 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuote Erat Demonstrandum: A Web Interface for Exploring the Quotebank Corpus
Jul 07, 2022
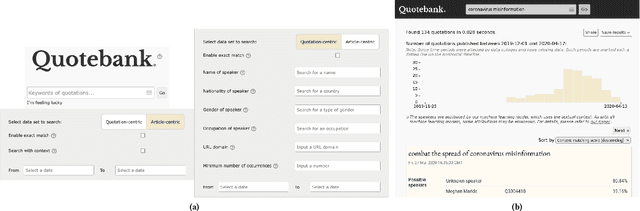
The use of attributed quotes is the most direct and least filtered pathway of information propagation in news. Consequently, quotes play a central role in the conception, reception, and analysis of news stories. Since quotes provide a more direct window into a speaker's mind than regular reporting, they are a valuable resource for journalists and researchers alike. While substantial research efforts have been devoted to methods for the automated extraction of quotes from news and their attribution to speakers, few comprehensive corpora of attributed quotes from contemporary sources are available to the public. Here, we present an adaptive web interface for searching Quotebank, a massive collection of quotes from the news, which we make available at https://quotebank.dlab.tools.
ODSQA: Open-domain Spoken Question Answering Dataset
Aug 07, 2018


Reading comprehension by machine has been widely studied, but machine comprehension of spoken content is still a less investigated problem. In this paper, we release Open-Domain Spoken Question Answering Dataset (ODSQA) with more than three thousand questions. To the best of our knowledge, this is the largest real SQA dataset. On this dataset, we found that ASR errors have catastrophic impact on SQA. To mitigate the effect of ASR errors, subword units are involved, which brings consistent improvements over all the models. We further found that data augmentation on text-based QA training examples can improve SQA.