 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Deep Research: A Benchmark and Formal Definition
Aug 06, 2025Information tasks such as writing surveys or analytical reports require complex search and reasoning, and have recently been grouped under the umbrella of \textit{deep research} -- a term also adopted by recent models targeting these capabilities. Despite growing interest, the scope of the deep research task remains underdefined and its distinction from other reasoning-intensive problems is poorly understood. In this paper, we propose a formal characterization of the deep research (DR) task and introduce a benchmark to evaluate the performance of DR systems. We argue that the core defining feature of deep research is not the production of lengthy report-style outputs, but rather the high fan-out over concepts required during the search process, i.e., broad and reasoning-intensive exploration. To enable objective evaluation, we define DR using an intermediate output representation that encodes key claims uncovered during search-separating the reasoning challenge from surface-level report generation. Based on this formulation, we propose a diverse, challenging benchmark LiveDRBench with 100 challenging tasks over scientific topics (e.g., datasets, materials discovery, prior art search) and public interest events (e.g., flight incidents, movie awards). Across state-of-the-art DR systems, F1 score ranges between 0.02 and 0.72 for any sub-category. OpenAI's model performs the best with an overall F1 score of 0.55. Analysis of reasoning traces reveals the distribution over the number of referenced sources, branching, and backtracking events executed by current DR systems, motivating future directions for improving their search mechanisms and grounding capabilities. The benchmark is available at https://github.com/microsoft/LiveDRBench.
Wikibench: Community-Driven Data Curation for AI Evaluation on Wikipedia
Feb 21, 2024AI tools are increasingly deployed in community contexts. However, datasets used to evaluate AI are typically created by developers and annotators outside a given community, which can yield misleading conclusions about AI performance. How might we empower communities to drive the intentional design and curation of evaluation datasets for AI that impacts them? We investigate this question on Wikipedia, an online community with multiple AI-based content moderation tools deployed. We introduce Wikibench, a system that enables communities to collaboratively curate AI evaluation datasets, while navigating ambiguities and differences in perspective through discussion. A field study on Wikipedia shows that datasets curated using Wikibench can effectively capture community consensus, disagreement, and uncertainty. Furthermore, study participants used Wikibench to shape the overall data curation process, including refining label definitions, determining data inclusion criteria, and authoring data statements. Based on our findings, we propose future directions for systems that support community-driven data curation.
Summaries, Highlights, and Action items: Design, implementation and evaluation of an LLM-powered meeting recap system
Jul 28, 2023



Meetings play a critical infrastructural role in the coordination of work. In recent years, due to shift to hybrid and remote work, more meetings are moving to online Computer Mediated Spaces. This has led to new problems (e.g. more time spent in less engaging meetings) and new opportunities (e.g. automated transcription/captioning and recap support). Recent advances in large language models (LLMs) for dialog summarization have the potential to improve the experience of meetings by reducing individuals' meeting load and increasing the clarity and alignment of meeting outputs. Despite this potential, they face technological limitation due to long transcripts and inability to capture diverse recap needs based on user's context. To address these gaps, we design, implement and evaluate in-context a meeting recap system. We first conceptualize two salient recap representations -- important highlights, and a structured, hierarchical minutes view. We develop a system to operationalize the representations with dialogue summarization as its building blocks. Finally, we evaluate the effectiveness of the system with seven users in the context of their work meetings. Our findings show promise in using LLM-based dialogue summarization for meeting recap and the need for both representations in different contexts. However, we find that LLM-based recap still lacks an understanding of whats personally relevant to participants, can miss important details, and mis-attributions can be detrimental to group dynamics. We identify collaboration opportunities such as a shared recap document that a high quality recap enables. We report on implications for designing AI systems to partner with users to learn and improve from natural interactions to overcome the limitations related to personal relevance and summarization quality.
On Improving Summarization Factual Consistency from Natural Language Feedback
Dec 20, 2022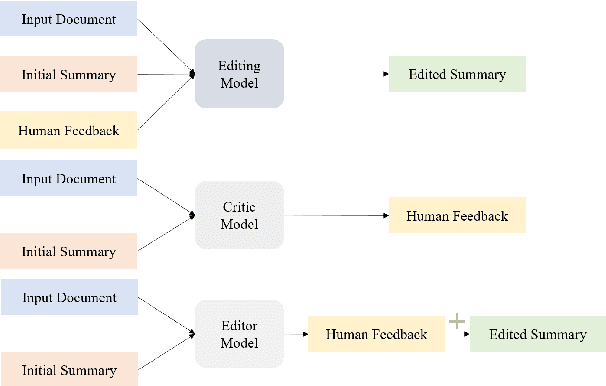
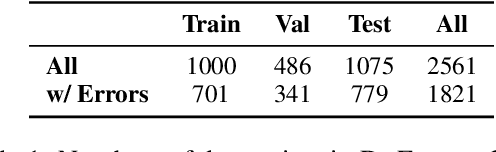

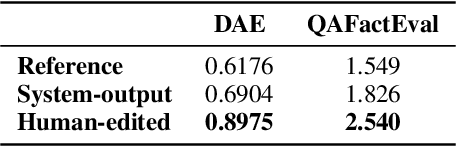
Despite the recent progress in language generation models, their outputs may not always meet user expectations. In this work, we study whether informational feedback in natural language can be leveraged to improve generation quality and user preference alignment. To this end, we consider factual consistency in summarization, the quality that the summary should only contain information supported by the input documents, for user preference alignment. We collect a high-quality dataset, DeFacto, containing human demonstrations and informational feedback in natural language consisting of corrective instructions, edited summaries, and explanations with respect to the factual consistency of the summary. Using our dataset, we study two natural language generation tasks: 1) editing a summary using the human feedback, and 2) generating human feedback from the original summary. Using the two tasks, we further evaluate if models can automatically correct factual inconsistencies in generated summaries. We show that the human-edited summaries we collected are more factually consistent, and pre-trained language models can leverage our dataset to improve the factual consistency of original system-generated summaries in our proposed generation tasks. We make the DeFacto dataset publicly available at https://github.com/microsoft/DeFacto.
The effects of algorithmic flagging on fairness: quasi-experimental evidence from Wikipedia
Jun 04, 2020


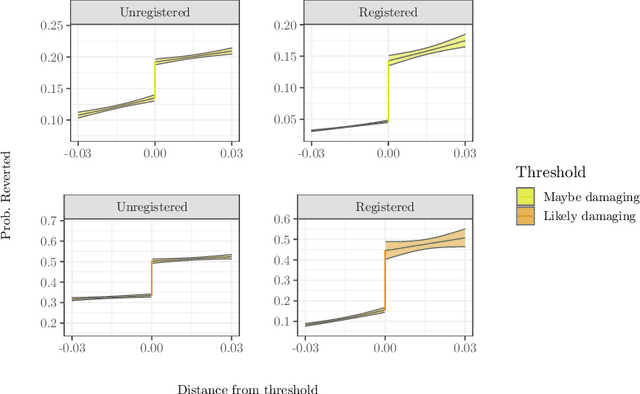
Online community moderators often rely on social signals like whether or not a user has an account or a profile page as clues that users are likely to cause problems. Reliance on these clues may lead to "over-profiling" bias when moderators focus on these signals but overlook misbehavior by others. We propose that algorithmic flagging systems deployed to improve efficiency of moderation work can also make moderation actions more fair to these users by reducing reliance on social signals and making norm violations by everyone else more visible. We analyze moderator behavior in Wikipedia as mediated by a system called RCFilters that displays social signals and algorithmic flags and to estimate the causal effect of being flagged on moderator actions. We show that algorithmically flagged edits are reverted more often, especially edits by established editors with positive social signals, and that flagging decreases the likelihood that moderation actions will be undone. Our results suggest that algorithmic flagging systems can lead to increased fairness but that the relationship is complex and contingent.
Keeping Community in the Loop: Understanding Wikipedia Stakeholder Values for Machine Learning-Based Systems
Jan 14, 2020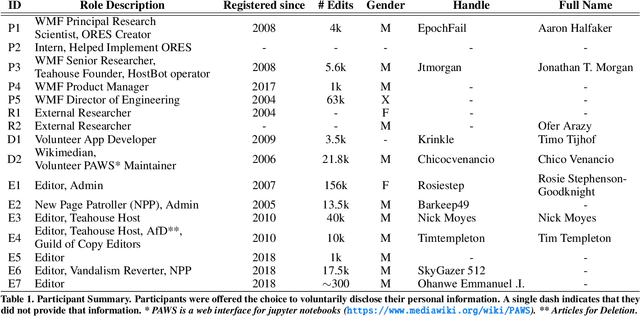
On Wikipedia, sophisticated algorithmic tools are used to assess the quality of edits and take corrective actions. However, algorithms can fail to solve the problems they were designed for if they conflict with the values of communities who use them. In this study, we take a Value-Sensitive Algorithm Design approach to understanding a community-created and -maintained machine learning-based algorithm called the Objective Revision Evaluation System (ORES)---a quality prediction system used in numerous Wikipedia applications and contexts. Five major values converged across stakeholder groups that ORES (and its dependent applications) should: (1) reduce the effort of community maintenance, (2) maintain human judgement as the final authority, (3) support differing peoples' differing workflows, (4) encourage positive engagement with diverse editor groups, and (5) establish trustworthiness of people and algorithms within the community. We reveal tensions between these values and discuss implications for future research to improve algorithms like ORES.
ORES: Lowering Barriers with Participatory Machine Learning in Wikipedia
Sep 13, 2019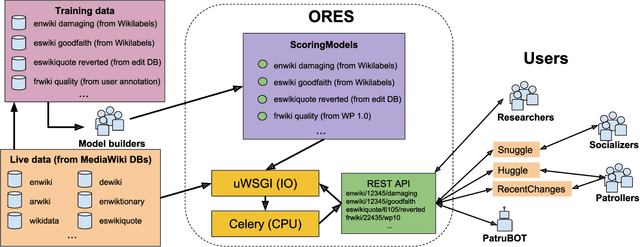
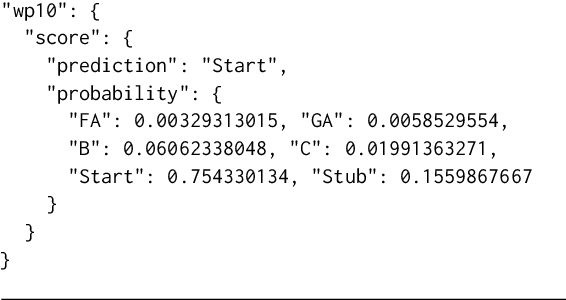


Algorithmic systems -- from rule-based bots to machine learning classifiers -- have a long history of supporting the essential work of content moderation and other curation work in peer production projects. From counter-vandalism to task routing, basic machine prediction has allowed open knowledge projects like Wikipedia to scale to the largest encyclopedia in the world, while maintaining quality and consistency. However, conversations about how quality control should work and what role algorithms should play have generally been led by the expert engineers who have the skills and resources to develop and modify these complex algorithmic systems. In this paper, we describe ORES: an algorithmic scoring service that supports real-time scoring of wiki edits using multiple independent classifiers trained on different datasets. ORES decouples several activities that have typically all been performed by engineers: choosing or curating training data, building models to serve predictions, auditing predictions, and developing interfaces or automated agents that act on those predictions. This meta-algorithmic system was designed to open up socio-technical conversations about algorithmic systems in Wikipedia to a broader set of participants. In this paper, we discuss the theoretical mechanisms of social change ORES enables and detail case studies in participatory machine learning around ORES from the 4 years since its deployment.
PreCall: A Visual Interface for Threshold Optimization in ML Model Selection
Jul 11, 2019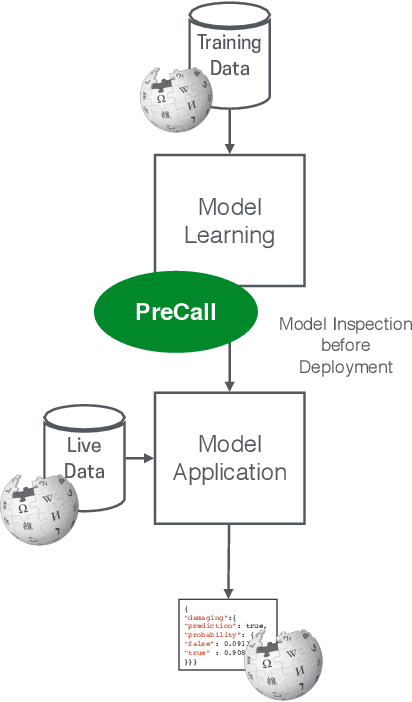
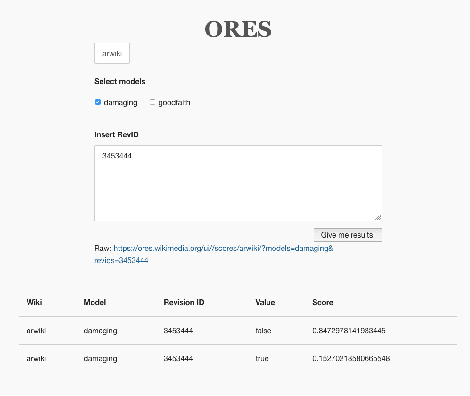
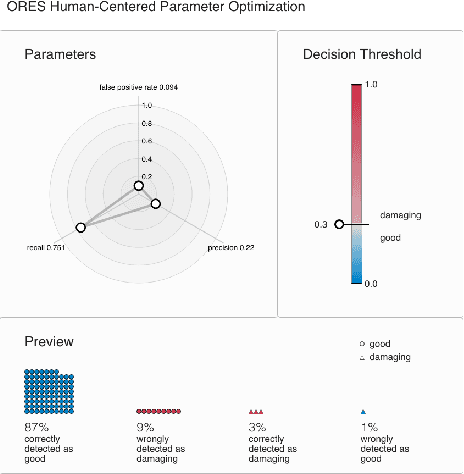
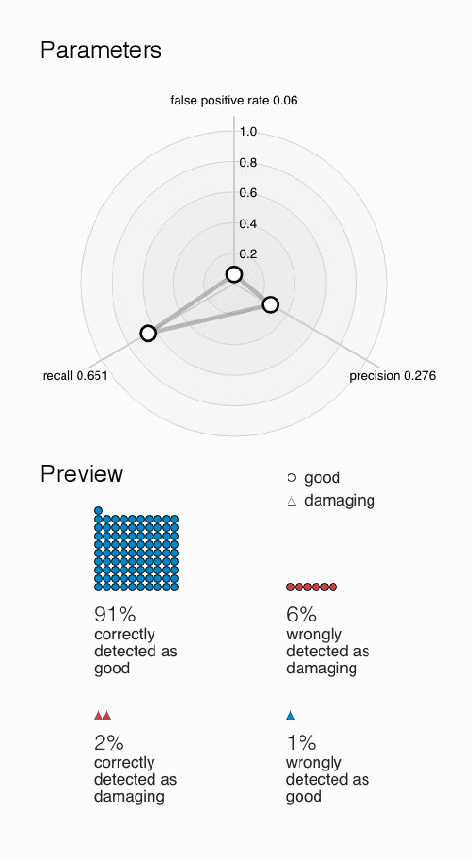
Machine learning systems are ubiquitous in various kinds of digital applications and have a huge impact on our everyday life. But a lack of explainability and interpretability of such systems hinders meaningful participation by people, especially by those without a technical background. Interactive visual interfaces (e.g., providing means for manipulating parameters in the user interface) can help tackle this challenge. In this paper we present PreCall, an interactive visual interface for ORES, a machine learning-based web service for Wikimedia projects such as Wikipedia. While ORES can be used for a number of settings, it can be challenging to translate requirements from the application domain into formal parameter sets needed to configure the ORES models. Assisting Wikipedia editors in finding damaging edits, for example, can be realized at various stages of automatization, which might impact the precision of the applied model. Our prototype PreCall attempts to close this translation gap by interactively visualizing the relationship between major model metrics (recall, precision, false positive rate) and a parameter (the threshold between valuable and damaging edits). Furthermore, PreCall visualizes the probable results for the current model configuration to improve the human's understanding of the relationship between metrics and outcome when using ORES. We describe PreCall's components and present a use case that highlights the benefits of our approach. Finally, we pose further research questions we would like to discuss during the workshop.