 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Interrupt in Language-based Multi-agent Communication
Apr 07, 2026Multi-agent systems using large language models (LLMs) have demonstrated impressive capabilities across various domains. However, current agent communication suffers from verbose output that overload context and increase computational costs. Although existing approaches focus on compressing the message from the speaker side, they struggle to adapt to different listeners and identify relevant information. An effective way in human communication is to allow the listener to interrupt and express their opinion or ask for clarification. Motivated by this, we propose an interruptible communication framework that allows the agent who is listening to interrupt the current speaker. Through prompting experiments, we find that current LLMs are often overconfident and interrupt before receiving enough information. Therefore, we propose a learning method that predicts the appropriate interruption points based on the estimated future reward and cost. We evaluate our framework across various multi-agent scenarios, including 2-agent text pictionary games, 3-agent meeting scheduling, and 3-agent debate. The results of the experiment show that our HANDRAISER can reduce the communication cost by 32.2% compared to the baseline with comparable or superior task performance. This learned interruption behavior can also be generalized to different agents and tasks.
PrefPalette: Personalized Preference Modeling with Latent Attributes
Jul 17, 2025



Personalizing AI systems requires understanding not just what users prefer, but the reasons that underlie those preferences - yet current preference models typically treat human judgment as a black box. We introduce PrefPalette, a framework that decomposes preferences into attribute dimensions and tailors its preference prediction to distinct social community values in a human-interpretable manner. PrefPalette operationalizes a cognitive science principle known as multi-attribute decision making in two ways: (1) a scalable counterfactual attribute synthesis step that involves generating synthetic training data to isolate for individual attribute effects (e.g., formality, humor, cultural values), and (2) attention-based preference modeling that learns how different social communities dynamically weight these attributes. This approach moves beyond aggregate preference modeling to capture the diverse evaluation frameworks that drive human judgment. When evaluated on 45 social communities from the online platform Reddit, PrefPalette outperforms GPT-4o by 46.6% in average prediction accuracy. Beyond raw predictive improvements, PrefPalette also shed light on intuitive, community-specific profiles: scholarly communities prioritize verbosity and stimulation, conflict-oriented communities value sarcasm and directness, and support-based communities emphasize empathy. By modeling the attribute-mediated structure of human judgment, PrefPalette delivers both superior preference modeling and transparent, interpretable insights, and serves as a first step toward more trustworthy, value-aware personalized applications.
Spider2-V: How Far Are Multimodal Agents From Automating Data Science and Engineering Workflows?
Jul 15, 2024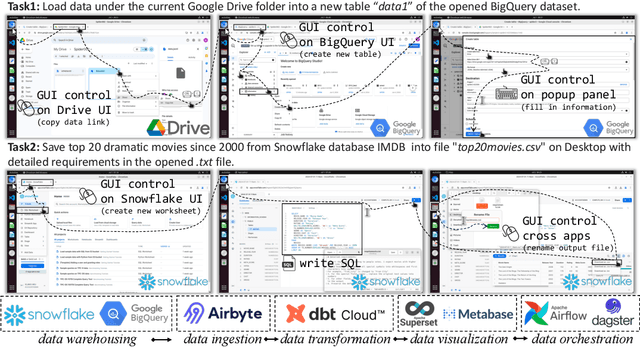
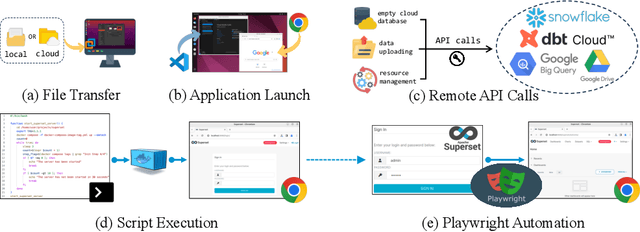
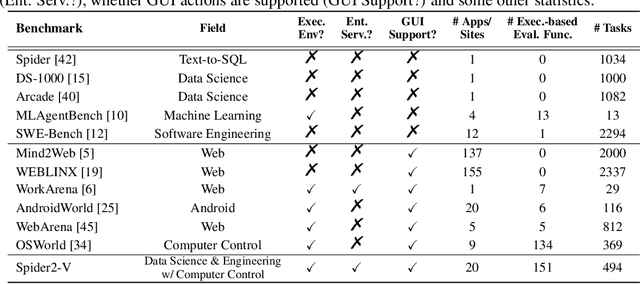
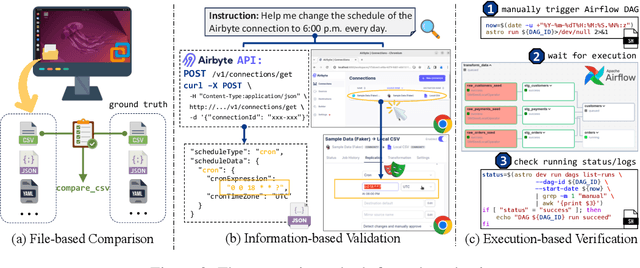
Data science and engineering workflows often span multiple stages, from warehousing to orchestration, using tools like BigQuery, dbt, and Airbyte. As vision language models (VLMs) advance in multimodal understanding and code generation, VLM-based agents could potentially automate these workflows by generating SQL queries, Python code, and GUI operations. This automation can improve the productivity of experts while democratizing access to large-scale data analysis. In this paper, we introduce Spider2-V, the first multimodal agent benchmark focusing on professional data science and engineering workflows, featuring 494 real-world tasks in authentic computer environments and incorporating 20 enterprise-level professional applications. These tasks, derived from real-world use cases, evaluate the ability of a multimodal agent to perform data-related tasks by writing code and managing the GUI in enterprise data software systems. To balance realistic simulation with evaluation simplicity, we devote significant effort to developing automatic configurations for task setup and carefully crafting evaluation metrics for each task. Furthermore, we supplement multimodal agents with comprehensive documents of these enterprise data software systems. Our empirical evaluation reveals that existing state-of-the-art LLM/VLM-based agents do not reliably automate full data workflows (14.0% success). Even with step-by-step guidance, these agents still underperform in tasks that require fine-grained, knowledge-intensive GUI actions (16.2%) and involve remote cloud-hosted workspaces (10.6%). We hope that Spider2-V paves the way for autonomous multimodal agents to transform the automation of data science and engineering workflow. Our code and data are available at https://spider2-v.github.io.
NExT: Teaching Large Language Models to Reason about Code Execution
Apr 23, 2024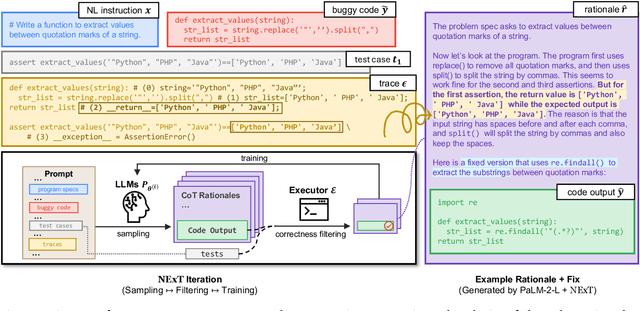



A fundamental skill among human developers is the ability to understand and reason about program execution. As an example, a programmer can mentally simulate code execution in natural language to debug and repair code (aka. rubber duck debugging). However, large language models (LLMs) of code are typically trained on the surface textual form of programs, thus may lack a semantic understanding of how programs execute at run-time. To address this issue, we propose NExT, a method to teach LLMs to inspect the execution traces of programs (variable states of executed lines) and reason about their run-time behavior through chain-of-thought (CoT) rationales. Specifically, NExT uses self-training to bootstrap a synthetic training set of execution-aware rationales that lead to correct task solutions (e.g., fixed programs) without laborious manual annotation. Experiments on program repair tasks based on MBPP and HumanEval demonstrate that NExT improves the fix rate of a PaLM 2 model, by 26.1% and 14.3% absolute, respectively, with significantly improved rationale quality as verified by automated metrics and human raters. Our model can also generalize to scenarios where program traces are absent at test-time.
Quantifying Contamination in Evaluating Code Generation Capabilities of Language Models
Mar 06, 2024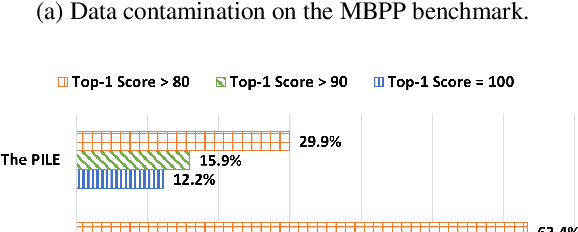
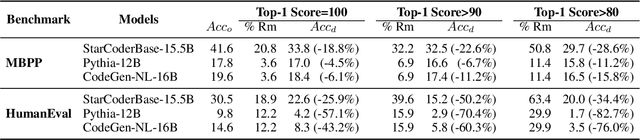


While large language models have achieved remarkable performance on various code generation benchmarks, there have been growing concerns regarding potential contamination of these benchmarks as they may be leaked into pretraining and finetuning data. While recent work has investigated contamination in natural language generation and understanding tasks, there has been less extensive research into how data contamination impacts the evaluation of code generation, which is critical for understanding the robustness and reliability of LLMs in programming contexts. In this work, we perform a comprehensive study of data contamination of popular code generation benchmarks, and precisely quantify their overlap with pretraining corpus through both surface-level and semantic-level matching. In our experiments, we show that there are substantial overlap between popular code generation benchmarks and open training corpus, and models perform significantly better on the subset of the benchmarks where similar solutions are seen during training. We also conduct extensive analysis on the factors that affects model memorization and generalization, such as model size, problem difficulty, and question length. We release all resulting files from our matching pipeline for future research.
L2CEval: Evaluating Language-to-Code Generation Capabilities of Large Language Models
Oct 02, 2023Recently, large language models (LLMs), especially those that are pretrained on code, have demonstrated strong capabilities in generating programs from natural language inputs in a few-shot or even zero-shot manner. Despite promising results, there is a notable lack of a comprehensive evaluation of these models language-to-code generation capabilities. Existing studies often focus on specific tasks, model architectures, or learning paradigms, leading to a fragmented understanding of the overall landscape. In this work, we present L2CEval, a systematic evaluation of the language-to-code generation capabilities of LLMs on 7 tasks across the domain spectrum of semantic parsing, math reasoning and Python programming, analyzing the factors that potentially affect their performance, such as model size, pretraining data, instruction tuning, and different prompting methods. In addition to assessing model performance, we measure confidence calibration for the models and conduct human evaluations of the output programs. This enables us to identify and analyze the typical failure modes across various tasks and models. L2CEval offers a comprehensive understanding of the capabilities and limitations of LLMs in language-to-code generation. We also release the evaluation framework and all model outputs, hoping to lay the groundwork for further future research in this domain.
LEVER: Learning to Verify Language-to-Code Generation with Execution
Feb 16, 2023The advent of pre-trained code language models (CodeLMs) has lead to significant progress in language-to-code generation. State-of-the-art approaches in this area combine CodeLM decoding with sample pruning and reranking using test cases or heuristics based on the execution results. However, it is challenging to obtain test cases for many real-world language-to-code applications, and heuristics cannot well capture the semantic features of the execution results, such as data type and value range, which often indicates the correctness of the program. In this work, we propose LEVER, a simple approach to improve language-to-code generation by learning to verify the generated programs with their execution results. Specifically, we train verifiers to determine whether a program sampled from the CodeLM is correct or not based on the natural language input, the program itself and its execution results. The sampled programs are reranked by combining the verification score with the CodeLM generation probability, and marginalizing over programs with the same execution results. On four datasets across the domains of table QA, math QA and basic Python programming, LEVER consistently improves over the base CodeLMs (4.6% to 10.9% with code-davinci-002) and achieves new state-of-the-art results on all of them.
Explicit Knowledge Transfer for Weakly-Supervised Code Generation
Nov 30, 2022Large language models (LLMs) can acquire strong code-generation capabilities through few-shot learning. In contrast, supervised fine-tuning is still needed for smaller models to achieve good performance. Such fine-tuning demands a large number of task-specific NL-code pairs, which are expensive to obtain. In this paper, we attempt to transfer the code generation ability of an LLM to a smaller model with the aid of weakly-supervised data. More specifically, we propose explicit knowledge transfer (EKT), which uses the few-shot capabilities of a teacher LLM to create NL-code pairs that we then filter for correctness and fine-tune the student on. We evaluate EKT on the task of generating code solutions to math word problems from the GSM8k dataset. We find that EKT not only yields better performance than training with expert iteration, but also outperforms knowledge distillation, another form of knowledge transfer. A GPT-Neo 1.3B model trained using EKT with a GPT-J teacher achieves a 12.4% pass@100 on GSM8k, while the same student and teacher trained with knowledge distillation yield only a 3.7% pass@100. We also show that it is possible for a student model to outperform the teacher using EKT.
FOLIO: Natural Language Reasoning with First-Order Logic
Sep 02, 2022
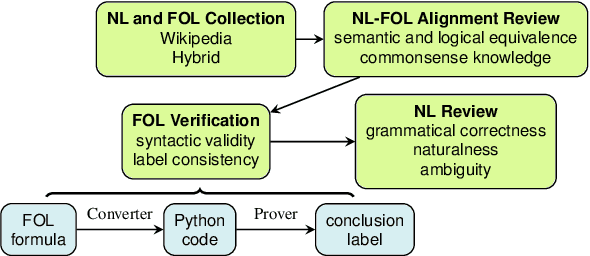
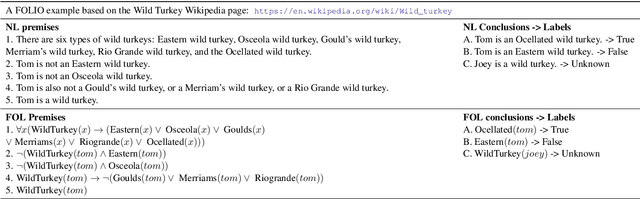
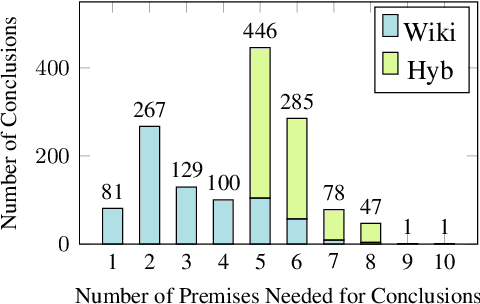
We present FOLIO, a human-annotated, open-domain, and logically complex and diverse dataset for reasoning in natural language (NL), equipped with first order logic (FOL) annotations. FOLIO consists of 1,435 examples (unique conclusions), each paired with one of 487 sets of premises which serve as rules to be used to deductively reason for the validity of each conclusion. The logical correctness of premises and conclusions is ensured by their parallel FOL annotations, which are automatically verified by our FOL inference engine. In addition to the main NL reasoning task, NL-FOL pairs in FOLIO automatically constitute a new NL-FOL translation dataset using FOL as the logical form. Our experiments on FOLIO systematically evaluate the FOL reasoning ability of supervised fine-tuning on medium-sized language models (BERT, RoBERTa) and few-shot prompting on large language models (GPT-NeoX, OPT, GPT-3, Codex). For NL-FOL translation, we experiment with GPT-3 and Codex. Our results show that one of the most capable Large Language Model (LLM) publicly available, GPT-3 davinci, achieves only slightly better than random results with few-shot prompting on a subset of FOLIO, and the model is especially bad at predicting the correct truth values for False and Unknown conclusions. Our dataset and code are available at https://github.com/Yale-LILY/FOLIO.
Learning from Self-Sampled Correct and Partially-Correct Programs
May 28, 2022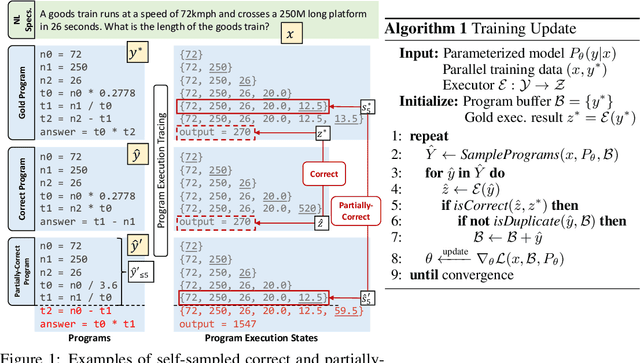

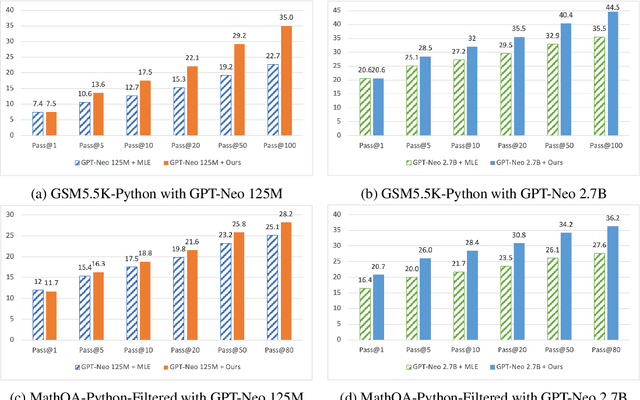
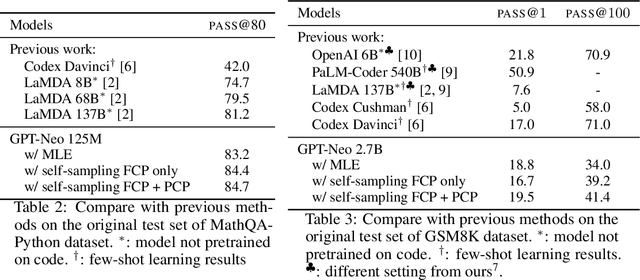
Program synthesis aims to generate executable programs that are consistent with the user specification. While there are often multiple programs that satisfy the same user specification, existing neural program synthesis models are often only learned from one reference program by maximizing its log-likelihood. This causes the model to be overly confident in its predictions as it sees the single solution repeatedly during training. This leads to poor generalization on unseen examples, even when multiple attempts are allowed. To mitigate this issue, we propose to let the model perform sampling during training and learn from both self-sampled fully-correct programs, which yield the gold execution results, as well as partially-correct programs, whose intermediate execution state matches another correct program. We show that our use of self-sampled correct and partially-correct programs can benefit learning and help guide the sampling process, leading to more efficient exploration of the program space. Additionally, we explore various training objectives to support learning from multiple programs per example and find they greatly affect the performance. Experiments on the MathQA and GSM8K datasets show that our proposed method improves the pass@k performance by 3.1% to 12.3% compared to learning from a single reference program with MLE.