 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Self-Sampled Correct and Partially-Correct Programs
May 28, 2022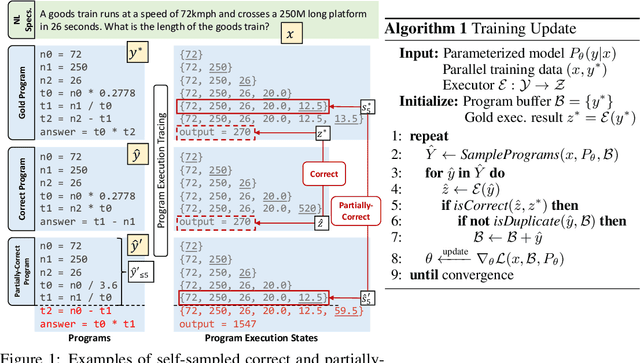

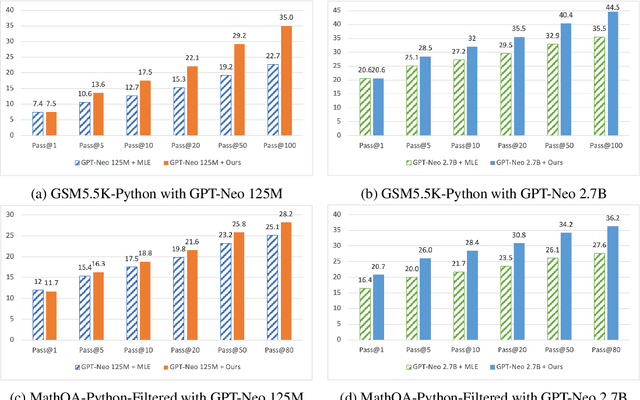
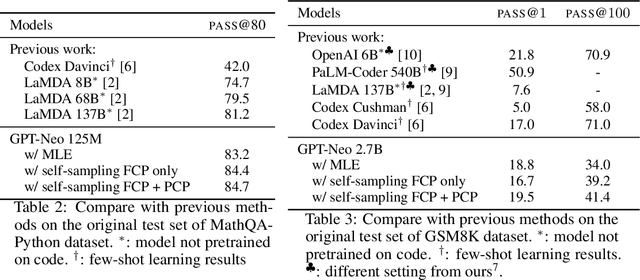
Program synthesis aims to generate executable programs that are consistent with the user specification. While there are often multiple programs that satisfy the same user specification, existing neural program synthesis models are often only learned from one reference program by maximizing its log-likelihood. This causes the model to be overly confident in its predictions as it sees the single solution repeatedly during training. This leads to poor generalization on unseen examples, even when multiple attempts are allowed. To mitigate this issue, we propose to let the model perform sampling during training and learn from both self-sampled fully-correct programs, which yield the gold execution results, as well as partially-correct programs, whose intermediate execution state matches another correct program. We show that our use of self-sampled correct and partially-correct programs can benefit learning and help guide the sampling process, leading to more efficient exploration of the program space. Additionally, we explore various training objectives to support learning from multiple programs per example and find they greatly affect the performance. Experiments on the MathQA and GSM8K datasets show that our proposed method improves the pass@k performance by 3.1% to 12.3% compared to learning from a single reference program with MLE.
PaLM: Scaling Language Modeling with Pathways
Apr 19, 2022



Large language models have been shown to achieve remarkable performance across a variety of natural language tasks using few-shot learning, which drastically reduces the number of task-specific training examples needed to adapt the model to a particular application. To further our understanding of the impact of scale on few-shot learning, we trained a 540-billion parameter, densely activated, Transformer language model, which we call Pathways Language Model PaLM. We trained PaLM on 6144 TPU v4 chips using Pathways, a new ML system which enables highly efficient training across multiple TPU Pods. We demonstrate continued benefits of scaling by achieving state-of-the-art few-shot learning results on hundreds of language understanding and generation benchmarks. On a number of these tasks, PaLM 540B achieves breakthrough performance, outperforming the finetuned state-of-the-art on a suite of multi-step reasoning tasks, and outperforming average human performance on the recently released BIG-bench benchmark. A significant number of BIG-bench tasks showed discontinuous improvements from model scale, meaning that performance steeply increased as we scaled to our largest model. PaLM also has strong capabilities in multilingual tasks and source code generation, which we demonstrate on a wide array of benchmarks. We additionally provide a comprehensive analysis on bias and toxicity, and study the extent of training data memorization with respect to model scale. Finally, we discuss the ethical considerations related to large language models and discuss potential mitigation strategies.
Synchromesh: Reliable code generation from pre-trained language models
Jan 26, 2022

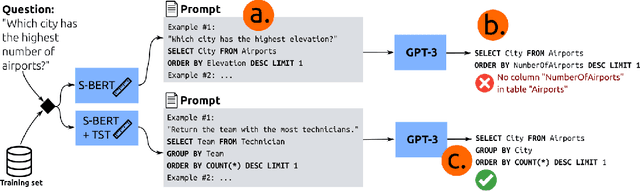
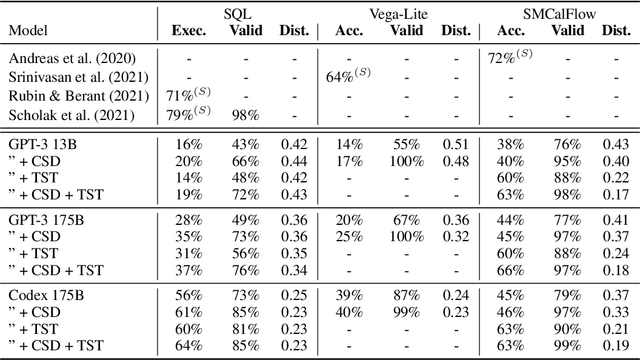
Large pre-trained language models have been used to generate code,providing a flexible interface for synthesizing programs from natural language specifications. However, they often violate syntactic and semantic rules of their output language, limiting their practical usability. In this paper, we propose Synchromesh: a framework for substantially improving the reliability of pre-trained models for code generation. Synchromesh comprises two components. First, it retrieves few-shot examples from a training bank using Target Similarity Tuning (TST), a novel method for semantic example selection. TST learns to recognize utterances that describe similar target programs despite differences in surface natural language features. Then, Synchromesh feeds the examples to a pre-trained language model and samples programs using Constrained Semantic Decoding (CSD): a general framework for constraining the output to a set of valid programs in the target language. CSD leverages constraints on partial outputs to sample complete correct programs, and needs neither re-training nor fine-tuning of the language model. We evaluate our methods by synthesizing code from natural language descriptions using GPT-3 and Codex in three real-world languages: SQL queries, Vega-Lite visualizations and SMCalFlow programs. These domains showcase rich constraints that CSD is able to enforce, including syntax, scope, typing rules, and contextual logic. We observe substantial complementary gains from CSD and TST in prediction accuracy and in effectively preventing run-time errors.
KaggleDBQA: Realistic Evaluation of Text-to-SQL Parsers
Jun 22, 2021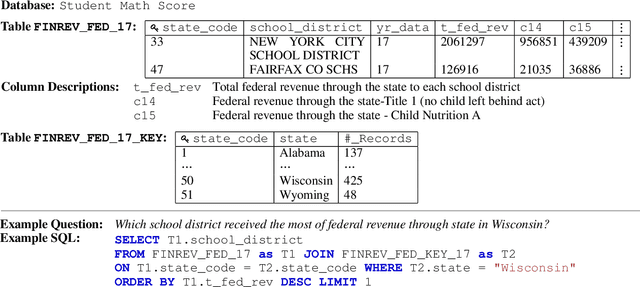
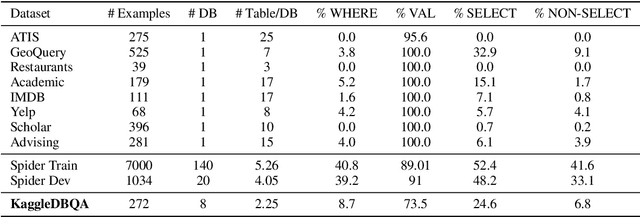
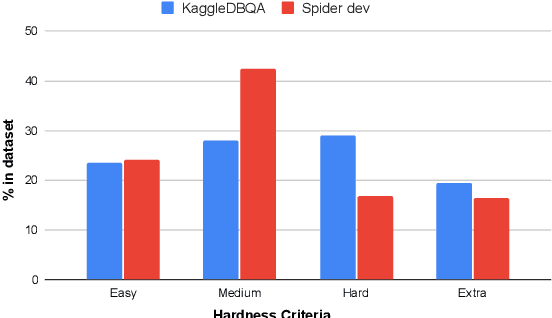

The goal of database question answering is to enable natural language querying of real-life relational databases in diverse application domains. Recently, large-scale datasets such as Spider and WikiSQL facilitated novel modeling techniques for text-to-SQL parsing, improving zero-shot generalization to unseen databases. In this work, we examine the challenges that still prevent these techniques from practical deployment. First, we present KaggleDBQA, a new cross-domain evaluation dataset of real Web databases, with domain-specific data types, original formatting, and unrestricted questions. Second, we re-examine the choice of evaluation tasks for text-to-SQL parsers as applied in real-life settings. Finally, we augment our in-domain evaluation task with database documentation, a naturally occurring source of implicit domain knowledge. We show that KaggleDBQA presents a challenge to state-of-the-art zero-shot parsers but a more realistic evaluation setting and creative use of associated database documentation boosts their accuracy by over 13.2%, doubling their performance.
Programming Puzzles
Jun 10, 2021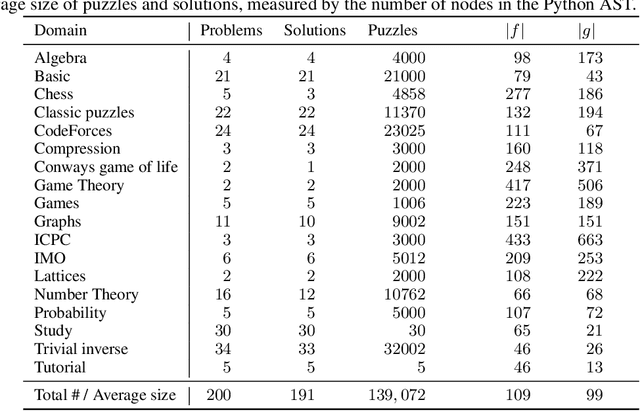
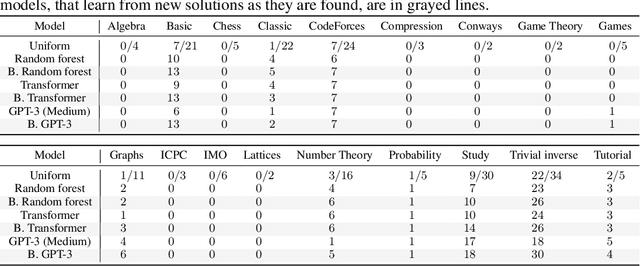
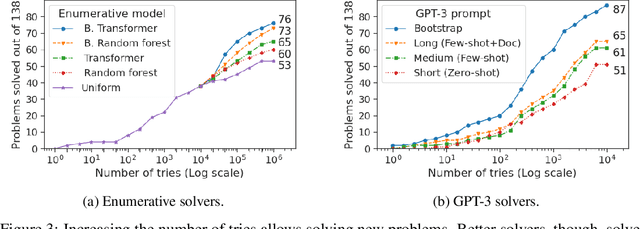
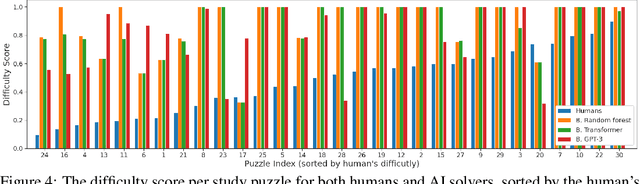
We introduce a new type of programming challenge called programming puzzles, as an objective and comprehensive evaluation of program synthesis, and release an open-source dataset of Python Programming Puzzles (P3). Each puzzle is defined by a short Python program $f$, and the goal is to find an input $x$ which makes $f$ output "True". The puzzles are objective in that each one is specified entirely by the source code of its verifier $f$, so evaluating $f(x)$ is all that is needed to test a candidate solution $x$. They do not require an answer key or input/output examples, nor do they depend on natural language understanding. The dataset is comprehensive in that it spans problems of a range of difficulties and domains, ranging from trivial string manipulation problems that are immediately obvious to human programmers (but not necessarily to AI), to classic programming puzzles (e.g., Towers of Hanoi), to interview/competitive-programming problems (e.g., dynamic programming), to longstanding open problems in algorithms and mathematics (e.g., factoring). The objective nature of P3 readily supports self-supervised bootstrapping. We develop baseline enumerative program synthesis and GPT-3 solvers that are capable of solving easy puzzles -- even without access to any reference solutions -- by learning from their own past solutions. Based on a small user study, we find puzzle difficulty to correlate between human programmers and the baseline AI solvers.
Structure-Grounded Pretraining for Text-to-SQL
Oct 24, 2020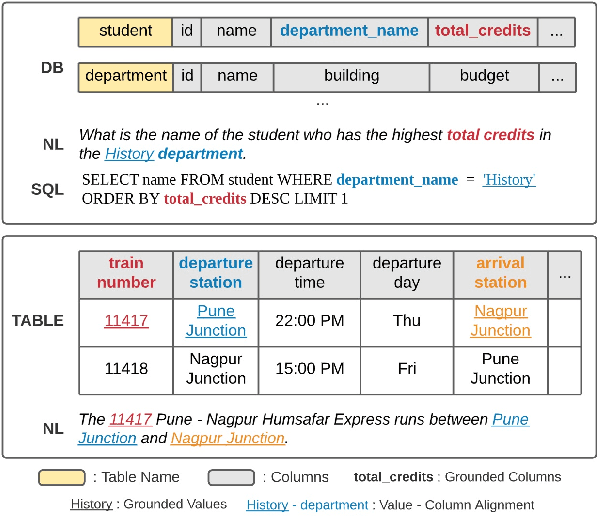
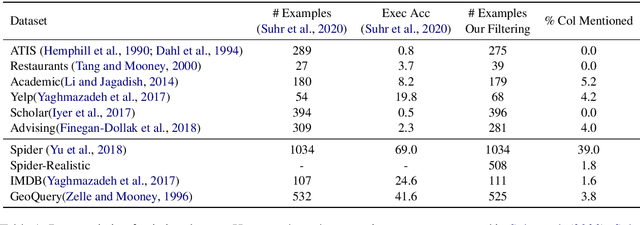
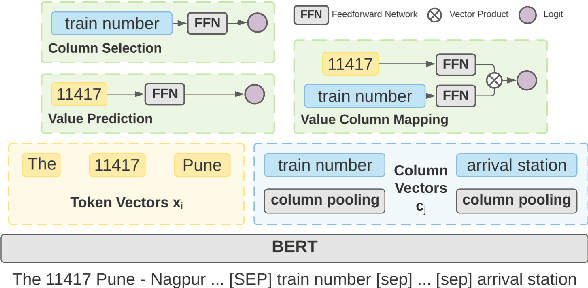

Learning to capture text-table alignment is essential for table related tasks like text-to-SQL. The model needs to correctly recognize natural language references to columns and values and to ground them in the given database schema. In this paper, we present a novel weakly supervised Structure-Grounded pretraining framework (StruG) for text-to-SQL that can effectively learn to capture text-table alignment based on a parallel text-table corpus. We identify a set of novel prediction tasks: column grounding, value grounding and column-value mapping, and train them using weak supervision without requiring complex SQL annotation. Additionally, to evaluate the model under a more realistic setting, we create a new evaluation set Spider-Realistic based on Spider with explicit mentions of column names removed, and adopt two existing single-database text-to-SQL datasets. StruG significantly outperforms BERT-LARGE on Spider and the realistic evaluation sets, while bringing consistent improvement on the large-scale WikiSQL benchmark.
Neuro-Symbolic Visual Reasoning: Disentangling "Visual" from "Reasoning"
Jun 30, 2020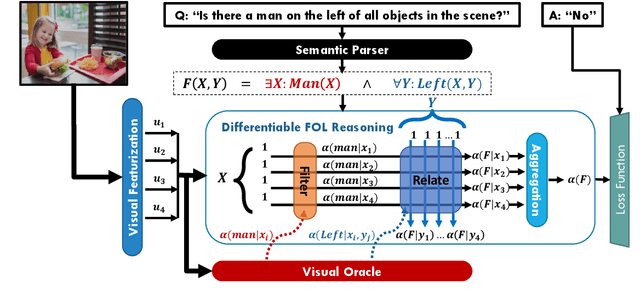
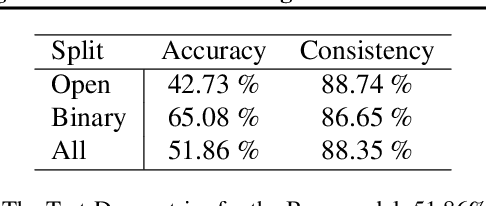
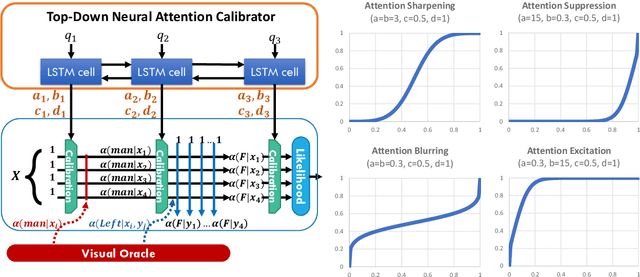
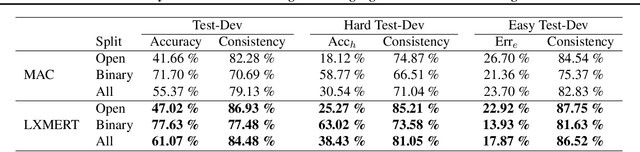
Visual reasoning tasks such as visual question answering (VQA) require an interplay of visual perception with reasoning about the question semantics grounded in perception. Various benchmarks for reasoning across language and vision like VQA, VCR and more recently GQA for compositional question answering facilitate scientific progress from perception models to visual reasoning. However, recent advances are still primarily driven by perception improvements (e.g. scene graph generation) rather than reasoning. Neuro-symbolic models such as Neural Module Networks bring the benefits of compositional reasoning to VQA, but they are still entangled with visual representation learning, and thus neural reasoning is hard to improve and assess on its own. To address this, we propose (1) a framework to isolate and evaluate the reasoning aspect of VQA separately from its perception, and (2) a novel top-down calibration technique that allows the model to answer reasoning questions even with imperfect perception. To this end, we introduce a differentiable first-order logic formalism for VQA that explicitly decouples question answering from visual perception. On the challenging GQA dataset, this framework is used to perform in-depth, disentangled comparisons between well-known VQA models leading to informative insights regarding the participating models as well as the task.
RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers
Nov 10, 2019
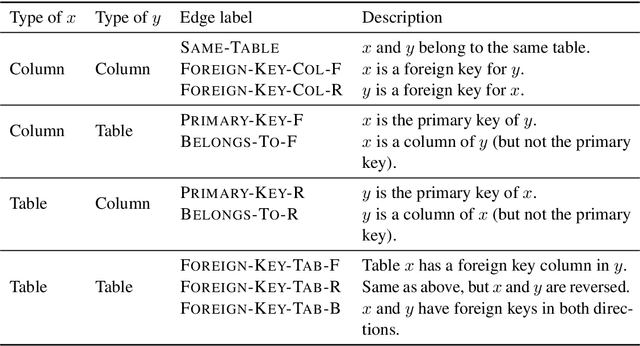
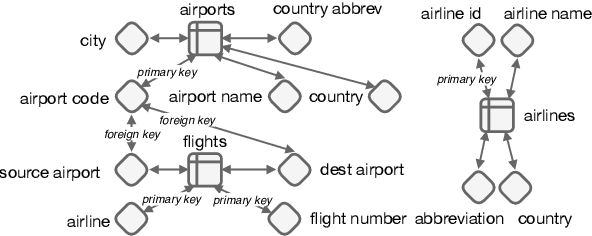
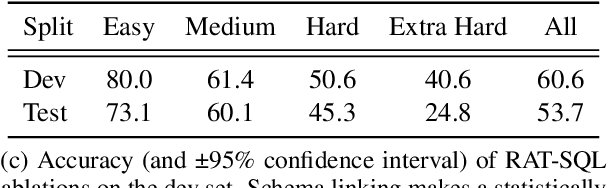
When translating natural language questions into SQL queries to answer questions from a database, contemporary semantic parsing models struggle to generalize to unseen database schemas. The generalization challenge lies in (a) encoding the database relations in an accessible way for the semantic parser, and (b) modeling alignment between database columns and their mentions in a given query. We present a unified framework, based on the relation-aware self-attention mechanism, to address schema encoding, schema linking, and feature representation within a text-to-SQL encoder. On the challenging Spider dataset this framework boosts the exact match accuracy to 53.7%, compared to 47.4% for the state-of-the-art model unaugmented with BERT embeddings. In addition, we observe qualitative improvements in the model's understanding of schema linking and alignment.
Program Synthesis and Semantic Parsing with Learned Code Idioms
Jul 23, 2019
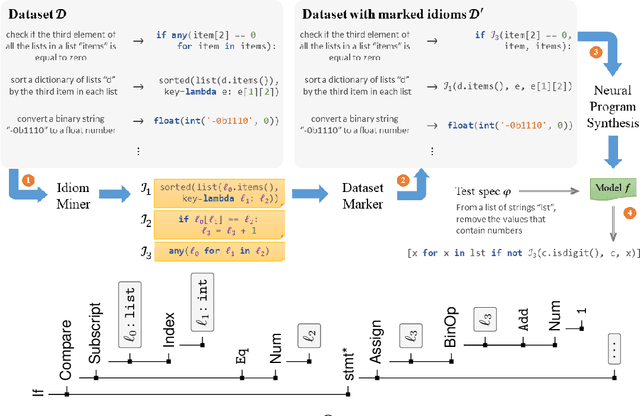
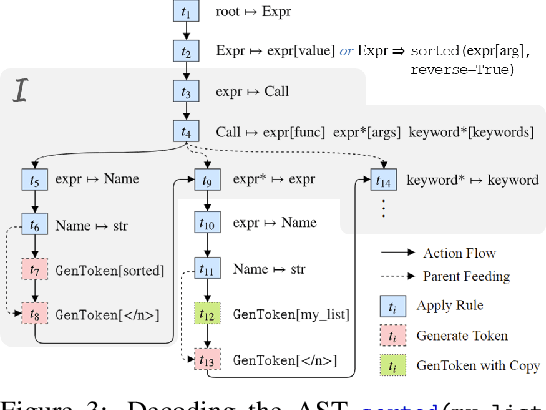
Program synthesis of general-purpose source code from natural language specifications is challenging due to the need to reason about high-level patterns in the target program and low-level implementation details at the same time. In this work, we present PATOIS, a system that allows a neural program synthesizer to explicitly interleave high-level and low-level reasoning at every generation step. It accomplishes this by automatically mining common code idioms from a given corpus, incorporating them into the underlying language for neural synthesis, and training a tree-based neural synthesizer to use these idioms during code generation. We evaluate PATOIS on two complex semantic parsing datasets and show that using learned code idioms improves the synthesizer's accuracy.
IncSQL: Training Incremental Text-to-SQL Parsers with Non-Deterministic Oracles
Oct 01, 2018

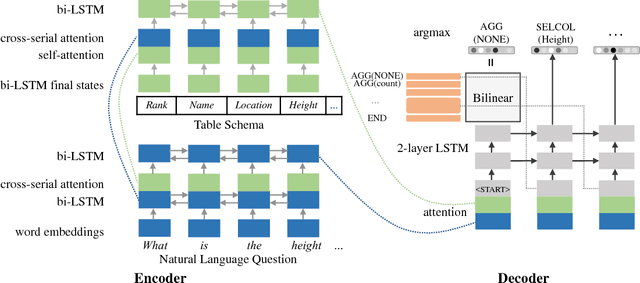
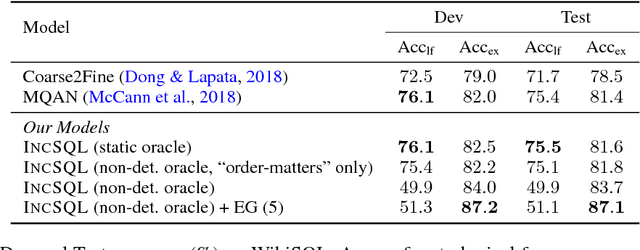
We present a sequence-to-action parsing approach for the natural language to SQL task that incrementally fills the slots of a SQL query with feasible actions from a pre-defined inventory. To account for the fact that typically there are multiple correct SQL queries with the same or very similar semantics, we draw inspiration from syntactic parsing techniques and propose to train our sequence-to-action models with non-deterministic oracles. We evaluate our models on the WikiSQL dataset and achieve an execution accuracy of 83.7% on the test set, a 2.1% absolute improvement over the models trained with traditional static oracles assuming a single correct target SQL query. When further combined with the execution-guided decoding strategy, our model sets a new state-of-the-art performance at an execution accuracy of 87.1%.