 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning for T-Cell Response Prediction
Mar 18, 2024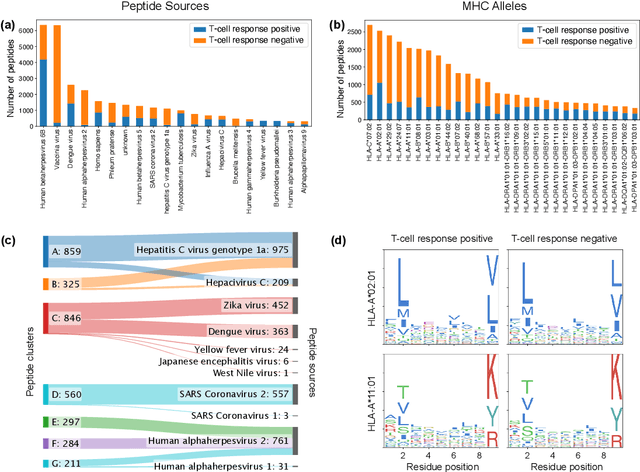



We study the prediction of T-cell response for specific given peptides, which could, among other applications, be a crucial step towards the development of personalized cancer vaccines. It is a challenging task due to limited, heterogeneous training data featuring a multi-domain structure; such data entail the danger of shortcut learning, where models learn general characteristics of peptide sources, such as the source organism, rather than specific peptide characteristics associated with T-cell response. Using a transformer model for T-cell response prediction, we show that the danger of inflated predictive performance is not merely theoretical but occurs in practice. Consequently, we propose a domain-aware evaluation scheme. We then study different transfer learning techniques to deal with the multi-domain structure and shortcut learning. We demonstrate a per-source fine tuning approach to be effective across a wide range of peptide sources and further show that our final model outperforms existing state-of-the-art approaches for predicting T-cell responses for human peptides.
A Relational-learning Perspective to Multi-label Chest X-ray Classification
Mar 10, 2021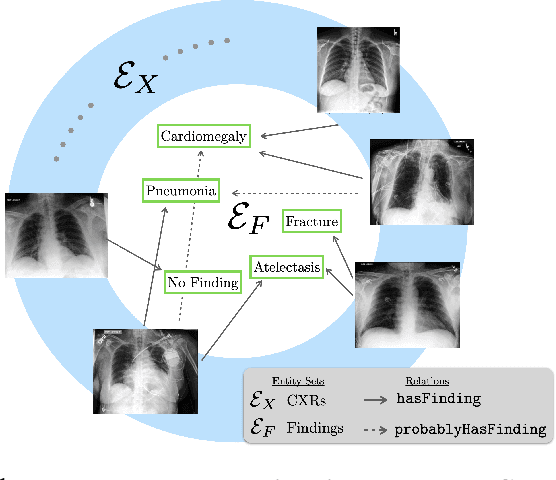
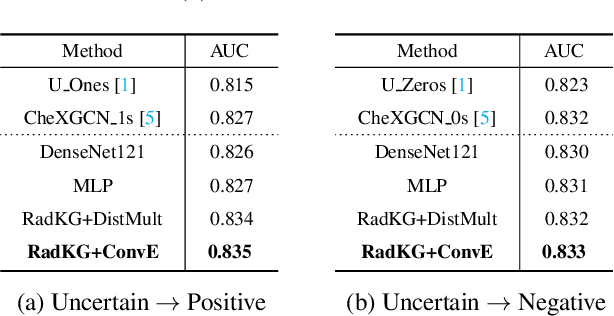
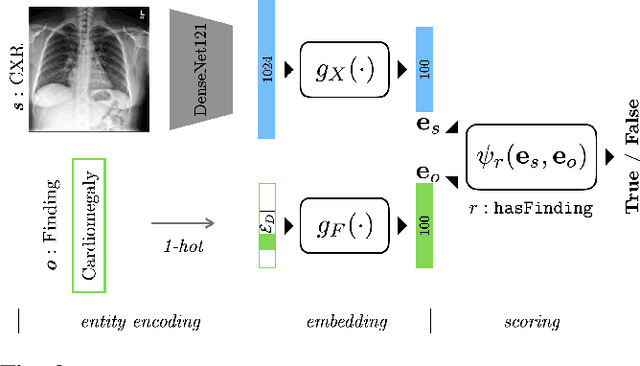
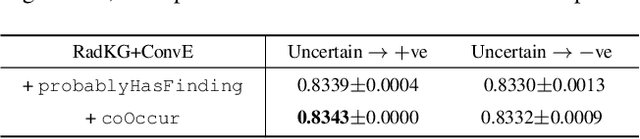
Multi-label classification of chest X-ray images is frequently performed using discriminative approaches, i.e. learning to map an image directly to its binary labels. Such approaches make it challenging to incorporate auxiliary information such as annotation uncertainty or a dependency among the labels. Building towards this, we propose a novel knowledge graph reformulation of multi-label classification, which not only readily increases predictive performance of an encoder but also serves as a general framework for introducing new domain knowledge. Specifically, we construct a multi-modal knowledge graph out of the chest X-ray images and its labels and pose multi-label classification as a link prediction problem. Incorporating auxiliary information can then simply be achieved by adding additional nodes and relations among them. When tested on a publicly-available radiograph dataset (CheXpert), our relational-reformulation using a naive knowledge graph outperforms the state-of-art by achieving an area-under-ROC curve of 83.5%, an improvement of "sim 1" over a purely discriminative approach.
Learning Representations of Missing Data for Predicting Patient Outcomes
Nov 12, 2018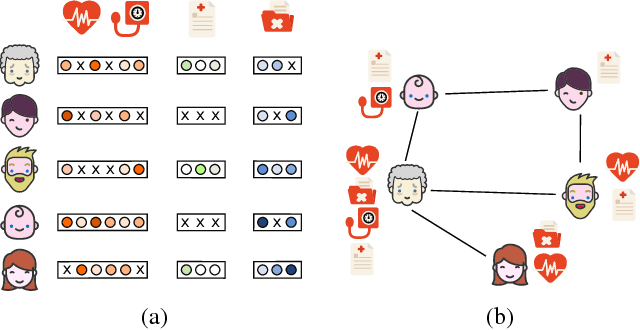
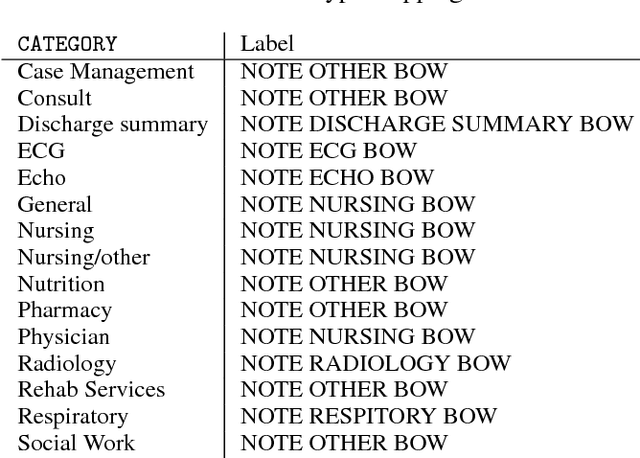
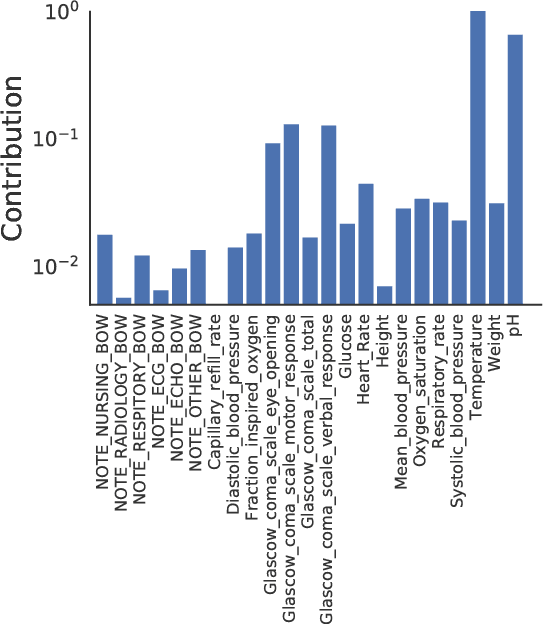
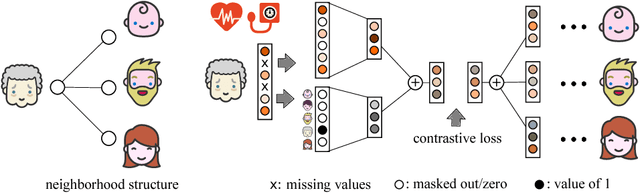
Extracting actionable insight from Electronic Health Records (EHRs) poses several challenges for traditional machine learning approaches. Patients are often missing data relative to each other; the data comes in a variety of modalities, such as multivariate time series, free text, and categorical demographic information; important relationships among patients can be difficult to detect; and many others. In this work, we propose a novel approach to address these first three challenges using a representation learning scheme based on message passing. We show that our proposed approach is competitive with or outperforms the state of the art for predicting in-hospital mortality (binary classification), the length of hospital visits (regression) and the discharge destination (multiclass classification).
Knowledge Graph Completion to Predict Polypharmacy Side Effects
Oct 22, 2018

The polypharmacy side effect prediction problem considers cases in which two drugs taken individually do not result in a particular side effect; however, when the two drugs are taken in combination, the side effect manifests. In this work, we demonstrate that multi-relational knowledge graph completion achieves state-of-the-art results on the polypharmacy side effect prediction problem. Empirical results show that our approach is particularly effective when the protein targets of the drugs are well-characterized. In contrast to prior work, our approach provides more interpretable predictions and hypotheses for wet lab validation.
Evaluating Anytime Algorithms for Learning Optimal Bayesian Networks
Sep 26, 2013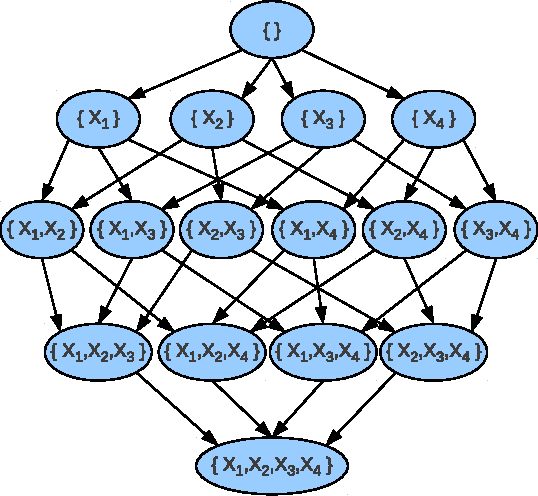
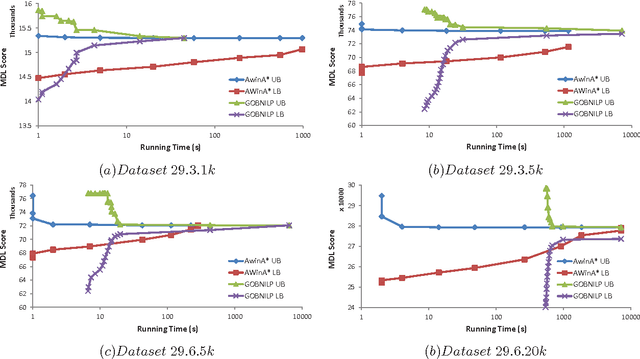
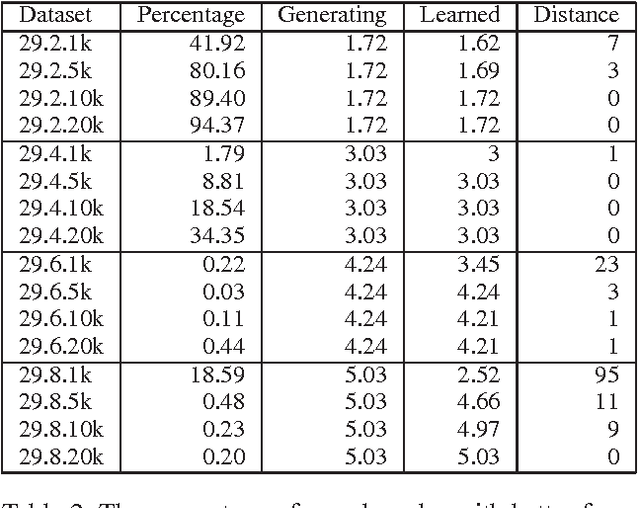
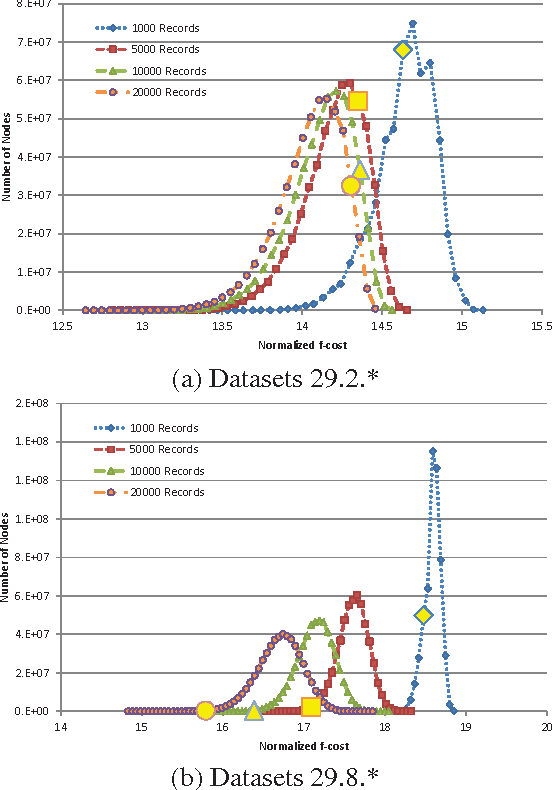
Exact algorithms for learning Bayesian networks guarantee to find provably optimal networks. However, they may fail in difficult learning tasks due to limited time or memory. In this research we adapt several anytime heuristic search-based algorithms to learn Bayesian networks. These algorithms find high-quality solutions quickly, and continually improve the incumbent solution or prove its optimality before resources are exhausted. Empirical results show that the anytime window A* algorithm usually finds higher-quality, often optimal, networks more quickly than other approaches. The results also show that, surprisingly, while generating networks with few parents per variable are structurally simpler, they are harder to learn than complex generating networks with more parents per variable.
An Improved Admissible Heuristic for Learning Optimal Bayesian Networks
Oct 16, 2012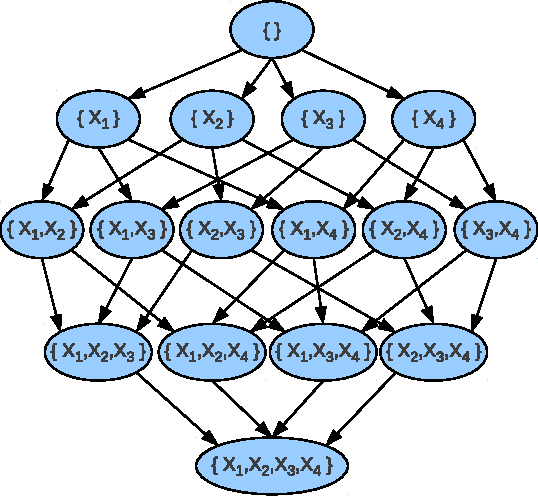

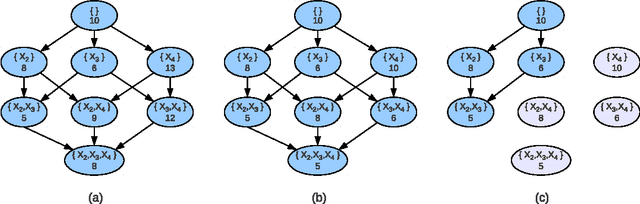
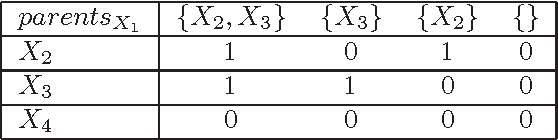
Recently two search algorithms, A* and breadth-first branch and bound (BFBnB), were developed based on a simple admissible heuristic for learning Bayesian network structures that optimize a scoring function. The heuristic represents a relaxation of the learning problem such that each variable chooses optimal parents independently. As a result, the heuristic may contain many directed cycles and result in a loose bound. This paper introduces an improved admissible heuristic that tries to avoid directed cycles within small groups of variables. A sparse representation is also introduced to store only the unique optimal parent choices. Empirical results show that the new techniques significantly improved the efficiency and scalability of A* and BFBnB on most of datasets tested in this paper.
Improving the Scalability of Optimal Bayesian Network Learning with External-Memory Frontier Breadth-First Branch and Bound Search
Feb 14, 2012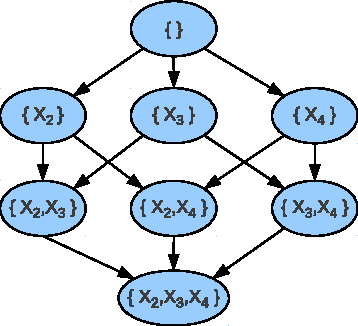
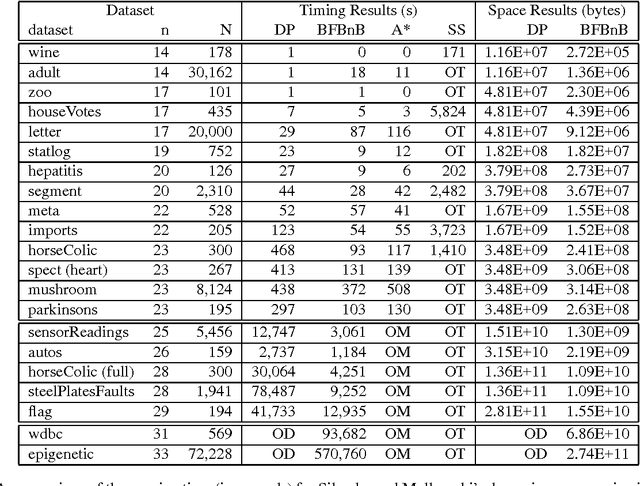
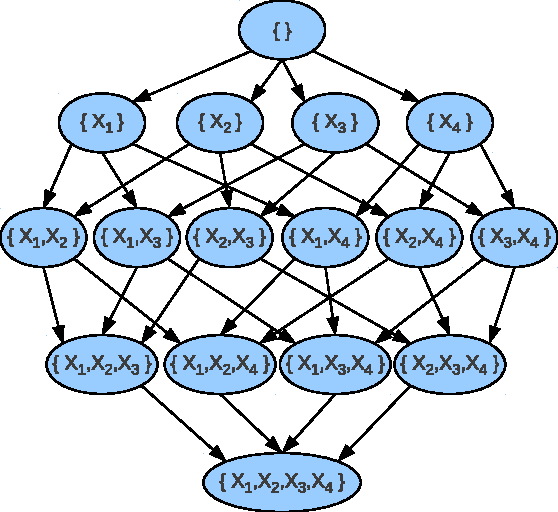
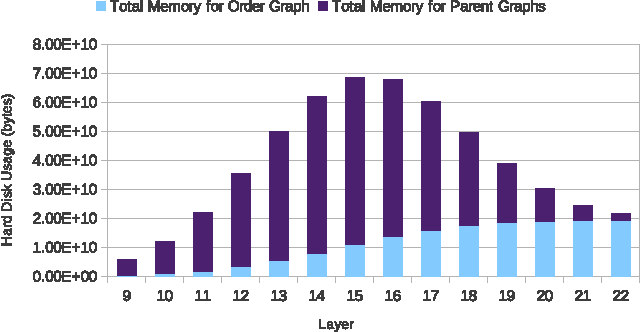
Previous work has shown that the problem of learning the optimal structure of a Bayesian network can be formulated as a shortest path finding problem in a graph and solved using A* search. In this paper, we improve the scalability of this approach by developing a memory-efficient heuristic search algorithm for learning the structure of a Bayesian network. Instead of using A*, we propose a frontier breadth-first branch and bound search that leverages the layered structure of the search graph of this problem so that no more than two layers of the graph, plus solution reconstruction information, need to be stored in memory at a time. To further improve scalability, the algorithm stores most of the graph in external memory, such as hard disk, when it does not fit in RAM. Experimental results show that the resulting algorithm solves significantly larger problems than the current state of the art.