generalization to out-of-distribution scenarios without an explicit reasoning process. Although recent efforts leverage reinforcement learning through group-relative policy optimization (GRPO) to enhance reasoning ability, they often suffer from overthinking - producing uniformly verbose reasoning chains irrespective of task complexity. This results in elevated computational costs and limited control over reasoning quality. To address this problem, we propose PixelThink, a simple yet effective scheme that integrates externally estimated task difficulty and internally measured model uncertainty to regulate reasoning generation within a reinforcement learning paradigm. The model learns to compress reasoning length in accordance with scene complexity and predictive confidence. To support comprehensive evaluation, we introduce ReasonSeg-Diff, an extended benchmark with annotated reasoning references and difficulty scores, along with a suite of metrics designed to assess segmentation accuracy, reasoning quality, and efficiency jointly. Experimental results demonstrate that the proposed approach improves both reasoning efficiency and overall segmentation performance. Our work contributes novel perspectives towards efficient and interpretable multimodal understanding. The code and model will be publicly available.
VeriThinker: Learning to Verify Makes Reasoning Model Efficient
May 23, 2025Large Reasoning Models (LRMs) excel at complex tasks using Chain-of-Thought (CoT) reasoning. However, their tendency to overthinking leads to unnecessarily lengthy reasoning chains, dramatically increasing inference costs. To mitigate this issue, we introduce VeriThinker, a novel approach for CoT compression. Unlike conventional methods that fine-tune LRMs directly on the original reasoning task using synthetic concise CoT data, we innovatively fine-tune the model solely through an auxiliary verification task. By training LRMs to accurately verify the correctness of CoT solutions, the LRMs inherently become more discerning about the necessity of subsequent self-reflection steps, thereby effectively suppressing overthinking. Extensive experiments validate that VeriThinker substantially reduces reasoning chain lengths while maintaining or even slightly improving accuracy. When applied to DeepSeek-R1-Distill-Qwen-7B, our approach reduces reasoning tokens on MATH500 from 3790 to 2125 while improving accuracy by 0.8% (94.0% to 94.8%), and on AIME25, tokens decrease from 14321 to 10287 with a 2.1% accuracy gain (38.7% to 40.8%). Additionally, our experiments demonstrate that VeriThinker can also be zero-shot generalized to speculative reasoning. Code is available at https://github.com/czg1225/VeriThinker