 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Locality in Abstractive Text Summarization
Paper and Code
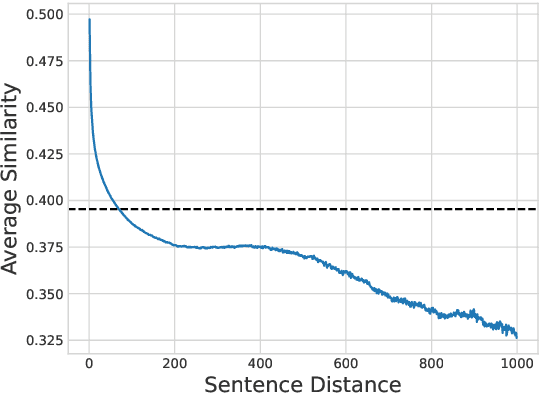
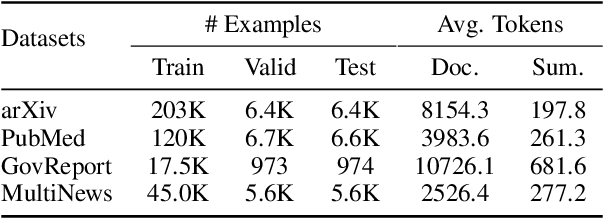
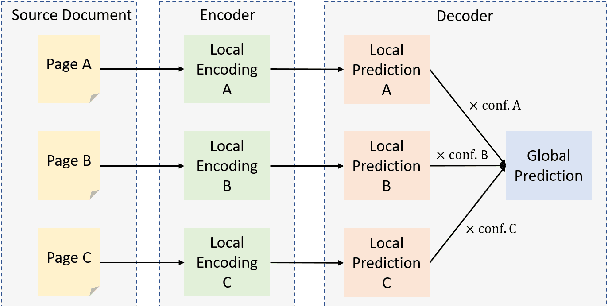
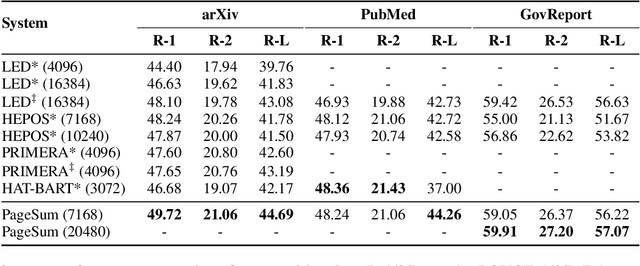
Despite the successes of neural attention models for natural language generation tasks, the quadratic memory complexity of the self-attention module with respect to the input length hinders their applications in long text summarization. Instead of designing more efficient attention modules, we approach this problem by investigating if models with a restricted context can have competitive performance compared with the memory-efficient attention models that maintain a global context by treating the input as an entire sequence. Our model is applied to individual pages, which contain parts of inputs grouped by the principle of locality, during both encoding and decoding stages. We empirically investigated three kinds of localities in text summarization at different levels, ranging from sentences to documents. Our experimental results show that our model can have better performance compared with strong baseline models with efficient attention modules, and our analysis provides further insights of our locality-aware modeling strategy.