 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynFlowDrive: Flow-Based Dynamic World Modeling for Autonomous Driving
Mar 20, 2026Recently, world models have been incorporated into the autonomous driving systems to improve the planning reliability. Existing approaches typically predict future states through appearance generation or deterministic regression, which limits their ability to capture trajectory-conditioned scene evolution and leads to unreliable action planning. To address this, we propose DynFlowDrive, a latent world model that leverages flow-based dynamics to model the transition of world states under different driving actions. By adopting the rectifiedflow formulation, the model learns a velocity field that describes how the scene state changes under different driving actions, enabling progressive prediction of future latent states. Building upon this, we further introduce a stability-aware multi-mode trajectory selection strategy that evaluates candidate trajectories according to the stability of the induced scene transitions. Extensive experiments on the nuScenes and NavSim benchmarks demonstrate consistent improvements across diverse driving frameworks without introducing additional inference overhead. Source code will be abaliable at https://github.com/xiaolul2/DynFlowDrive.
RelaxFlow: Text-Driven Amodal 3D Generation
Mar 05, 2026Image-to-3D generation faces inherent semantic ambiguity under occlusion, where partial observation alone is often insufficient to determine object category. In this work, we formalize text-driven amodal 3D generation, where text prompts steer the completion of unseen regions while strictly preserving input observation. Crucially, we identify that these objectives demand distinct control granularities: rigid control for the observation versus relaxed structural control for the prompt. To this end, we propose RelaxFlow, a training-free dual-branch framework that decouples control granularity via a Multi-Prior Consensus Module and a Relaxation Mechanism. Theoretically, we prove that our relaxation is equivalent to applying a low-pass filter on the generative vector field, which suppresses high-frequency instance details to isolate geometric structure that accommodates the observation. To facilitate evaluation, we introduce two diagnostic benchmarks, ExtremeOcc-3D and AmbiSem-3D. Extensive experiments demonstrate that RelaxFlow successfully steers the generation of unseen regions to match the prompt intent without compromising visual fidelity.
Interp3D: Correspondence-aware Interpolation for Generative Textured 3D Morphing
Jan 20, 2026Textured 3D morphing seeks to generate smooth and plausible transitions between two 3D assets, preserving both structural coherence and fine-grained appearance. This ability is crucial not only for advancing 3D generation research but also for practical applications in animation, editing, and digital content creation. Existing approaches either operate directly on geometry, limiting them to shape-only morphing while neglecting textures, or extend 2D interpolation strategies into 3D, which often causes semantic ambiguity, structural misalignment, and texture blurring. These challenges underscore the necessity to jointly preserve geometric consistency, texture alignment, and robustness throughout the transition process. To address this, we propose Interp3D, a novel training-free framework for textured 3D morphing. It harnesses generative priors and adopts a progressive alignment principle to ensure both geometric fidelity and texture coherence. Starting from semantically aligned interpolation in condition space, Interp3D enforces structural consistency via SLAT (Structured Latent)-guided structure interpolation, and finally transfers appearance details through fine-grained texture fusion. For comprehensive evaluations, we construct a dedicated dataset, Interp3DData, with graded difficulty levels and assess generation results from fidelity, transition smoothness, and plausibility. Both quantitative metrics and human studies demonstrate the significant advantages of our proposed approach over previous methods. Source code is available at https://github.com/xiaolul2/Interp3D.
Forging Spatial Intelligence: A Roadmap of Multi-Modal Data Pre-Training for Autonomous Systems
Dec 30, 2025The rapid advancement of autonomous systems, including self-driving vehicles and drones, has intensified the need to forge true Spatial Intelligence from multi-modal onboard sensor data. While foundation models excel in single-modal contexts, integrating their capabilities across diverse sensors like cameras and LiDAR to create a unified understanding remains a formidable challenge. This paper presents a comprehensive framework for multi-modal pre-training, identifying the core set of techniques driving progress toward this goal. We dissect the interplay between foundational sensor characteristics and learning strategies, evaluating the role of platform-specific datasets in enabling these advancements. Our central contribution is the formulation of a unified taxonomy for pre-training paradigms: ranging from single-modality baselines to sophisticated unified frameworks that learn holistic representations for advanced tasks like 3D object detection and semantic occupancy prediction. Furthermore, we investigate the integration of textual inputs and occupancy representations to facilitate open-world perception and planning. Finally, we identify critical bottlenecks, such as computational efficiency and model scalability, and propose a roadmap toward general-purpose multi-modal foundation models capable of achieving robust Spatial Intelligence for real-world deployment.
Vision-Language-Action Models for Autonomous Driving: Past, Present, and Future
Dec 18, 2025Autonomous driving has long relied on modular "Perception-Decision-Action" pipelines, where hand-crafted interfaces and rule-based components often break down in complex or long-tailed scenarios. Their cascaded design further propagates perception errors, degrading downstream planning and control. Vision-Action (VA) models address some limitations by learning direct mappings from visual inputs to actions, but they remain opaque, sensitive to distribution shifts, and lack structured reasoning or instruction-following capabilities. Recent progress in Large Language Models (LLMs) and multimodal learning has motivated the emergence of Vision-Language-Action (VLA) frameworks, which integrate perception with language-grounded decision making. By unifying visual understanding, linguistic reasoning, and actionable outputs, VLAs offer a pathway toward more interpretable, generalizable, and human-aligned driving policies. This work provides a structured characterization of the emerging VLA landscape for autonomous driving. We trace the evolution from early VA approaches to modern VLA frameworks and organize existing methods into two principal paradigms: End-to-End VLA, which integrates perception, reasoning, and planning within a single model, and Dual-System VLA, which separates slow deliberation (via VLMs) from fast, safety-critical execution (via planners). Within these paradigms, we further distinguish subclasses such as textual vs. numerical action generators and explicit vs. implicit guidance mechanisms. We also summarize representative datasets and benchmarks for evaluating VLA-based driving systems and highlight key challenges and open directions, including robustness, interpretability, and instruction fidelity. Overall, this work aims to establish a coherent foundation for advancing human-compatible autonomous driving systems.
MambaMap: Online Vectorized HD Map Construction using State Space Model
Jul 27, 2025High-definition (HD) maps are essential for autonomous driving, as they provide precise road information for downstream tasks. Recent advances highlight the potential of temporal modeling in addressing challenges like occlusions and extended perception range. However, existing methods either fail to fully exploit temporal information or incur substantial computational overhead in handling extended sequences. To tackle these challenges, we propose MambaMap, a novel framework that efficiently fuses long-range temporal features in the state space to construct online vectorized HD maps. Specifically, MambaMap incorporates a memory bank to store and utilize information from historical frames, dynamically updating BEV features and instance queries to improve robustness against noise and occlusions. Moreover, we introduce a gating mechanism in the state space, selectively integrating dependencies of map elements in high computational efficiency. In addition, we design innovative multi-directional and spatial-temporal scanning strategies to enhance feature extraction at both BEV and instance levels. These strategies significantly boost the prediction accuracy of our approach while ensuring robust temporal consistency. Extensive experiments on the nuScenes and Argoverse2 datasets demonstrate that our proposed MambaMap approach outperforms state-of-the-art methods across various splits and perception ranges. Source code will be available at https://github.com/ZiziAmy/MambaMap.
Critical Nodes Identification in Complex Networks: A Survey
Jul 08, 2025Complex networks have become essential tools for understanding diverse phenomena in social systems, traffic systems, biomolecular systems, and financial systems. Identifying critical nodes is a central theme in contemporary research, serving as a vital bridge between theoretical foundations and practical applications. Nevertheless, the intrinsic complexity and structural heterogeneity characterizing real-world networks, with particular emphasis on dynamic and higher-order networks, present substantial obstacles to the development of universal frameworks for critical node identification. This paper provides a comprehensive review of critical node identification techniques, categorizing them into seven main classes: centrality, critical nodes deletion problem, influence maximization, network control, artificial intelligence, higher-order and dynamic methods. Our review bridges the gaps in existing surveys by systematically classifying methods based on their methodological foundations and practical implications, and by highlighting their strengths, limitations, and applicability across different network types. Our work enhances the understanding of critical node research by identifying key challenges, such as algorithmic universality, real-time evaluation in dynamic networks, analysis of higher-order structures, and computational efficiency in large-scale networks. The structured synthesis consolidates current progress and highlights open questions, particularly in modeling temporal dynamics, advancing efficient algorithms, integrating machine learning approaches, and developing scalable and interpretable metrics for complex systems.
PointLoRA: Low-Rank Adaptation with Token Selection for Point Cloud Learning
Apr 22, 2025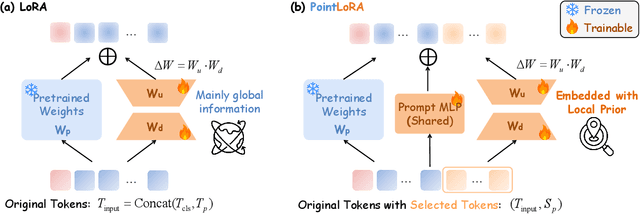
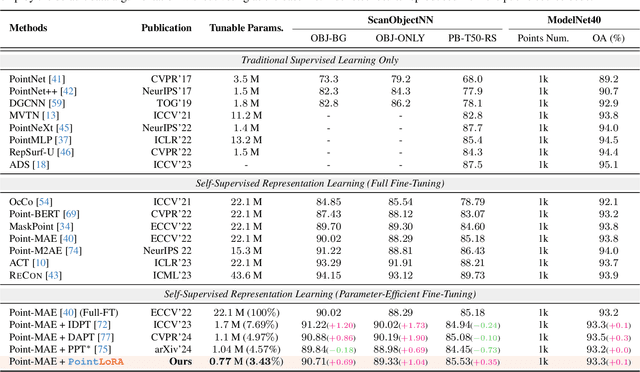
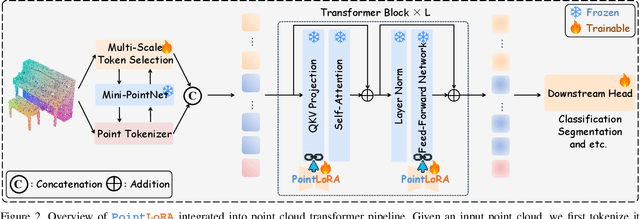
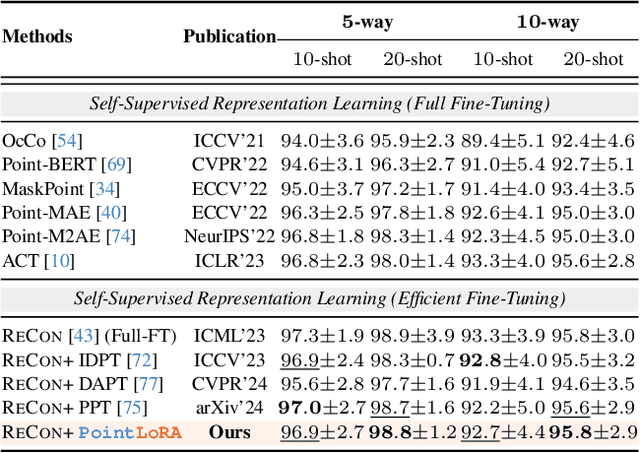
Self-supervised representation learning for point cloud has demonstrated effectiveness in improving pre-trained model performance across diverse tasks. However, as pre-trained models grow in complexity, fully fine-tuning them for downstream applications demands substantial computational and storage resources. Parameter-efficient fine-tuning (PEFT) methods offer a promising solution to mitigate these resource requirements, yet most current approaches rely on complex adapter and prompt mechanisms that increase tunable parameters. In this paper, we propose PointLoRA, a simple yet effective method that combines low-rank adaptation (LoRA) with multi-scale token selection to efficiently fine-tune point cloud models. Our approach embeds LoRA layers within the most parameter-intensive components of point cloud transformers, reducing the need for tunable parameters while enhancing global feature capture. Additionally, multi-scale token selection extracts critical local information to serve as prompts for downstream fine-tuning, effectively complementing the global context captured by LoRA. The experimental results across various pre-trained models and three challenging public datasets demonstrate that our approach achieves competitive performance with only 3.43% of the trainable parameters, making it highly effective for resource-constrained applications. Source code is available at: https://github.com/songw-zju/PointLoRA.
Uncertainty-Instructed Structure Injection for Generalizable HD Map Construction
Mar 29, 2025Reliable high-definition (HD) map construction is crucial for the driving safety of autonomous vehicles. Although recent studies demonstrate improved performance, their generalization capability across unfamiliar driving scenes remains unexplored. To tackle this issue, we propose UIGenMap, an uncertainty-instructed structure injection approach for generalizable HD map vectorization, which concerns the uncertainty resampling in statistical distribution and employs explicit instance features to reduce excessive reliance on training data. Specifically, we introduce the perspective-view (PV) detection branch to obtain explicit structural features, in which the uncertainty-aware decoder is designed to dynamically sample probability distributions considering the difference in scenes. With probabilistic embedding and selection, UI2DPrompt is proposed to construct PV-learnable prompts. These PV prompts are integrated into the map decoder by designed hybrid injection to compensate for neglected instance structures. To ensure real-time inference, a lightweight Mimic Query Distillation is designed to learn from PV prompts, which can serve as an efficient alternative to the flow of PV branches. Extensive experiments on challenging geographically disjoint (geo-based) data splits demonstrate that our UIGenMap achieves superior performance, with +5.7 mAP improvement on the nuScenes dataset. Source code will be available at https://github.com/xiaolul2/UIGenMap.
Not All Voxels Are Equal: Hardness-Aware Semantic Scene Completion with Self-Distillation
Apr 18, 2024Semantic scene completion, also known as semantic occupancy prediction, can provide dense geometric and semantic information for autonomous vehicles, which attracts the increasing attention of both academia and industry. Unfortunately, existing methods usually formulate this task as a voxel-wise classification problem and treat each voxel equally in 3D space during training. As the hard voxels have not been paid enough attention, the performance in some challenging regions is limited. The 3D dense space typically contains a large number of empty voxels, which are easy to learn but require amounts of computation due to handling all the voxels uniformly for the existing models. Furthermore, the voxels in the boundary region are more challenging to differentiate than those in the interior. In this paper, we propose HASSC approach to train the semantic scene completion model with hardness-aware design. The global hardness from the network optimization process is defined for dynamical hard voxel selection. Then, the local hardness with geometric anisotropy is adopted for voxel-wise refinement. Besides, self-distillation strategy is introduced to make training process stable and consistent. Extensive experiments show that our HASSC scheme can effectively promote the accuracy of the baseline model without incurring the extra inference cost. Source code is available at: https://github.com/songw-zju/HASSC.