 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Self-Sampled Correct and Partially-Correct Programs
Paper and Code
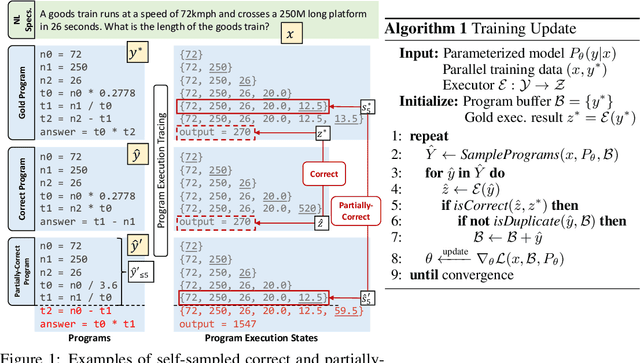

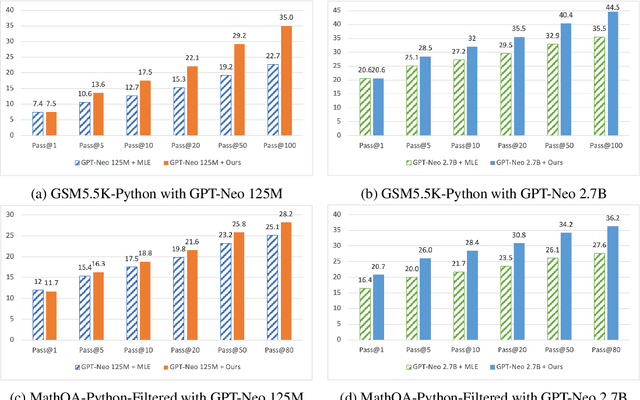
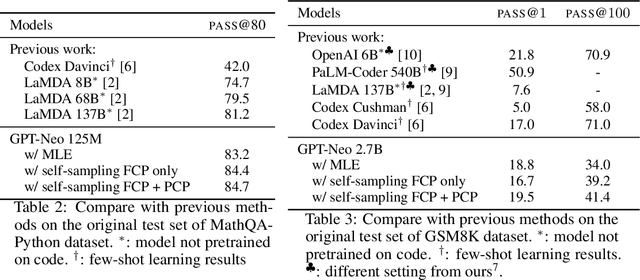
Program synthesis aims to generate executable programs that are consistent with the user specification. While there are often multiple programs that satisfy the same user specification, existing neural program synthesis models are often only learned from one reference program by maximizing its log-likelihood. This causes the model to be overly confident in its predictions as it sees the single solution repeatedly during training. This leads to poor generalization on unseen examples, even when multiple attempts are allowed. To mitigate this issue, we propose to let the model perform sampling during training and learn from both self-sampled fully-correct programs, which yield the gold execution results, as well as partially-correct programs, whose intermediate execution state matches another correct program. We show that our use of self-sampled correct and partially-correct programs can benefit learning and help guide the sampling process, leading to more efficient exploration of the program space. Additionally, we explore various training objectives to support learning from multiple programs per example and find they greatly affect the performance. Experiments on the MathQA and GSM8K datasets show that our proposed method improves the pass@k performance by 3.1% to 12.3% compared to learning from a single reference program with MLE.