 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Aware Clustering using Large Language Models
May 02, 2024Despite the remarkable success of Large Language Models (LLMs) in text understanding and generation, their potential for text clustering tasks remains underexplored. We observed that powerful closed-source LLMs provide good quality clusterings of entity sets but are not scalable due to the massive compute power required and the associated costs. Thus, we propose CACTUS (Context-Aware ClusTering with aUgmented triplet losS), a systematic approach that leverages open-source LLMs for efficient and effective supervised clustering of entity subsets, particularly focusing on text-based entities. Existing text clustering methods fail to effectively capture the context provided by the entity subset. Moreover, though there are several language modeling based approaches for clustering, very few are designed for the task of supervised clustering. This paper introduces a novel approach towards clustering entity subsets using LLMs by capturing context via a scalable inter-entity attention mechanism. We propose a novel augmented triplet loss function tailored for supervised clustering, which addresses the inherent challenges of directly applying the triplet loss to this problem. Furthermore, we introduce a self-supervised clustering task based on text augmentation techniques to improve the generalization of our model. For evaluation, we collect ground truth clusterings from a closed-source LLM and transfer this knowledge to an open-source LLM under the supervised clustering framework, allowing a faster and cheaper open-source model to perform the same task. Experiments on various e-commerce query and product clustering datasets demonstrate that our proposed approach significantly outperforms existing unsupervised and supervised baselines under various external clustering evaluation metrics.
Geometric Matrix Completion via Sylvester Multi-Graph Neural Network
Jun 19, 2022
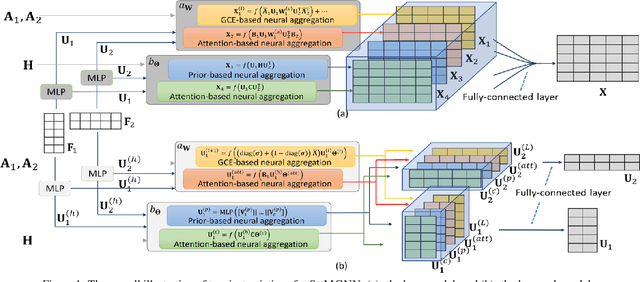
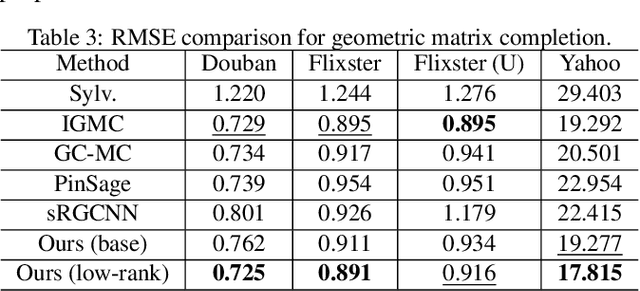
Despite the success of the Sylvester equation empowered methods on various graph mining applications, such as semi-supervised label learning and network alignment, there also exists several limitations. The Sylvester equation's inability of modeling non-linear relations and the inflexibility of tuning towards different tasks restrict its performance. In this paper, we propose an end-to-end neural framework, SYMGNN, which consists of a multi-network neural aggregation module and a prior multi-network association incorporation learning module. The proposed framework inherits the key ideas of the Sylvester equation, and meanwhile generalizes it to overcome aforementioned limitations. Empirical evaluations on real-world datasets show that the instantiations of SYMGNN overall outperform the baselines in geometric matrix completion task, and its low-rank instantiation could further reduce the memory consumption by 16.98\% on average.
Hypergraph Pre-training with Graph Neural Networks
May 23, 2021
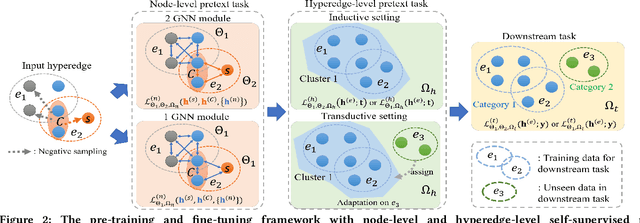
Despite the prevalence of hypergraphs in a variety of high-impact applications, there are relatively few works on hypergraph representation learning, most of which primarily focus on hyperlink prediction, often restricted to the transductive learning setting. Among others, a major hurdle for effective hypergraph representation learning lies in the label scarcity of nodes and/or hyperedges. To address this issue, this paper presents an end-to-end, bi-level pre-training strategy with Graph Neural Networks for hypergraphs. The proposed framework named HyperGene bears three distinctive advantages. First, it is capable of ingesting the labeling information when available, but more importantly, it is mainly designed in the self-supervised fashion which significantly broadens its applicability. Second, at the heart of the proposed HyperGene are two carefully designed pretexts, one on the node level and the other on the hyperedge level, which enable us to encode both the local and the global context in a mutually complementary way. Third, the proposed framework can work in both transductive and inductive settings. When applying the two proposed pretexts in tandem, it can accelerate the adaptation of the knowledge from the pre-trained model to downstream applications in the transductive setting, thanks to the bi-level nature of the proposed method. The extensive experimental results demonstrate that: (1) HyperGene achieves up to 5.69% improvements in hyperedge classification, and (2) improves pre-training efficiency by up to 42.80% on average.
Graph Neural Networks for Inconsistent Cluster Detection in Incremental Entity Resolution
May 12, 2021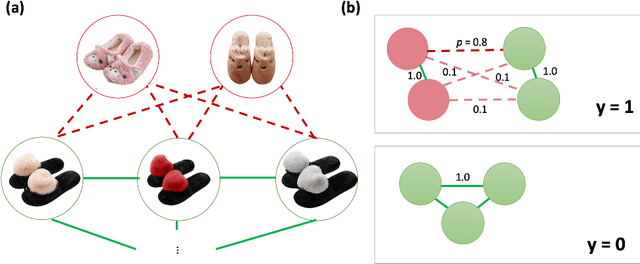
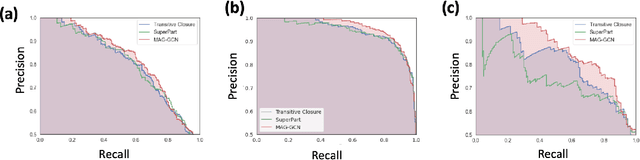
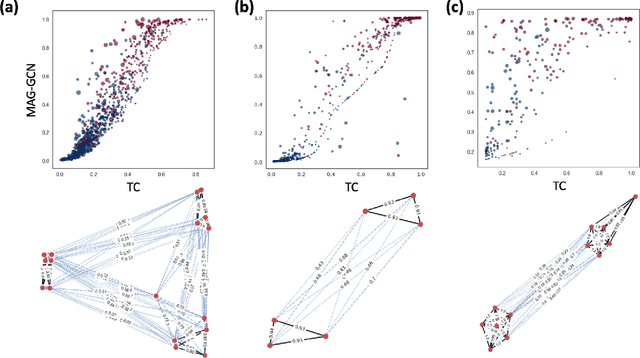
Online stores often utilize product relationships such as bundles and substitutes to improve their catalog quality and guide customers through myriad choices. Entity resolution using pairwise product matching models offers a means of inferring relationships between products. In mature data repositories, the relationships may be mostly correct but require incremental improvements owing to errors in the original data or in the entity resolution system. It is critical to devise incremental entity resolution (IER) approaches for improving the health of relationships. However, most existing research on IER focuses on the addition of new products or information into existing relationships. Relatively little research has been done for detecting low quality within current relationships. This paper proposes a novel method for identifying inconsistent clusters (IC), existing groups of related products that do not belong together. We propose to treat the identification of inconsistent clusters as a supervised learning task which predicts whether a graph of products with similarities as weighted edges should be partitioned into multiple clusters. In this case, the problem becomes a classification task on weighted graphs and represents an interesting application area for modern tools such as Graph Neural Networks (GNNs). We demonstrate that existing Message Passing neural networks perform well at this task, exceeding traditional graph processing techniques. We also develop a novel message aggregation scheme for Message Passing Neural Networks that further improves the performance of GNNs on this task. We apply the model to synthetic datasets, a public benchmark dataset, and an internal application. Our results demonstrate the value of graph classification in IER and the ability of graph neural networks to develop useful representations for graph partitioning.
Most Relevant Explanation in Bayesian Networks
Jan 16, 2014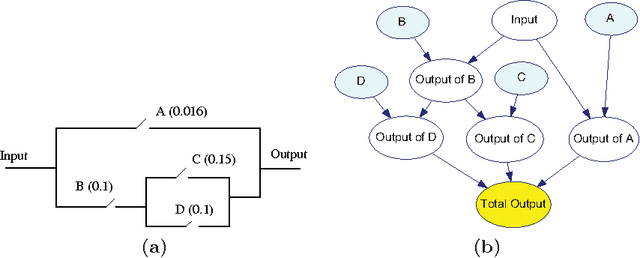
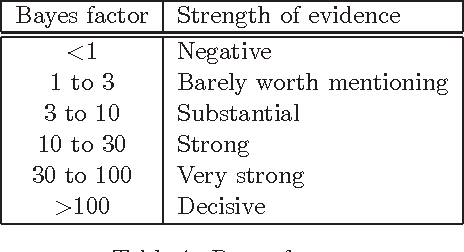
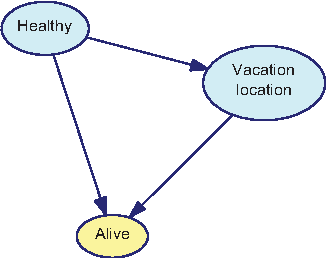

A major inference task in Bayesian networks is explaining why some variables are observed in their particular states using a set of target variables. Existing methods for solving this problem often generate explanations that are either too simple (underspecified) or too complex (overspecified). In this paper, we introduce a method called Most Relevant Explanation (MRE) which finds a partial instantiation of the target variables that maximizes the generalized Bayes factor (GBF) as the best explanation for the given evidence. Our study shows that GBF has several theoretical properties that enable MRE to automatically identify the most relevant target variables in forming its explanation. In particular, conditional Bayes factor (CBF), defined as the GBF of a new explanation conditioned on an existing explanation, provides a soft measure on the degree of relevance of the variables in the new explanation in explaining the evidence given the existing explanation. As a result, MRE is able to automatically prune less relevant variables from its explanation. We also show that CBF is able to capture well the explaining-away phenomenon that is often represented in Bayesian networks. Moreover, we define two dominance relations between the candidate solutions and use the relations to generalize MRE to find a set of top explanations that is both diverse and representative. Case studies on several benchmark diagnostic Bayesian networks show that MRE is often able to find explanatory hypotheses that are not only precise but also concise.
Evaluating Anytime Algorithms for Learning Optimal Bayesian Networks
Sep 26, 2013
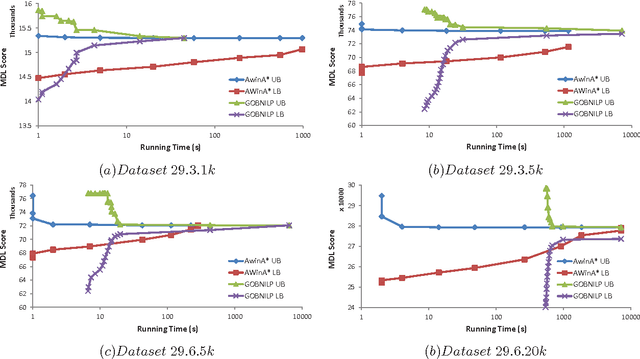
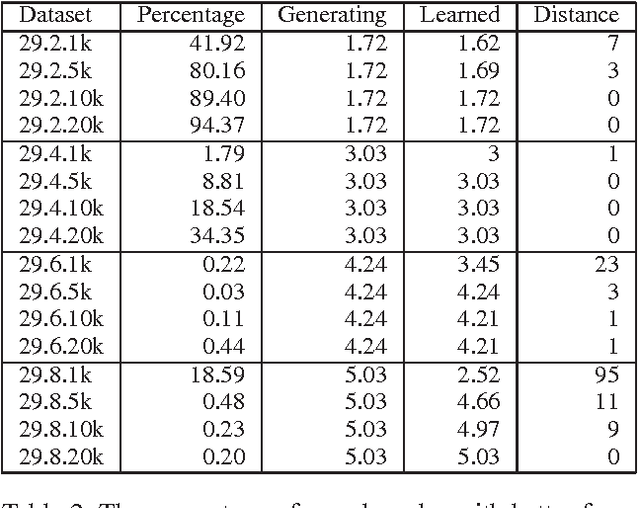
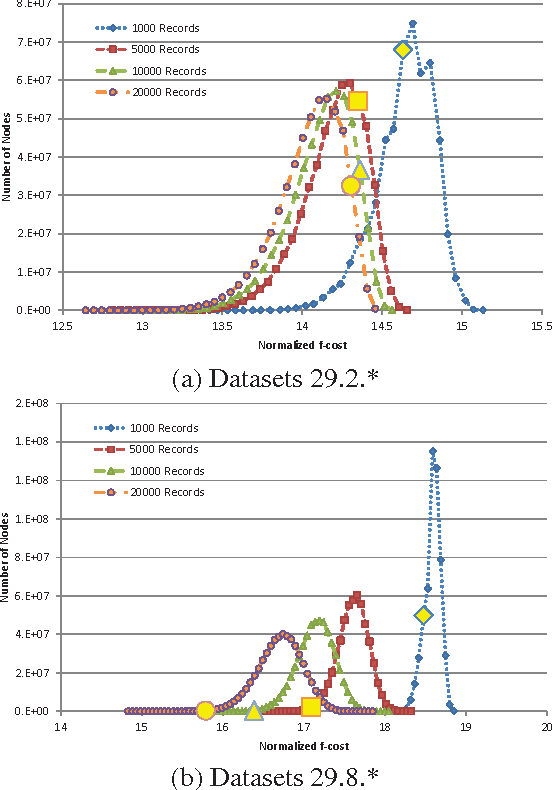
Exact algorithms for learning Bayesian networks guarantee to find provably optimal networks. However, they may fail in difficult learning tasks due to limited time or memory. In this research we adapt several anytime heuristic search-based algorithms to learn Bayesian networks. These algorithms find high-quality solutions quickly, and continually improve the incumbent solution or prove its optimality before resources are exhausted. Empirical results show that the anytime window A* algorithm usually finds higher-quality, often optimal, networks more quickly than other approaches. The results also show that, surprisingly, while generating networks with few parents per variable are structurally simpler, they are harder to learn than complex generating networks with more parents per variable.
Solving Limited-Memory Influence Diagrams Using Branch-and-Bound Search
Sep 26, 2013
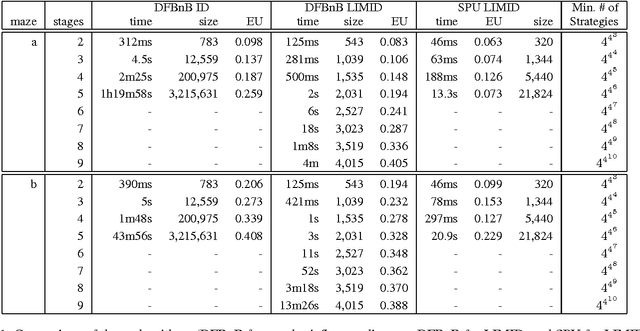
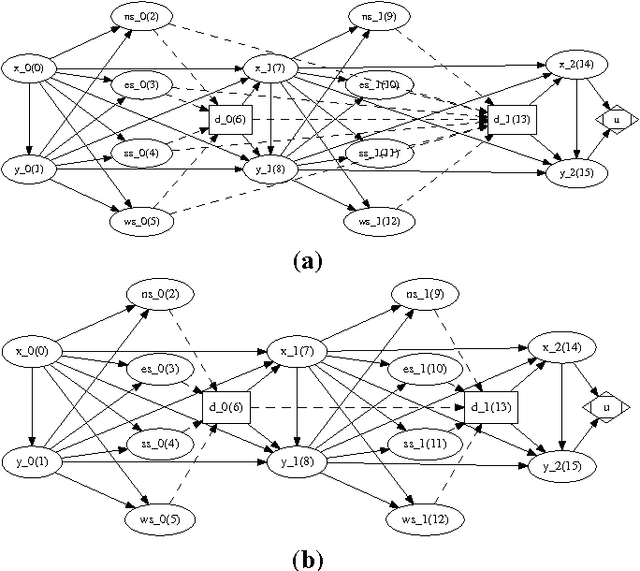
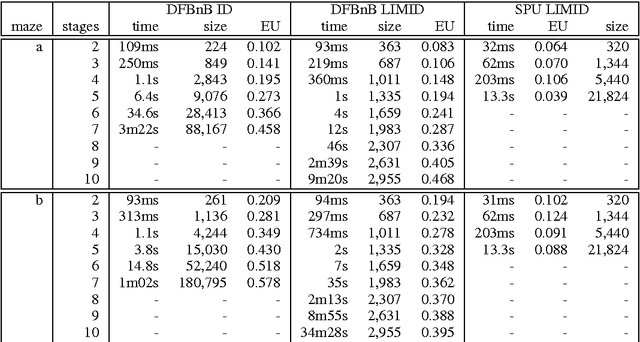
A limited-memory influence diagram (LIMID) generalizes a traditional influence diagram by relaxing the assumptions of regularity and no-forgetting, allowing a wider range of decision problems to be modeled. Algorithms for solving traditional influence diagrams are not easily generalized to solve LIMIDs, however, and only recently have exact algorithms for solving LIMIDs been developed. In this paper, we introduce an exact algorithm for solving LIMIDs that is based on branch-and-bound search. Our approach is related to the approach of solving an influence diagram by converting it to an equivalent decision tree, with the difference that the LIMID is converted to a much smaller decision graph that can be searched more efficiently.
An Importance Sampling Algorithm Based on Evidence Pre-propagation
Oct 19, 2012


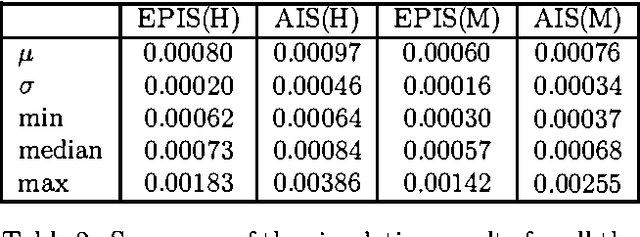
Precision achieved by stochastic sampling algorithms for Bayesian networks typically deteriorates in face of extremely unlikely evidence. To address this problem, we propose the Evidence Pre-propagation Importance Sampling algorithm (EPIS-BN), an importance sampling algorithm that computes an approximate importance function by the heuristic methods: loopy belief Propagation and e-cutoff. We tested the performance of e-cutoff on three large real Bayesian networks: ANDES, CPCS, and PATHFINDER. We observed that on each of these networks the EPIS-BN algorithm gives us a considerable improvement over the current state of the art algorithm, the AIS-BN algorithm. In addition, it avoids the costly learning stage of the AIS-BN algorithm.
An Improved Admissible Heuristic for Learning Optimal Bayesian Networks
Oct 16, 2012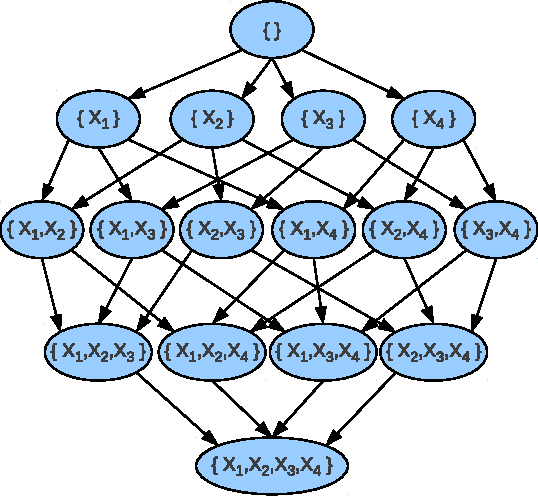

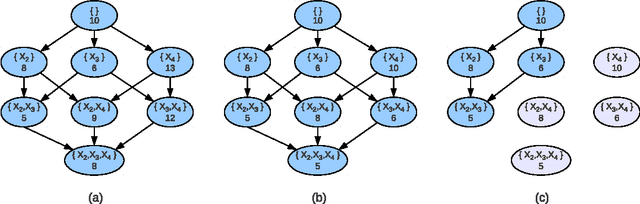
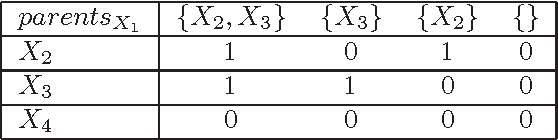
Recently two search algorithms, A* and breadth-first branch and bound (BFBnB), were developed based on a simple admissible heuristic for learning Bayesian network structures that optimize a scoring function. The heuristic represents a relaxation of the learning problem such that each variable chooses optimal parents independently. As a result, the heuristic may contain many directed cycles and result in a loose bound. This paper introduces an improved admissible heuristic that tries to avoid directed cycles within small groups of variables. A sparse representation is also introduced to store only the unique optimal parent choices. Empirical results show that the new techniques significantly improved the efficiency and scalability of A* and BFBnB on most of datasets tested in this paper.
Annealed MAP
Jul 11, 2012
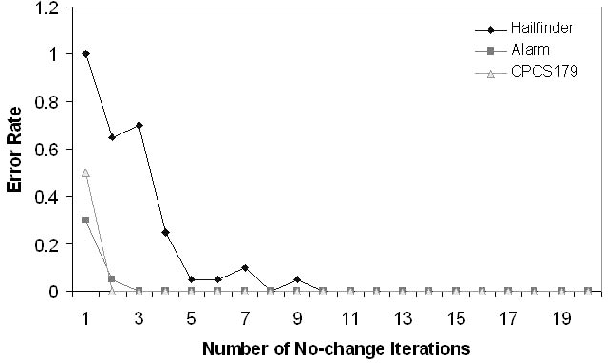
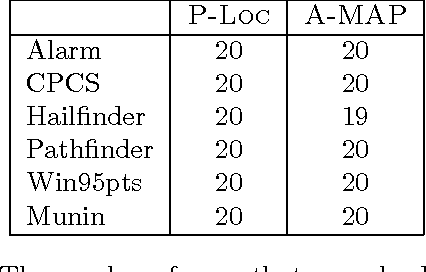
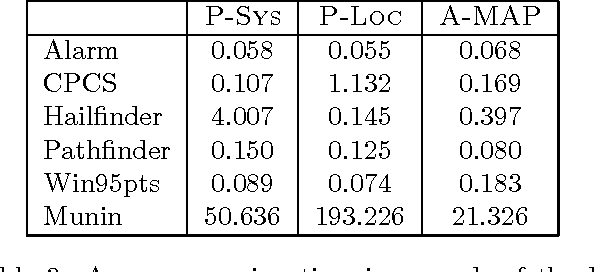
Maximum a Posteriori assignment (MAP) is the problem of finding the most probable instantiation of a set of variables given the partial evidence on the other variables in a Bayesian network. MAP has been shown to be a NP-hard problem [22], even for constrained networks, such as polytrees [18]. Hence, previous approaches often fail to yield any results for MAP problems in large complex Bayesian networks. To address this problem, we propose AnnealedMAP algorithm, a simulated annealing-based MAP algorithm. The AnnealedMAP algorithm simulates a non-homogeneous Markov chain whose invariant function is a probability density that concentrates itself on the modes of the target density. We tested this algorithm on several real Bayesian networks. The results show that, while maintaining good quality of the MAP solutions, the AnnealedMAP algorithm is also able to solve many problems that are beyond the reach of previous approaches.