 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIVERGE: Diversity-Enhanced RAG for Open-Ended Information Seeking
Jan 30, 2026Existing retrieval-augmented generation (RAG) systems are primarily designed under the assumption that each query has a single correct answer. This overlooks common information-seeking scenarios with multiple plausible answers, where diversity is essential to avoid collapsing to a single dominant response, thereby constraining creativity and compromising fair and inclusive information access. Our analysis reveals a commonly overlooked limitation of standard RAG systems: they underutilize retrieved context diversity, such that increasing retrieval diversity alone does not yield diverse generations. To address this limitation, we propose DIVERGE, a plug-and-play agentic RAG framework with novel reflection-guided generation and memory-augmented iterative refinement, which promotes diverse viewpoints while preserving answer quality. We introduce novel metrics tailored to evaluating the diversity-quality trade-off in open-ended questions, and show that they correlate well with human judgments. We demonstrate that DIVERGE achieves the best diversity-quality trade-off compared to competitive baselines and previous state-of-the-art methods on the real-world Infinity-Chat dataset, substantially improving diversity while maintaining quality. More broadly, our results reveal a systematic limitation of current LLM-based systems for open-ended information-seeking and show that explicitly modeling diversity can mitigate it. Our code is available at: https://github.com/au-clan/Diverge
ReasonBENCH: Benchmarking the (In)Stability of LLM Reasoning
Dec 08, 2025Large language models (LLMs) are increasingly deployed in settings where reasoning, such as multi-step problem solving and chain-of-thought, is essential. Yet, current evaluation practices overwhelmingly report single-run accuracy while ignoring the intrinsic uncertainty that naturally arises from stochastic decoding. This omission creates a blind spot because practitioners cannot reliably assess whether a method's reported performance is stable, reproducible, or cost-consistent. We introduce ReasonBENCH, the first benchmark designed to quantify the underlying instability in LLM reasoning. ReasonBENCH provides (i) a modular evaluation library that standardizes reasoning frameworks, models, and tasks, (ii) a multi-run protocol that reports statistically reliable metrics for both quality and cost, and (iii) a public leaderboard to encourage variance-aware reporting. Across tasks from different domains, we find that the vast majority of reasoning strategies and models exhibit high instability. Notably, even strategies with similar average performance can display confidence intervals up to four times wider, and the top-performing methods often incur higher and less stable costs. Such instability compromises reproducibility across runs and, consequently, the reliability of reported performance. To better understand these dynamics, we further analyze the impact of prompts, model families, and scale on the trade-off between solve rate and stability. Our results highlight reproducibility as a critical dimension for reliable LLM reasoning and provide a foundation for future reasoning methods and uncertainty quantification techniques. ReasonBENCH is publicly available at https://github.com/au-clan/ReasonBench .
Are Retrials All You Need? Enhancing Large Language Model Reasoning Without Verbalized Feedback
Apr 17, 2025Recent advancements in large language models (LLMs) have catalyzed the development of general-purpose autonomous agents, demonstrating remarkable performance in complex reasoning tasks across various domains. This surge has spurred the evolution of a plethora of prompt-based reasoning frameworks. A recent focus has been on iterative reasoning strategies that refine outputs through self-evaluation and verbalized feedback. However, these strategies require additional computational complexity to enable models to recognize and correct their mistakes, leading to a significant increase in their cost. In this work, we introduce the concept of ``retrials without feedback'', an embarrassingly simple yet powerful mechanism for enhancing reasoning frameworks by allowing LLMs to retry problem-solving attempts upon identifying incorrect answers. Unlike conventional iterative refinement methods, our method does not require explicit self-reflection or verbalized feedback, simplifying the refinement process. Our findings indicate that simpler retrial-based approaches often outperform more sophisticated reasoning frameworks, suggesting that the benefits of complex methods may not always justify their computational costs. By challenging the prevailing assumption that more intricate reasoning strategies inherently lead to better performance, our work offers new insights into how simpler, more efficient approaches can achieve optimal results. So, are retrials all you need?
Entity Insertion in Multilingual Linked Corpora: The Case of Wikipedia
Oct 05, 2024

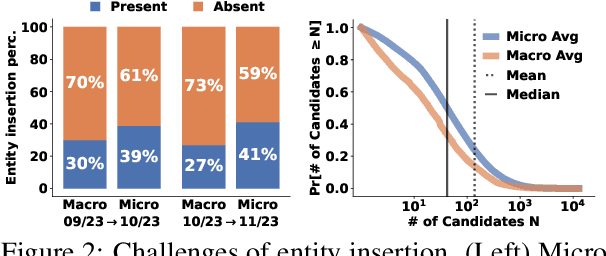

Links are a fundamental part of information networks, turning isolated pieces of knowledge into a network of information that is much richer than the sum of its parts. However, adding a new link to the network is not trivial: it requires not only the identification of a suitable pair of source and target entities but also the understanding of the content of the source to locate a suitable position for the link in the text. The latter problem has not been addressed effectively, particularly in the absence of text spans in the source that could serve as anchors to insert a link to the target entity. To bridge this gap, we introduce and operationalize the task of entity insertion in information networks. Focusing on the case of Wikipedia, we empirically show that this problem is, both, relevant and challenging for editors. We compile a benchmark dataset in 105 languages and develop a framework for entity insertion called LocEI (Localized Entity Insertion) and its multilingual variant XLocEI. We show that XLocEI outperforms all baseline models (including state-of-the-art prompt-based ranking with LLMs such as GPT-4) and that it can be applied in a zero-shot manner on languages not seen during training with minimal performance drop. These findings are important for applying entity insertion models in practice, e.g., to support editors in adding links across the more than 300 language versions of Wikipedia.
Fleet of Agents: Coordinated Problem Solving with Large Language Models using Genetic Particle Filtering
May 07, 2024



Large language models (LLMs) have significantly evolved, moving from simple output generation to complex reasoning and from stand-alone usage to being embedded into broader frameworks. In this paper, we introduce \emph{Fleet of Agents (FoA)}, a novel framework utilizing LLMs as agents to navigate through dynamic tree searches, employing a genetic-type particle filtering approach. FoA spawns a multitude of agents, each exploring autonomously, followed by a selection phase where resampling based on a heuristic value function optimizes the balance between exploration and exploitation. This mechanism enables dynamic branching, adapting the exploration strategy based on discovered solutions. We experimentally validate FoA using two benchmark tasks, "Game of 24" and "Mini-Crosswords". FoA outperforms the previously proposed Tree-of-Thoughts method in terms of efficacy and efficiency: it significantly decreases computational costs (by calling the value function less frequently) while preserving comparable or even superior accuracy.
Generating Faithful Synthetic Data with Large Language Models: A Case Study in Computational Social Science
May 24, 2023Large Language Models (LLMs) have democratized synthetic data generation, which in turn has the potential to simplify and broaden a wide gamut of NLP tasks. Here, we tackle a pervasive problem in synthetic data generation: its generative distribution often differs from the distribution of real-world data researchers care about (in other words, it is unfaithful). In a case study on sarcasm detection, we study three strategies to increase the faithfulness of synthetic data: grounding, filtering, and taxonomy-based generation. We evaluate these strategies using the performance of classifiers trained with generated synthetic data on real-world data. While all three strategies improve the performance of classifiers, we find that grounding works best for the task at hand. As synthetic data generation plays an ever-increasing role in NLP research, we expect this work to be a stepping stone in improving its utility. We conclude this paper with some recommendations on how to generate high(er)-fidelity synthetic data for specific tasks.
Quote Erat Demonstrandum: A Web Interface for Exploring the Quotebank Corpus
Jul 07, 2022
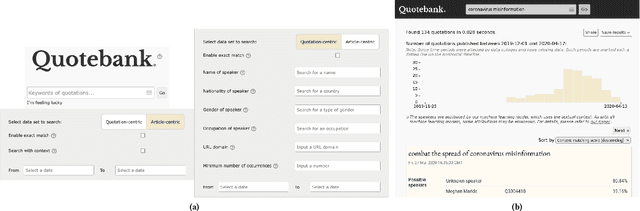
The use of attributed quotes is the most direct and least filtered pathway of information propagation in news. Consequently, quotes play a central role in the conception, reception, and analysis of news stories. Since quotes provide a more direct window into a speaker's mind than regular reporting, they are a valuable resource for journalists and researchers alike. While substantial research efforts have been devoted to methods for the automated extraction of quotes from news and their attribution to speakers, few comprehensive corpora of attributed quotes from contemporary sources are available to the public. Here, we present an adaptive web interface for searching Quotebank, a massive collection of quotes from the news, which we make available at https://quotebank.dlab.tools.
Strong Heuristics for Named Entity Linking
Jul 06, 2022



Named entity linking (NEL) in news is a challenging endeavour due to the frequency of unseen and emerging entities, which necessitates the use of unsupervised or zero-shot methods. However, such methods tend to come with caveats, such as no integration of suitable knowledge bases (like Wikidata) for emerging entities, a lack of scalability, and poor interpretability. Here, we consider person disambiguation in Quotebank, a massive corpus of speaker-attributed quotations from the news, and investigate the suitability of intuitive, lightweight, and scalable heuristics for NEL in web-scale corpora. Our best performing heuristic disambiguates 94% and 63% of the mentions on Quotebank and the AIDA-CoNLL benchmark, respectively. Additionally, the proposed heuristics compare favourably to the state-of-the-art unsupervised and zero-shot methods, Eigenthemes and mGENRE, respectively, thereby serving as strong baselines for unsupervised and zero-shot entity linking.
Efficient Entity Candidate Generation for Low-Resource Languages
Jun 30, 2022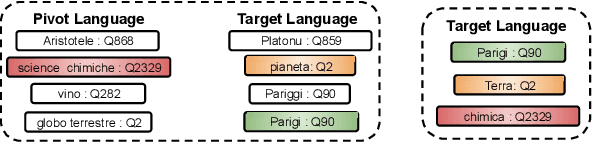
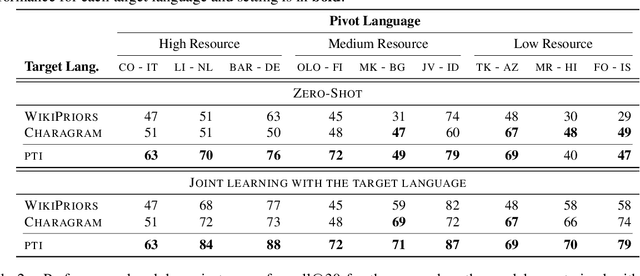
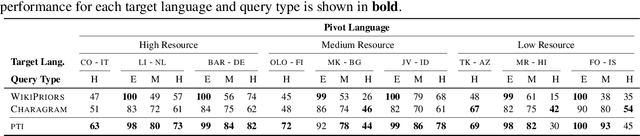
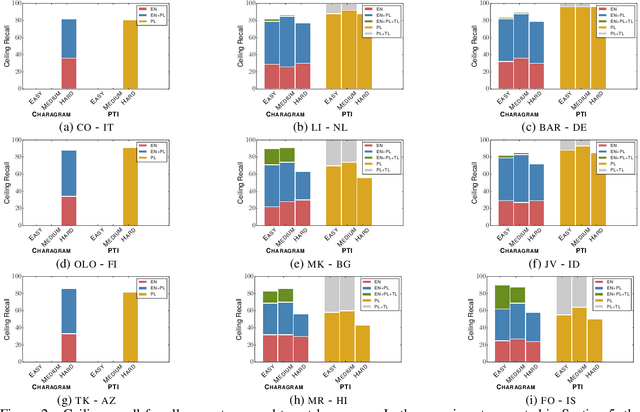
Candidate generation is a crucial module in entity linking. It also plays a key role in multiple NLP tasks that have been proven to beneficially leverage knowledge bases. Nevertheless, it has often been overlooked in the monolingual English entity linking literature, as naive approaches obtain very good performance. Unfortunately, the existing approaches for English cannot be successfully transferred to poorly resourced languages. This paper constitutes an in-depth analysis of the candidate generation problem in the context of cross-lingual entity linking with a focus on low-resource languages. Among other contributions, we point out limitations in the evaluation conducted in previous works. We introduce a characterization of queries into types based on their difficulty, which improves the interpretability of the performance of different methods. We also propose a light-weight and simple solution based on the construction of indexes whose design is motivated by more complex transfer learning based neural approaches. A thorough empirical analysis on 9 real-world datasets under 2 evaluation settings shows that our simple solution outperforms the state-of-the-art approach in terms of both quality and efficiency for almost all datasets and query types.
Low-rank Subspaces for Unsupervised Entity Linking
Apr 18, 2021
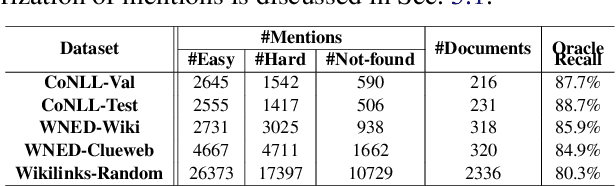
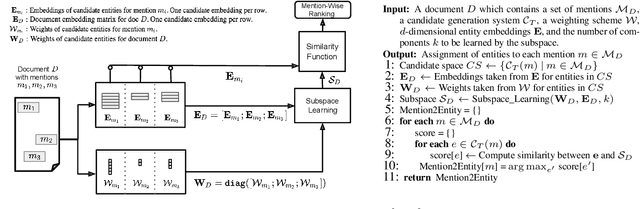
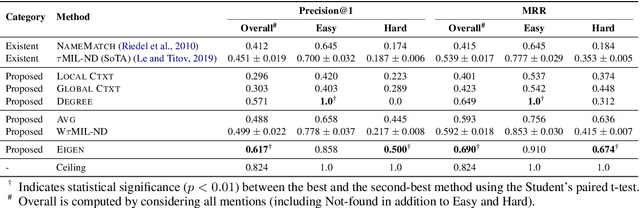
Entity linking is an important problem with many applications. Most previous solutions were designed for settings where annotated training data is available, which is, however, not the case in numerous domains. We propose a light-weight and scalable entity linking method, Eigenthemes, that relies solely on the availability of entity names and a referent knowledge base. Eigenthemes exploits the fact that the entities that are truly mentioned in a document (the "gold entities") tend to form a semantically dense subset of the set of all candidate entities in the document. Geometrically speaking, when representing entities as vectors via some given embedding, the gold entities tend to lie in a low-rank subspace of the full embedding space. Eigenthemes identifies this subspace using the singular value decomposition and scores candidate entities according to their proximity to the subspace. On the empirical front, we introduce multiple strong baselines that compare favorably to the existing state of the art. Extensive experiments on benchmark datasets from a variety of real-world domains showcase the effectiveness of our approach.