 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCritique-Guided Distillation: Improving Supervised Fine-tuning via Better Distillation
May 16, 2025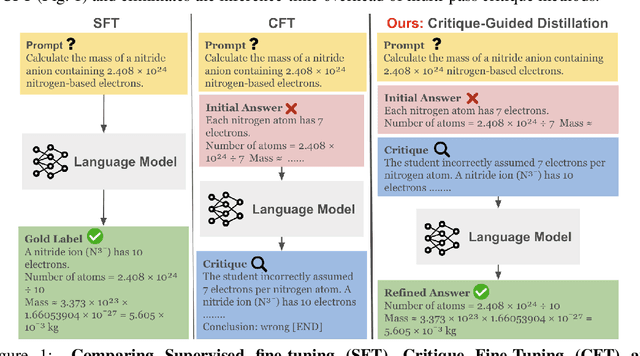



Supervised fine-tuning (SFT) using expert demonstrations often suffer from the imitation problem, where the model learns to reproduce the correct responses without \emph{understanding} the underlying rationale. To address this limitation, we propose \textsc{Critique-Guided Distillation (CGD)}, a novel multi-stage framework that integrates teacher model generated \emph{explanatory critiques} and \emph{refined responses} into the SFT process. A student model is then trained to map the triplet of prompt, teacher critique, and its own initial response to the corresponding refined teacher response, thereby learning both \emph{what} to imitate and \emph{why}. Using entropy-based analysis, we show that \textsc{CGD} reduces refinement uncertainty and can be interpreted as a Bayesian posterior update. We perform extensive empirical evaluation of \textsc{CGD}, on variety of benchmark tasks, and demonstrate significant gains on both math (AMC23 +17.5%) and language understanding tasks (MMLU-Pro +6.3%), while successfully mitigating the format drift issues observed in previous critique fine-tuning (CFT) techniques.
CorrectionLM: Self-Corrections with SLM for Dialogue State Tracking
Oct 23, 2024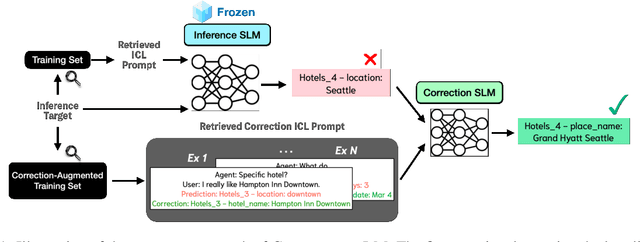


Large language models (LLMs) have demonstrated self-improvement capabilities via feedback and refinement, but current small language models (SLMs) have had limited success in this area. Existing correction approaches often rely on distilling knowledge from LLMs, which imposes significant computation demands. In this work, we introduce CORRECTIONLM, a novel correction framework that enables SLMs to self-correct using in-context exemplars without LLM involvement. Applied to two dialogue state tracking (DST) tasks in low-resource settings, CORRECTIONLM achieves results similar to a state-of-the-art LLM at a small fraction of the computation costs.
OrchestraLLM: Efficient Orchestration of Language Models for Dialogue State Tracking
Nov 16, 2023



Large language models (LLMs) have revolutionized the landscape of Natural Language Processing systems, but are computationally expensive. To reduce the cost without sacrificing performance, previous studies have explored various approaches to harness the potential of Small Language Models (SLMs) as cost-effective alternatives to their larger counterparts. Driven by findings that SLMs and LLMs exhibit complementary strengths in a structured knowledge extraction task, this work presents a novel SLM/LLM routing framework designed to improve computational efficiency and enhance task performance. First, exemplar pools are created to represent the types of contexts where each LM provides a more reliable answer, leveraging a sentence embedding fine-tuned so that context similarity is close to dialogue state similarity. Then, during inference, the k-nearest exemplars to the testing instance are retrieved, and the instance is routed according to majority vote. In dialogue state tracking tasks, the proposed routing framework enhances performance substantially compared to relying solely on LLMs, while reducing the computational costs by over 50%.
DIALGEN: Collaborative Human-LM Generated Dialogues for Improved Understanding of Human-Human Conversations
Jul 13, 2023



Applications that could benefit from automatic understanding of human-human conversations often come with challenges associated with private information in real-world data such as call center or clinical conversations. Working with protected data also increases costs of annotation, which limits technology development. To address these challenges, we propose DIALGEN, a human-in-the-loop semi-automated dialogue generation framework. DIALGEN uses a language model (ChatGPT) that can follow schema and style specifications to produce fluent conversational text, generating a complex conversation through iteratively generating subdialogues and using human feedback to correct inconsistencies or redirect the flow. In experiments on structured summarization of agent-client information gathering calls, framed as dialogue state tracking, we show that DIALGEN data enables significant improvement in model performance.
MIA 2022 Shared Task: Evaluating Cross-lingual Open-Retrieval Question Answering for 16 Diverse Languages
Jul 02, 2022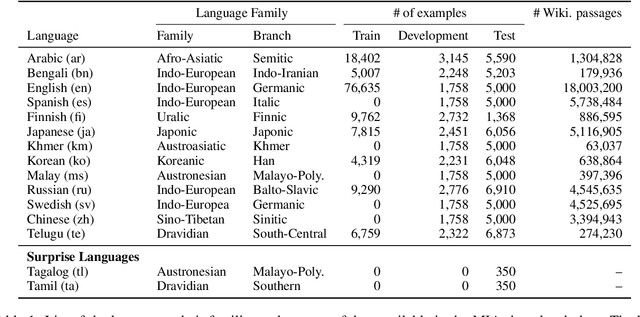
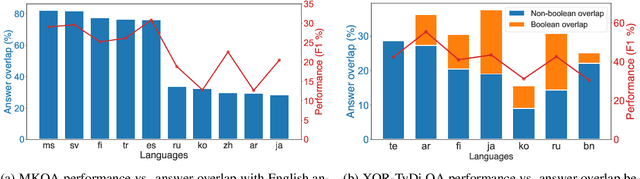
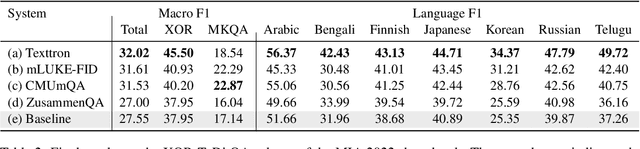

We present the results of the Workshop on Multilingual Information Access (MIA) 2022 Shared Task, evaluating cross-lingual open-retrieval question answering (QA) systems in 16 typologically diverse languages. In this task, we adapted two large-scale cross-lingual open-retrieval QA datasets in 14 typologically diverse languages, and newly annotated open-retrieval QA data in 2 underrepresented languages: Tagalog and Tamil. Four teams submitted their systems. The best system leveraging iteratively mined diverse negative examples and larger pretrained models achieves 32.2 F1, outperforming our baseline by 4.5 points. The second best system uses entity-aware contextualized representations for document retrieval, and achieves significant improvements in Tamil (20.8 F1), whereas most of the other systems yield nearly zero scores.
In-Context Learning for Few-Shot Dialogue State Tracking
Mar 16, 2022
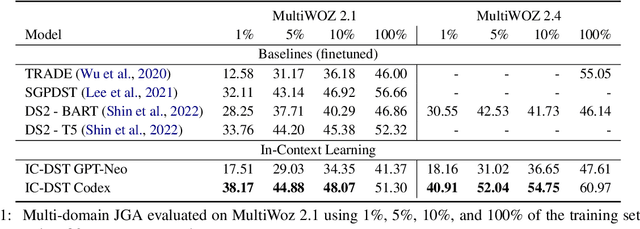


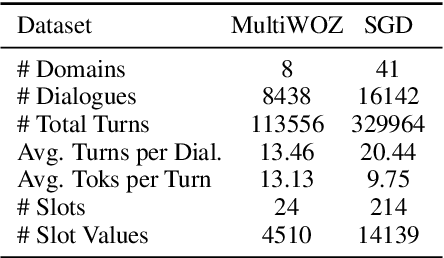
Collecting and annotating task-oriented dialogues is time-consuming and costly. Thus, few-shot learning for dialogue tasks presents an exciting opportunity. In this work, we propose an in-context (IC) learning framework for few-shot dialogue state tracking (DST), where a large pre-trained language model (LM) takes a test instance and a few annotated examples as input, and directly decodes the dialogue states without any parameter updates. This makes the LM more flexible and scalable compared to prior few-shot DST work when adapting to new domains and scenarios. We study ways to formulate dialogue context into prompts for LMs and propose an efficient approach to retrieve dialogues as exemplars given a test instance and a selection pool of few-shot examples. To better leverage the pre-trained LMs, we also reformulate DST into a text-to-SQL problem. Empirical results on MultiWOZ 2.1 and 2.4 show that our method IC-DST outperforms previous fine-tuned state-of-the-art models in few-shot settings.
DOCmT5: Document-Level Pretraining of Multilingual Language Models
Dec 16, 2021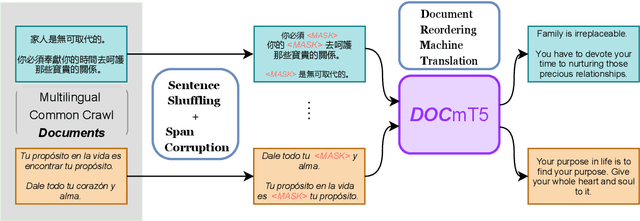
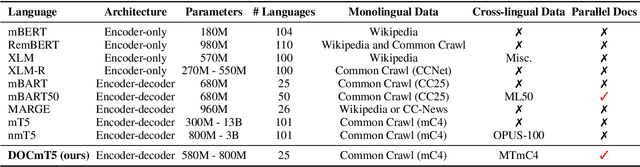
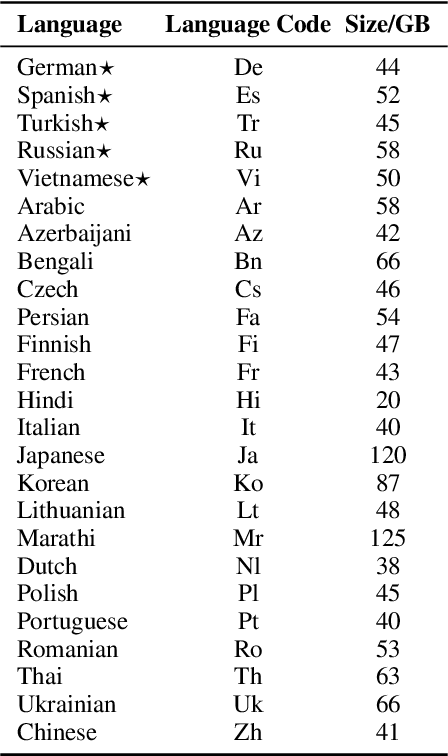
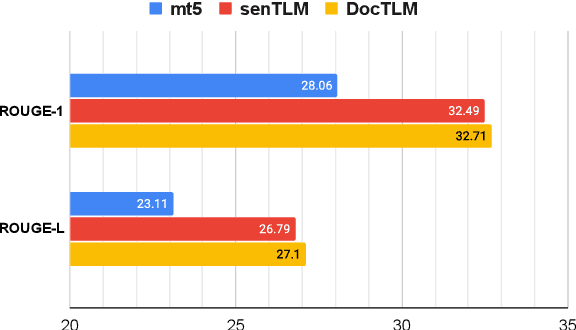
In this paper, we introduce DOCmT5, a multilingual sequence-to-sequence language model pre-trained with large scale parallel documents. While previous approaches have focused on leveraging sentence-level parallel data, we try to build a general-purpose pre-trained model that can understand and generate long documents. We propose a simple and effective pre-training objective - Document Reordering Machine Translation (DrMT), in which the input documents that are shuffled and masked need to be translated. DrMT brings consistent improvements over strong baselines on a variety of document-level generation tasks, including over 12 BLEU points for seen-language-pair document-level MT, over 7 BLEU points for unseen-language-pair document-level MT and over 3 ROUGE-1 points for seen-language-pair cross-lingual summarization. We achieve state-of-the-art (SOTA) on WMT20 De-En and IWSLT15 Zh-En document translation tasks. We also conduct extensive analysis on various factors for document pre-training, including (1) the effects of pre-training data quality and (2) The effects of combining mono-lingual and cross-lingual pre-training. We plan to make our model checkpoints publicly available.
Dialogue State Tracking with a Language Model using Schema-Driven Prompting
Sep 15, 2021


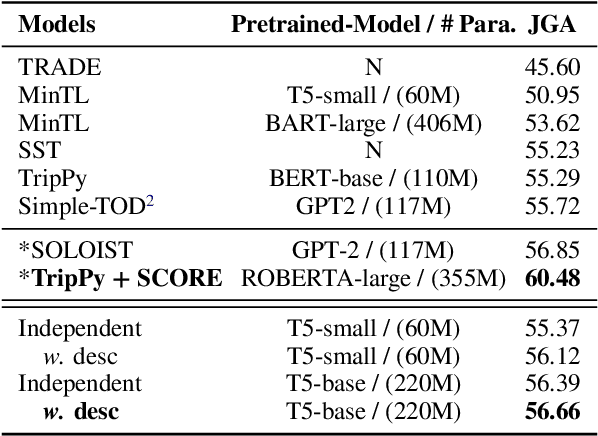
Task-oriented conversational systems often use dialogue state tracking to represent the user's intentions, which involves filling in values of pre-defined slots. Many approaches have been proposed, often using task-specific architectures with special-purpose classifiers. Recently, good results have been obtained using more general architectures based on pretrained language models. Here, we introduce a new variation of the language modeling approach that uses schema-driven prompting to provide task-aware history encoding that is used for both categorical and non-categorical slots. We further improve performance by augmenting the prompting with schema descriptions, a naturally occurring source of in-domain knowledge. Our purely generative system achieves state-of-the-art performance on MultiWOZ 2.2 and achieves competitive performance on two other benchmarks: MultiWOZ 2.1 and M2M. The data and code will be available at https://github.com/chiahsuan156/DST-as-Prompting.
KaggleDBQA: Realistic Evaluation of Text-to-SQL Parsers
Jun 22, 2021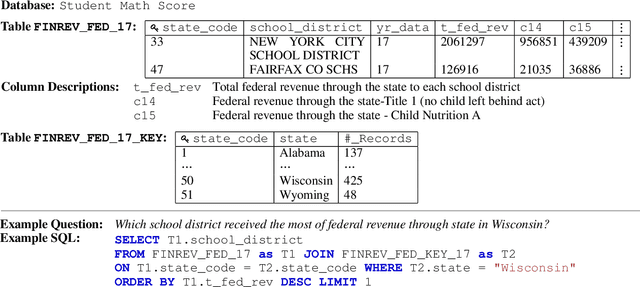
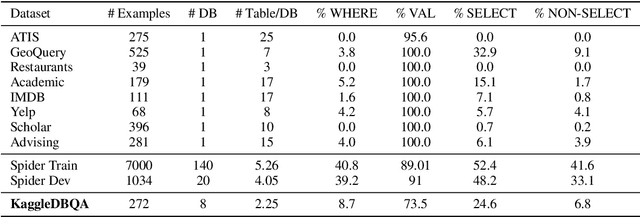
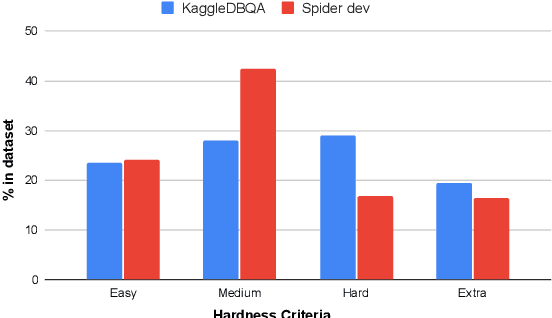

The goal of database question answering is to enable natural language querying of real-life relational databases in diverse application domains. Recently, large-scale datasets such as Spider and WikiSQL facilitated novel modeling techniques for text-to-SQL parsing, improving zero-shot generalization to unseen databases. In this work, we examine the challenges that still prevent these techniques from practical deployment. First, we present KaggleDBQA, a new cross-domain evaluation dataset of real Web databases, with domain-specific data types, original formatting, and unrestricted questions. Second, we re-examine the choice of evaluation tasks for text-to-SQL parsers as applied in real-life settings. Finally, we augment our in-domain evaluation task with database documentation, a naturally occurring source of implicit domain knowledge. We show that KaggleDBQA presents a challenge to state-of-the-art zero-shot parsers but a more realistic evaluation setting and creative use of associated database documentation boosts their accuracy by over 13.2%, doubling their performance.
Cross-Lingual Transfer Learning for Question Answering
Jul 13, 2019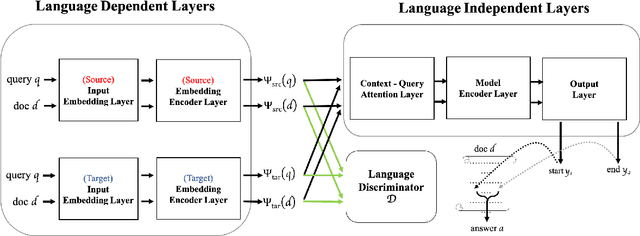

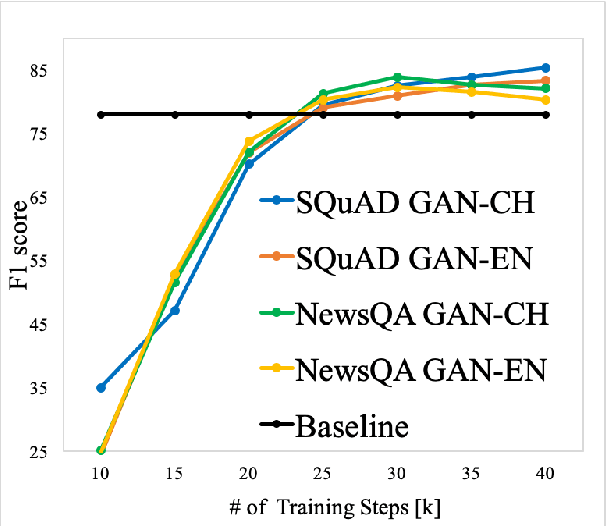

Deep learning based question answering (QA) on English documents has achieved success because there is a large amount of English training examples. However, for most languages, training examples for high-quality QA models are not available. In this paper, we explore the problem of cross-lingual transfer learning for QA, where a source language task with plentiful annotations is utilized to improve the performance of a QA model on a target language task with limited available annotations. We examine two different approaches. A machine translation (MT) based approach translates the source language into the target language, or vice versa. Although the MT-based approach brings improvement, it assumes the availability of a sentence-level translation system. A GAN-based approach incorporates a language discriminator to learn language-universal feature representations, and consequentially transfer knowledge from the source language. The GAN-based approach rivals the performance of the MT-based approach with fewer linguistic resources. Applying both approaches simultaneously yield the best results. We use two English benchmark datasets, SQuAD and NewsQA, as source language data, and show significant improvements over a number of established baselines on a Chinese QA task. We achieve the new state-of-the-art on the Chinese QA dataset.