 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Entity Candidate Generation for Low-Resource Languages
Jun 30, 2022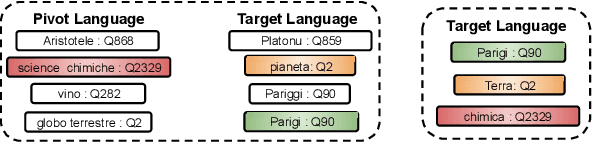
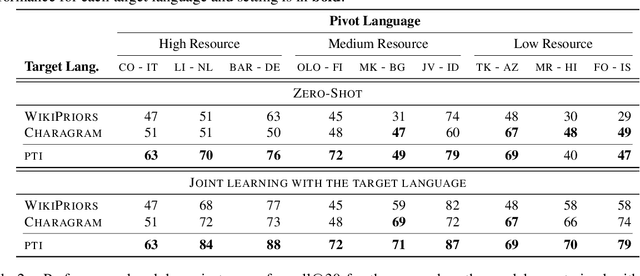
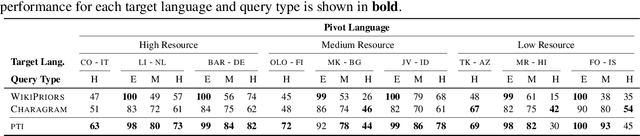
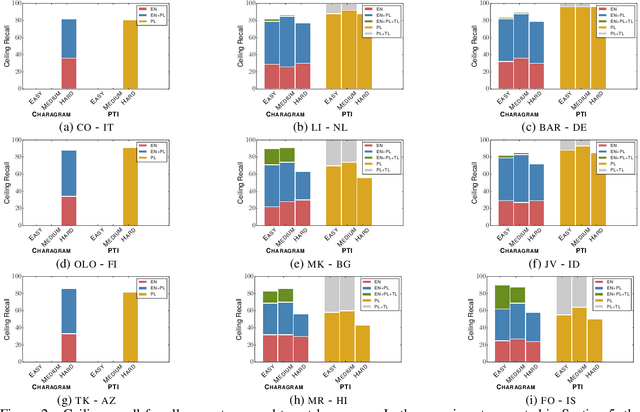
Candidate generation is a crucial module in entity linking. It also plays a key role in multiple NLP tasks that have been proven to beneficially leverage knowledge bases. Nevertheless, it has often been overlooked in the monolingual English entity linking literature, as naive approaches obtain very good performance. Unfortunately, the existing approaches for English cannot be successfully transferred to poorly resourced languages. This paper constitutes an in-depth analysis of the candidate generation problem in the context of cross-lingual entity linking with a focus on low-resource languages. Among other contributions, we point out limitations in the evaluation conducted in previous works. We introduce a characterization of queries into types based on their difficulty, which improves the interpretability of the performance of different methods. We also propose a light-weight and simple solution based on the construction of indexes whose design is motivated by more complex transfer learning based neural approaches. A thorough empirical analysis on 9 real-world datasets under 2 evaluation settings shows that our simple solution outperforms the state-of-the-art approach in terms of both quality and efficiency for almost all datasets and query types.
Recursive input and state estimation: A general framework for learning from time series with missing data
Apr 17, 2021



Time series with missing data are signals encountered in important settings for machine learning. Some of the most successful prior approaches for modeling such time series are based on recurrent neural networks that transform the input and previous state to account for the missing observations, and then treat the transformed signal in a standard manner. In this paper, we introduce a single unifying framework, Recursive Input and State Estimation (RISE), for this general approach and reformulate existing models as specific instances of this framework. We then explore additional novel variations within the RISE framework to improve the performance of any instance. We exploit representation learning techniques to learn latent representations of the signals used by RISE instances. We discuss and develop various encoding techniques to learn latent signal representations. We benchmark instances of the framework with various encoding functions on three data imputation datasets, observing that RISE instances always benefit from encoders that learn representations for numerical values from the digits into which they can be decomposed.
Knowledge Graph Completion to Predict Polypharmacy Side Effects
Oct 22, 2018

The polypharmacy side effect prediction problem considers cases in which two drugs taken individually do not result in a particular side effect; however, when the two drugs are taken in combination, the side effect manifests. In this work, we demonstrate that multi-relational knowledge graph completion achieves state-of-the-art results on the polypharmacy side effect prediction problem. Empirical results show that our approach is particularly effective when the protein targets of the drugs are well-characterized. In contrast to prior work, our approach provides more interpretable predictions and hypotheses for wet lab validation.
Learning Sequence Encoders for Temporal Knowledge Graph Completion
Sep 10, 2018



Research on link prediction in knowledge graphs has mainly focused on static multi-relational data. In this work we consider temporal knowledge graphs where relations between entities may only hold for a time interval or a specific point in time. In line with previous work on static knowledge graphs, we propose to address this problem by learning latent entity and relation type representations. To incorporate temporal information, we utilize recurrent neural networks to learn time-aware representations of relation types which can be used in conjunction with existing latent factorization methods. The proposed approach is shown to be robust to common challenges in real-world KGs: the sparsity and heterogeneity of temporal expressions. Experiments show the benefits of our approach on four temporal KGs. The data sets are available under a permissive BSD-3 license 1.
Representation Learning for Visual-Relational Knowledge Graphs
Mar 31, 2018


A visual-relational knowledge graph (KG) is a multi-relational graph whose entities are associated with images. We introduce ImageGraph, a KG with 1,330 relation types, 14,870 entities, and 829,931 images. Visual-relational KGs lead to novel probabilistic query types where images are treated as first-class citizens. Both the prediction of relations between unseen images and multi-relational image retrieval can be formulated as query types in a visual-relational KG. We approach the problem of answering such queries with a novel combination of deep convolutional networks and models for learning knowledge graph embeddings. The resulting models can answer queries such as "How are these two unseen images related to each other?" We also explore a zero-shot learning scenario where an image of an entirely new entity is linked with multiple relations to entities of an existing KG. The multi-relational grounding of unseen entity images into a knowledge graph serves as the description of such an entity. We conduct experiments to demonstrate that the proposed deep architectures in combination with KG embedding objectives can answer the visual-relational queries efficiently and accurately.
Generating Factoid Questions With Recurrent Neural Networks: The 30M Factoid Question-Answer Corpus
May 29, 2016



Over the past decade, large-scale supervised learning corpora have enabled machine learning researchers to make substantial advances. However, to this date, there are no large-scale question-answer corpora available. In this paper we present the 30M Factoid Question-Answer Corpus, an enormous question answer pair corpus produced by applying a novel neural network architecture on the knowledge base Freebase to transduce facts into natural language questions. The produced question answer pairs are evaluated both by human evaluators and using automatic evaluation metrics, including well-established machine translation and sentence similarity metrics. Across all evaluation criteria the question-generation model outperforms the competing template-based baseline. Furthermore, when presented to human evaluators, the generated questions appear comparable in quality to real human-generated questions.