 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat are the Desired Characteristics of Calibration Sets? Identifying Correlates on Long Form Scientific Summarization
May 12, 2023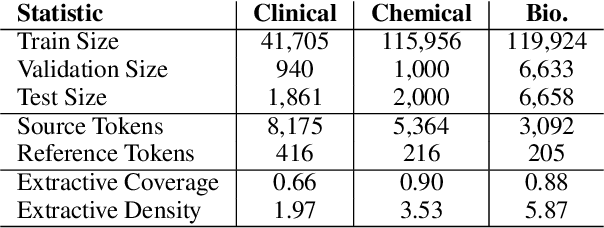
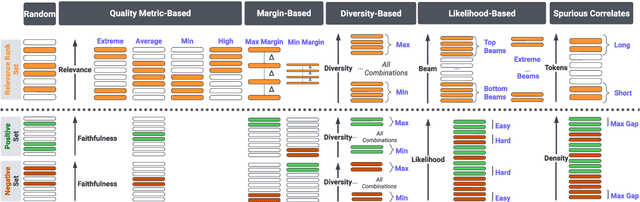
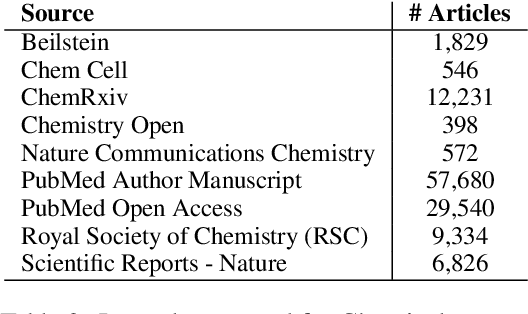
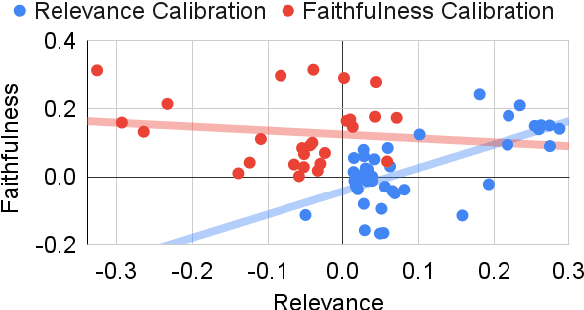
Summarization models often generate text that is poorly calibrated to quality metrics because they are trained to maximize the likelihood of a single reference (MLE). To address this, recent work has added a calibration step, which exposes a model to its own ranked outputs to improve relevance or, in a separate line of work, contrasts positive and negative sets to improve faithfulness. While effective, much of this work has focused on how to generate and optimize these sets. Less is known about why one setup is more effective than another. In this work, we uncover the underlying characteristics of effective sets. For each training instance, we form a large, diverse pool of candidates and systematically vary the subsets used for calibration fine-tuning. Each selection strategy targets distinct aspects of the sets, such as lexical diversity or the size of the gap between positive and negatives. On three diverse scientific long-form summarization datasets (spanning biomedical, clinical, and chemical domains), we find, among others, that faithfulness calibration is optimal when the negative sets are extractive and more likely to be generated, whereas for relevance calibration, the metric margin between candidates should be maximized and surprise--the disagreement between model and metric defined candidate rankings--minimized. Code to create, select, and optimize calibration sets is available at https://github.com/griff4692/calibrating-summaries
On Improving Summarization Factual Consistency from Natural Language Feedback
Dec 20, 2022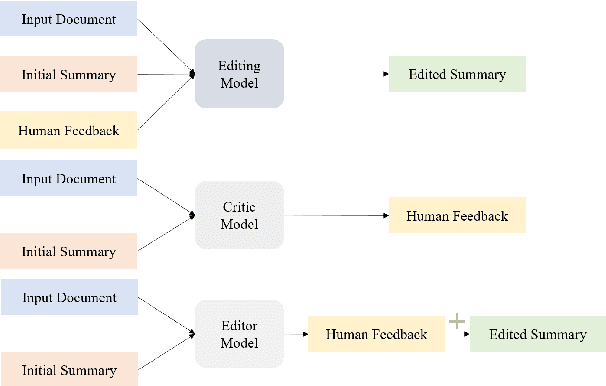

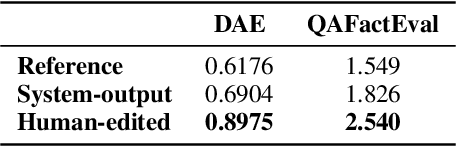
Despite the recent progress in language generation models, their outputs may not always meet user expectations. In this work, we study whether informational feedback in natural language can be leveraged to improve generation quality and user preference alignment. To this end, we consider factual consistency in summarization, the quality that the summary should only contain information supported by the input documents, for user preference alignment. We collect a high-quality dataset, DeFacto, containing human demonstrations and informational feedback in natural language consisting of corrective instructions, edited summaries, and explanations with respect to the factual consistency of the summary. Using our dataset, we study two natural language generation tasks: 1) editing a summary using the human feedback, and 2) generating human feedback from the original summary. Using the two tasks, we further evaluate if models can automatically correct factual inconsistencies in generated summaries. We show that the human-edited summaries we collected are more factually consistent, and pre-trained language models can leverage our dataset to improve the factual consistency of original system-generated summaries in our proposed generation tasks. We make the DeFacto dataset publicly available at https://github.com/microsoft/DeFacto.
Leveraging Locality in Abstractive Text Summarization
May 25, 2022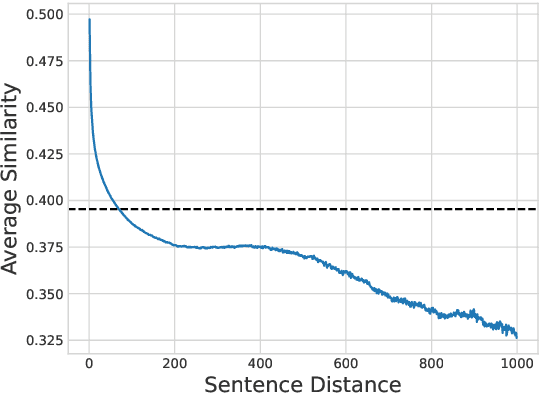
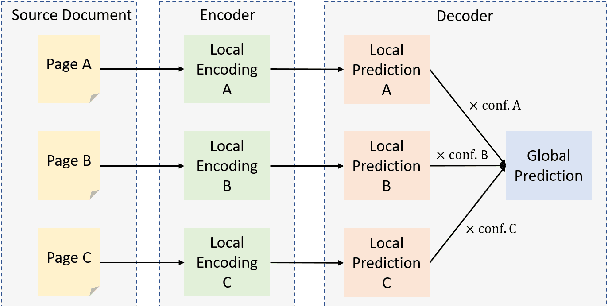
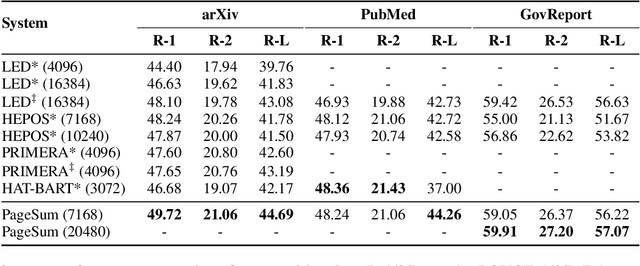
Despite the successes of neural attention models for natural language generation tasks, the quadratic memory complexity of the self-attention module with respect to the input length hinders their applications in long text summarization. Instead of designing more efficient attention modules, we approach this problem by investigating if models with a restricted context can have competitive performance compared with the memory-efficient attention models that maintain a global context by treating the input as an entire sequence. Our model is applied to individual pages, which contain parts of inputs grouped by the principle of locality, during both encoding and decoding stages. We empirically investigated three kinds of localities in text summarization at different levels, ranging from sentences to documents. Our experimental results show that our model can have better performance compared with strong baseline models with efficient attention modules, and our analysis provides further insights of our locality-aware modeling strategy.
Summ^N: A Multi-Stage Summarization Framework for Long Input Dialogues and Documents
Oct 16, 2021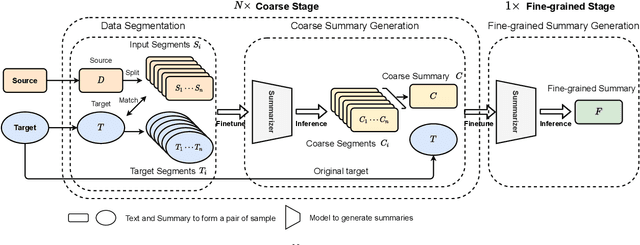
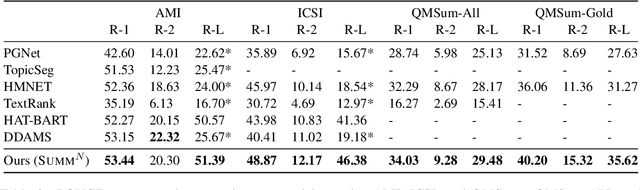
Text summarization is an essential task to help readers capture salient information from documents, news, interviews, and meetings. However, most state-of-the-art pretrained language models are unable to efficiently process long text commonly seen in the summarization problem domain. In this paper, we propose Summ^N, a simple, flexible, and effective multi-stage framework for input texts that are longer than the maximum context lengths of typical pretrained LMs. Summ^N first generates the coarse summary in multiple stages and then produces the final fine-grained summary based on them. The framework can process input text of arbitrary length by adjusting the number of stages while keeping the LM context size fixed. Moreover, it can deal with both documents and dialogues and can be used on top of any underlying backbone abstractive summarization model. Our experiments demonstrate that Summ^N significantly outperforms previous state-of-the-art methods by improving ROUGE scores on three long meeting summarization datasets AMI, ICSI, and QMSum, two long TV series datasets from SummScreen, and a newly proposed long document summarization dataset GovReport. Our data and code are available at https://github.com/chatc/Summ-N.
DYLE: Dynamic Latent Extraction for Abstractive Long-Input Summarization
Oct 15, 2021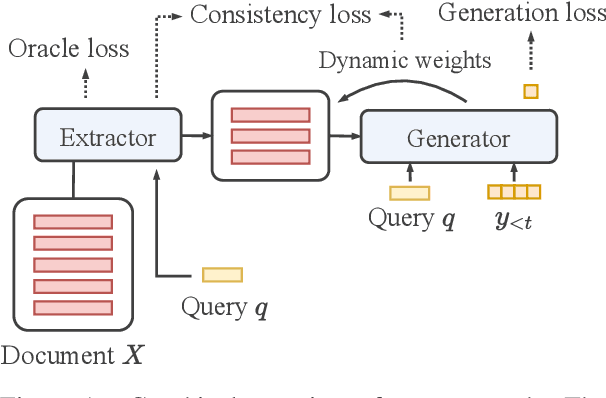
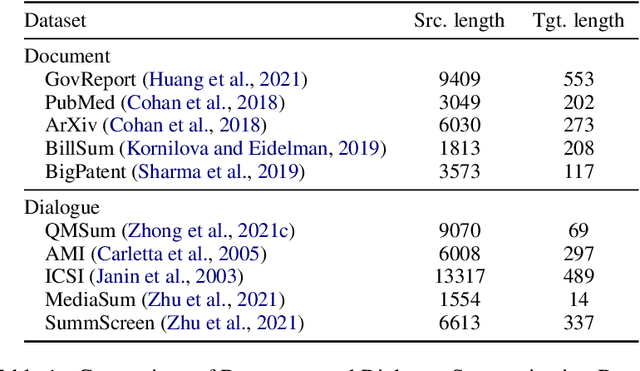
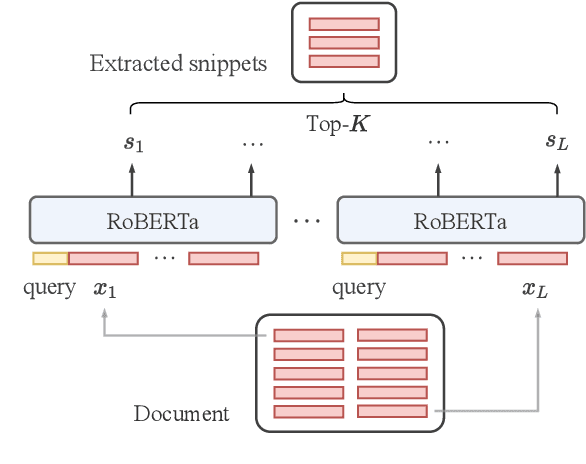
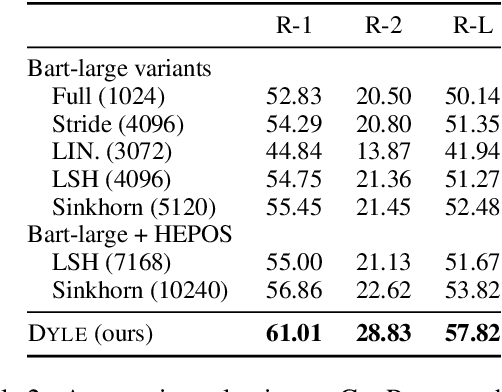
Transformer-based models have achieved state-of-the-art performance on short text summarization. However, they still struggle with long-input summarization. In this paper, we present a new approach for long-input summarization: Dynamic Latent Extraction for Abstractive Summarization. We jointly train an extractor with an abstractor and treat the extracted text snippets as the latent variable. We propose extractive oracles to provide the extractor with a strong learning signal. We introduce consistency loss, which encourages the extractor to approximate the averaged dynamic weights predicted by the generator. We conduct extensive tests on two long-input summarization datasets, GovReport (document) and QMSum (dialogue). Our model significantly outperforms the current state-of-the-art, including a 6.21 ROUGE-2 improvement on GovReport and a 2.13 ROUGE-1 improvement on QMSum. Further analysis shows that the dynamic weights make our generation process highly interpretable. Our code will be publicly available upon publication.
A Conditional Generative Matching Model for Multi-lingual Reply Suggestion
Sep 15, 2021

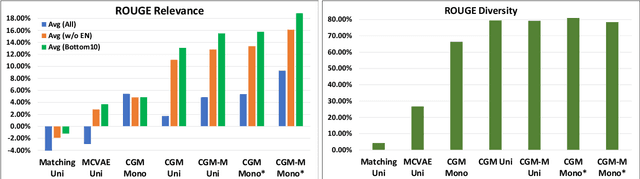
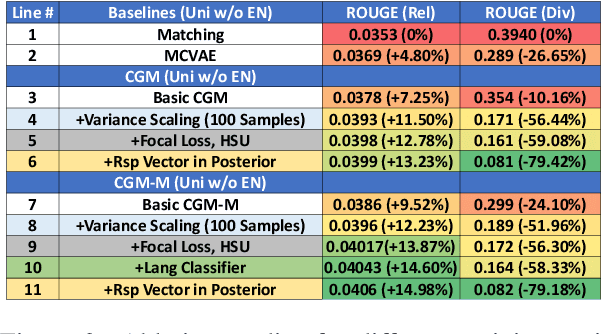
We study the problem of multilingual automated reply suggestions (RS) model serving many languages simultaneously. Multilingual models are often challenged by model capacity and severe data distribution skew across languages. While prior works largely focus on monolingual models, we propose Conditional Generative Matching models (CGM), optimized within a Variational Autoencoder framework to address challenges arising from multi-lingual RS. CGM does so with expressive message conditional priors, mixture densities to enhance multi-lingual data representation, latent alignment for language discrimination, and effective variational optimization techniques for training multi-lingual RS. The enhancements result in performance that exceed competitive baselines in relevance (ROUGE score) by more than 10\% on average, and 16\% for low resource languages. CGM also shows remarkable improvements in diversity (80\%) illustrating its expressiveness in representation of multi-lingual data.
An Exploratory Study on Long Dialogue Summarization: What Works and What's Next
Sep 10, 2021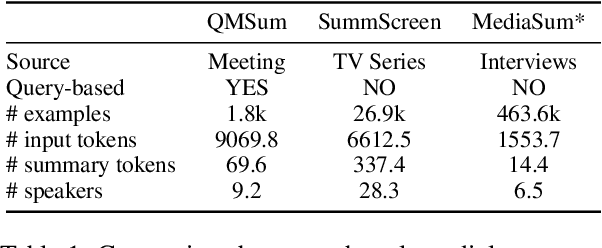
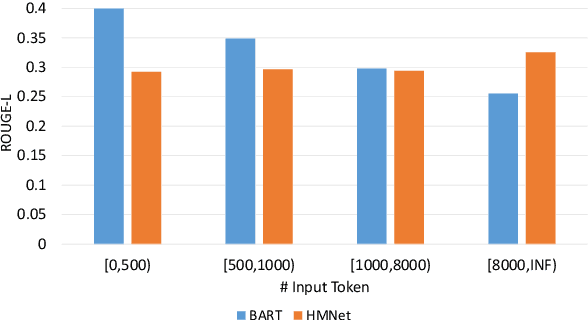

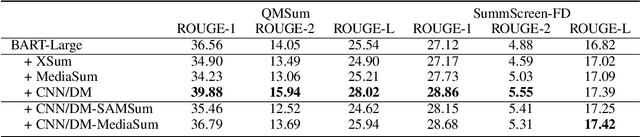
Dialogue summarization helps readers capture salient information from long conversations in meetings, interviews, and TV series. However, real-world dialogues pose a great challenge to current summarization models, as the dialogue length typically exceeds the input limits imposed by recent transformer-based pre-trained models, and the interactive nature of dialogues makes relevant information more context-dependent and sparsely distributed than news articles. In this work, we perform a comprehensive study on long dialogue summarization by investigating three strategies to deal with the lengthy input problem and locate relevant information: (1) extended transformer models such as Longformer, (2) retrieve-then-summarize pipeline models with several dialogue utterance retrieval methods, and (3) hierarchical dialogue encoding models such as HMNet. Our experimental results on three long dialogue datasets (QMSum, MediaSum, SummScreen) show that the retrieve-then-summarize pipeline models yield the best performance. We also demonstrate that the summary quality can be further improved with a stronger retrieval model and pretraining on proper external summarization datasets.
Language Scaling for Universal Suggested Replies Model
Jun 04, 2021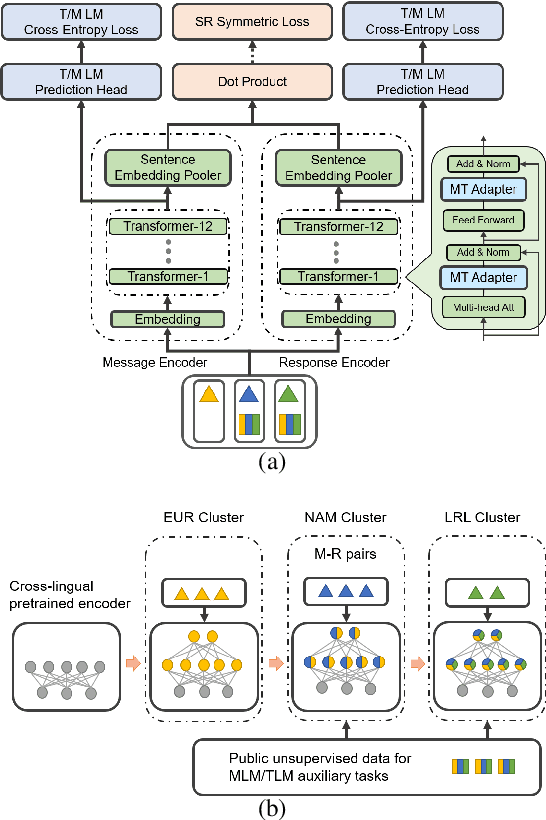

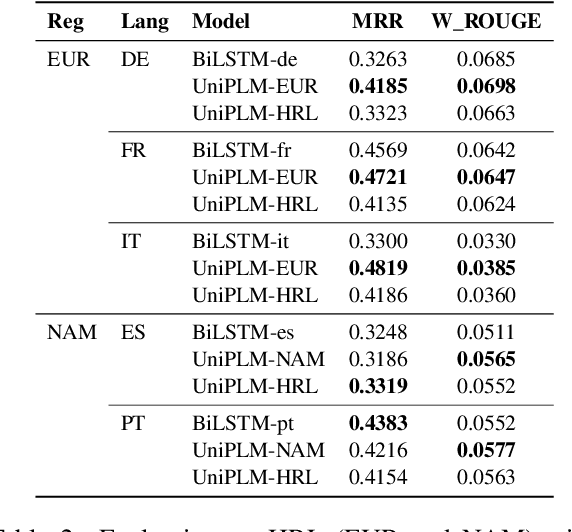
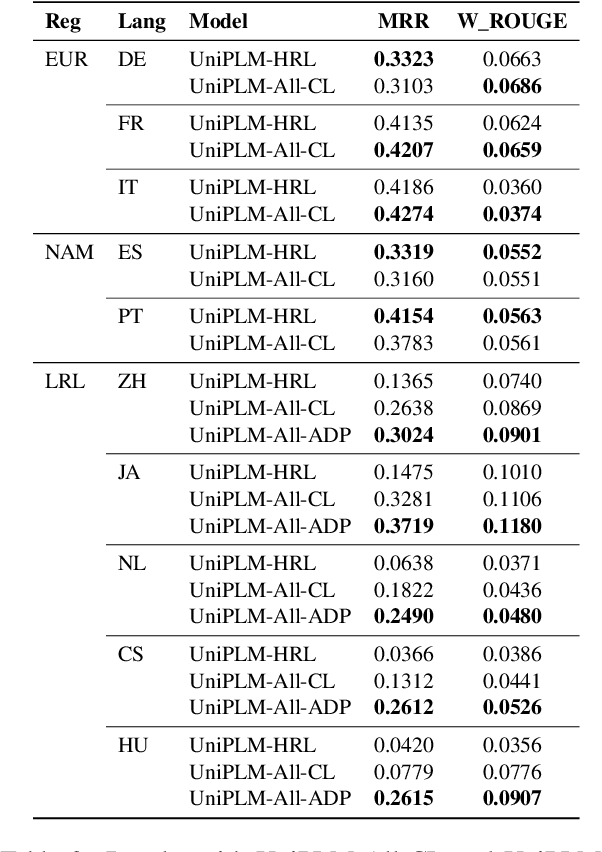
We consider the problem of scaling automated suggested replies for Outlook email system to multiple languages. Faced with increased compute requirements and low resources for language expansion, we build a single universal model for improving the quality and reducing run-time costs of our production system. However, restricted data movement across regional centers prevents joint training across languages. To this end, we propose a multi-task continual learning framework, with auxiliary tasks and language adapters to learn universal language representation across regions. The experimental results show positive cross-lingual transfer across languages while reducing catastrophic forgetting across regions. Our online results on real user traffic show significant gains in CTR and characters saved, as well as 65% training cost reduction compared with per-language models. As a consequence, we have scaled the feature in multiple languages including low-resource markets.
A Dataset and Baselines for Multilingual Reply Suggestion
Jun 03, 2021
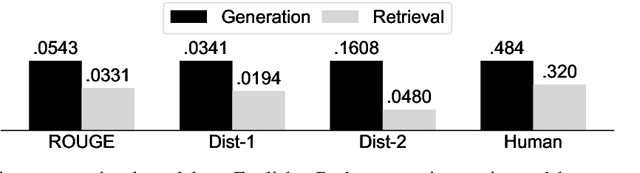

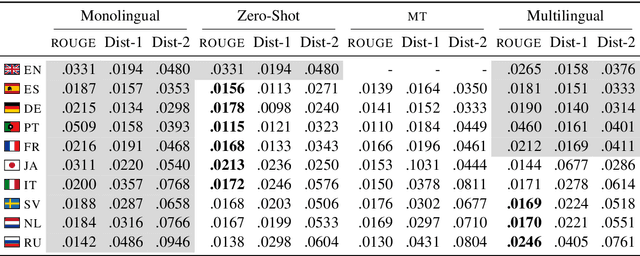
Reply suggestion models help users process emails and chats faster. Previous work only studies English reply suggestion. Instead, we present MRS, a multilingual reply suggestion dataset with ten languages. MRS can be used to compare two families of models: 1) retrieval models that select the reply from a fixed set and 2) generation models that produce the reply from scratch. Therefore, MRS complements existing cross-lingual generalization benchmarks that focus on classification and sequence labeling tasks. We build a generation model and a retrieval model as baselines for MRS. The two models have different strengths in the monolingual setting, and they require different strategies to generalize across languages. MRS is publicly available at https://github.com/zhangmozhi/mrs.
Diversifying Reply Suggestions using a Matching-Conditional Variational Autoencoder
Mar 25, 2019
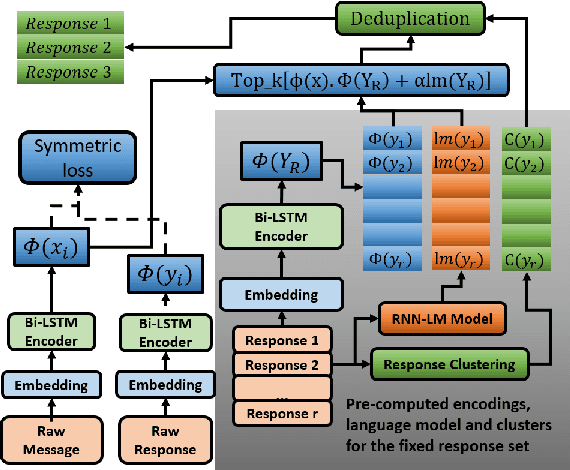

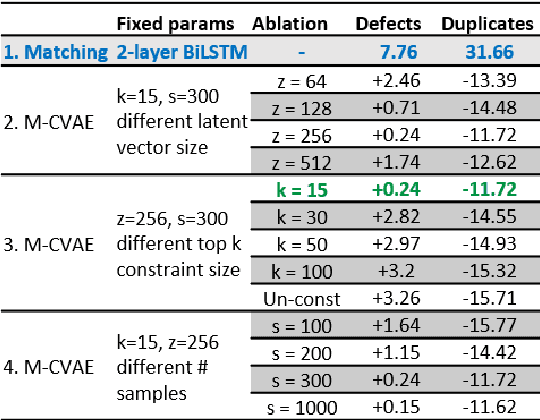
We consider the problem of diversifying automated reply suggestions for a commercial instant-messaging (IM) system (Skype). Our conversation model is a standard matching based information retrieval architecture, which consists of two parallel encoders to project messages and replies into a common feature representation. During inference, we select replies from a fixed response set using nearest neighbors in the feature space. To diversify responses, we formulate the model as a generative latent variable model with Conditional Variational Auto-Encoder (M-CVAE). We propose a constrained-sampling approach to make the variational inference in M-CVAE efficient for our production system. In offline experiments, M-CVAE consistently increased diversity by ~30-40% without significant impact on relevance. This translated to a 5% gain in click-rate in our online production system.