 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Deep Research: A Benchmark and Formal Definition
Aug 06, 2025Information tasks such as writing surveys or analytical reports require complex search and reasoning, and have recently been grouped under the umbrella of \textit{deep research} -- a term also adopted by recent models targeting these capabilities. Despite growing interest, the scope of the deep research task remains underdefined and its distinction from other reasoning-intensive problems is poorly understood. In this paper, we propose a formal characterization of the deep research (DR) task and introduce a benchmark to evaluate the performance of DR systems. We argue that the core defining feature of deep research is not the production of lengthy report-style outputs, but rather the high fan-out over concepts required during the search process, i.e., broad and reasoning-intensive exploration. To enable objective evaluation, we define DR using an intermediate output representation that encodes key claims uncovered during search-separating the reasoning challenge from surface-level report generation. Based on this formulation, we propose a diverse, challenging benchmark LiveDRBench with 100 challenging tasks over scientific topics (e.g., datasets, materials discovery, prior art search) and public interest events (e.g., flight incidents, movie awards). Across state-of-the-art DR systems, F1 score ranges between 0.02 and 0.72 for any sub-category. OpenAI's model performs the best with an overall F1 score of 0.55. Analysis of reasoning traces reveals the distribution over the number of referenced sources, branching, and backtracking events executed by current DR systems, motivating future directions for improving their search mechanisms and grounding capabilities. The benchmark is available at https://github.com/microsoft/LiveDRBench.
FrugalRAG: Learning to retrieve and reason for multi-hop QA
Jul 10, 2025We consider the problem of answering complex questions, given access to a large unstructured document corpus. The de facto approach to solving the problem is to leverage language models that (iteratively) retrieve and reason through the retrieved documents, until the model has sufficient information to generate an answer. Attempts at improving this approach focus on retrieval-augmented generation (RAG) metrics such as accuracy and recall and can be categorized into two types: (a) fine-tuning on large question answering (QA) datasets augmented with chain-of-thought traces, and (b) leveraging RL-based fine-tuning techniques that rely on question-document relevance signals. However, efficiency in the number of retrieval searches is an equally important metric, which has received less attention. In this work, we show that: (1) Large-scale fine-tuning is not needed to improve RAG metrics, contrary to popular claims in recent literature. Specifically, a standard ReAct pipeline with improved prompts can outperform state-of-the-art methods on benchmarks such as HotPotQA. (2) Supervised and RL-based fine-tuning can help RAG from the perspective of frugality, i.e., the latency due to number of searches at inference time. For example, we show that we can achieve competitive RAG metrics at nearly half the cost (in terms of number of searches) on popular RAG benchmarks, using the same base model, and at a small training cost (1000 examples).
Towards Operationalizing Right to Data Protection
Nov 16, 2024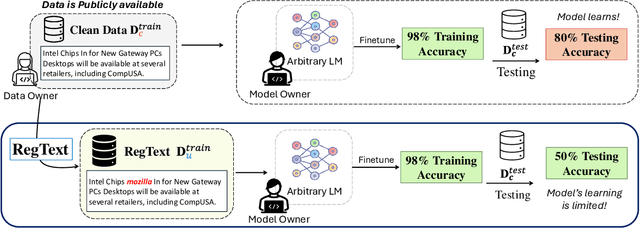
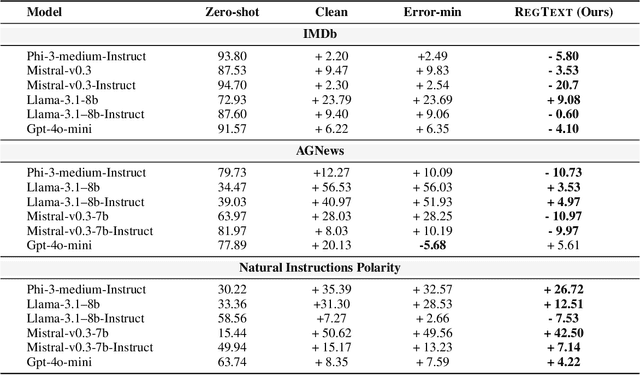
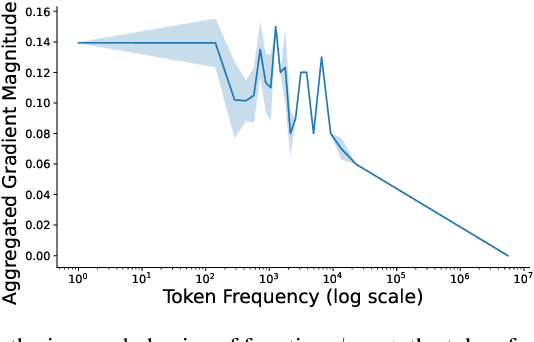
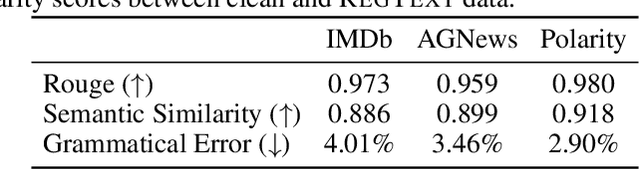
The widespread practice of indiscriminate data scraping to fine-tune language models (LMs) raises significant legal and ethical concerns, particularly regarding compliance with data protection laws such as the General Data Protection Regulation (GDPR). This practice often results in the unauthorized use of personal information, prompting growing debate within the academic and regulatory communities. Recent works have introduced the concept of generating unlearnable datasets (by adding imperceptible noise to the clean data), such that the underlying model achieves lower loss during training but fails to generalize to the unseen test setting. Though somewhat effective, these approaches are predominantly designed for images and are limited by several practical constraints like requiring knowledge of the target model. To this end, we introduce RegText, a framework that injects imperceptible spurious correlations into natural language datasets, effectively rendering them unlearnable without affecting semantic content. We demonstrate RegText's utility through rigorous empirical analysis of small and large LMs. Notably, RegText can restrict newer models like GPT-4o and Llama from learning on our generated data, resulting in a drop in their test accuracy compared to their zero-shot performance and paving the way for generating unlearnable text to protect public data.
ReEdit: Multimodal Exemplar-Based Image Editing with Diffusion Models
Nov 06, 2024



Modern Text-to-Image (T2I) Diffusion models have revolutionized image editing by enabling the generation of high-quality photorealistic images. While the de facto method for performing edits with T2I models is through text instructions, this approach non-trivial due to the complex many-to-many mapping between natural language and images. In this work, we address exemplar-based image editing -- the task of transferring an edit from an exemplar pair to a content image(s). We propose ReEdit, a modular and efficient end-to-end framework that captures edits in both text and image modalities while ensuring the fidelity of the edited image. We validate the effectiveness of ReEdit through extensive comparisons with state-of-the-art baselines and sensitivity analyses of key design choices. Our results demonstrate that ReEdit consistently outperforms contemporary approaches both qualitatively and quantitatively. Additionally, ReEdit boasts high practical applicability, as it does not require any task-specific optimization and is four times faster than the next best baseline.
LEAST: "Local" text-conditioned image style transfer
May 25, 2024Text-conditioned style transfer enables users to communicate their desired artistic styles through text descriptions, offering a new and expressive means of achieving stylization. In this work, we evaluate the text-conditioned image editing and style transfer techniques on their fine-grained understanding of user prompts for precise "local" style transfer. We find that current methods fail to accomplish localized style transfers effectively, either failing to localize style transfer to certain regions in the image, or distorting the content and structure of the input image. To this end, we carefully design an end-to-end pipeline that guarantees local style transfer according to users' intent. Further, we substantiate the effectiveness of our approach through quantitative and qualitative analysis. The project code is available at: https://github.com/silky1708/local-style-transfer.
Thinking Fair and Slow: On the Efficacy of Structured Prompts for Debiasing Language Models
May 16, 2024
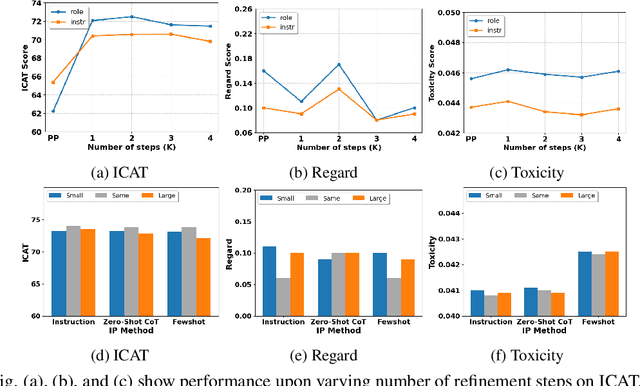
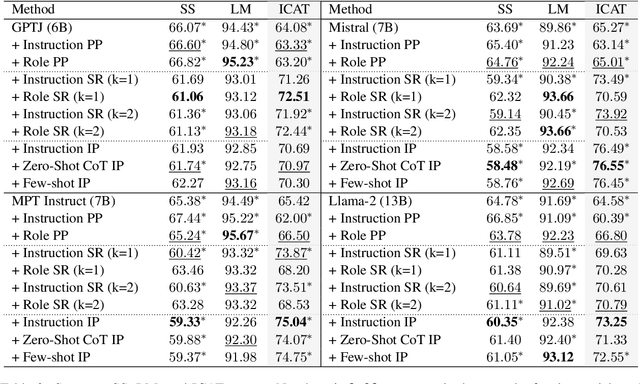
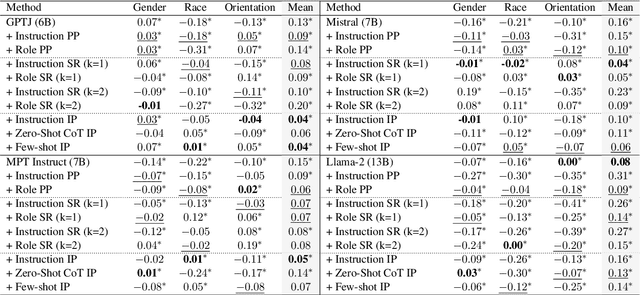
Existing debiasing techniques are typically training-based or require access to the model's internals and output distributions, so they are inaccessible to end-users looking to adapt LLM outputs for their particular needs. In this study, we examine whether structured prompting techniques can offer opportunities for fair text generation. We evaluate a comprehensive end-user-focused iterative framework of debiasing that applies System 2 thinking processes for prompts to induce logical, reflective, and critical text generation, with single, multi-step, instruction, and role-based variants. By systematically evaluating many LLMs across many datasets and different prompting strategies, we show that the more complex System 2-based Implicative Prompts significantly improve over other techniques demonstrating lower mean bias in the outputs with competitive performance on the downstream tasks. Our work offers research directions for the design and the potential of end-user-focused evaluative frameworks for LLM use.
All Should Be Equal in the Eyes of Language Models: Counterfactually Aware Fair Text Generation
Nov 09, 2023Fairness in Language Models (LMs) remains a longstanding challenge, given the inherent biases in training data that can be perpetuated by models and affect the downstream tasks. Recent methods employ expensive retraining or attempt debiasing during inference by constraining model outputs to contrast from a reference set of biased templates or exemplars. Regardless, they dont address the primary goal of fairness to maintain equitability across different demographic groups. In this work, we posit that inferencing LMs to generate unbiased output for one demographic under a context ensues from being aware of outputs for other demographics under the same context. To this end, we propose Counterfactually Aware Fair InferencE (CAFIE), a framework that dynamically compares the model understanding of diverse demographics to generate more equitable sentences. We conduct an extensive empirical evaluation using base LMs of varying sizes and across three diverse datasets and found that CAFIE outperforms strong baselines. CAFIE produces fairer text and strikes the best balance between fairness and language modeling capability
One-Shot Doc Snippet Detection: Powering Search in Document Beyond Text
Sep 12, 2022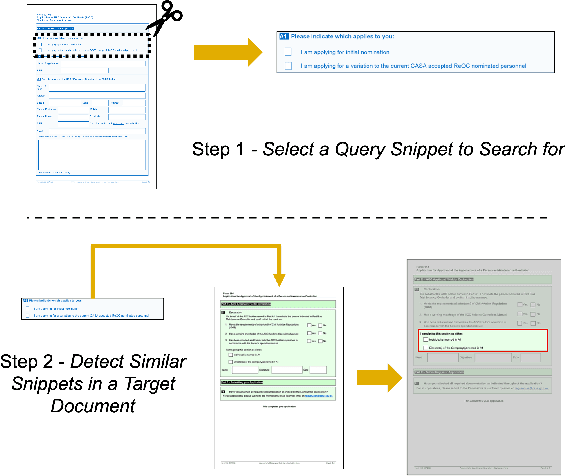


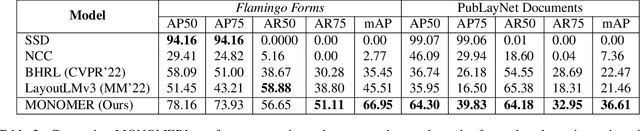
Active consumption of digital documents has yielded scope for research in various applications, including search. Traditionally, searching within a document has been cast as a text matching problem ignoring the rich layout and visual cues commonly present in structured documents, forms, etc. To that end, we ask a mostly unexplored question: "Can we search for other similar snippets present in a target document page given a single query instance of a document snippet?". We propose MONOMER to solve this as a one-shot snippet detection task. MONOMER fuses context from visual, textual, and spatial modalities of snippets and documents to find query snippet in target documents. We conduct extensive ablations and experiments showing MONOMER outperforms several baselines from one-shot object detection (BHRL), template matching, and document understanding (LayoutLMv3). Due to the scarcity of relevant data for the task at hand, we train MONOMER on programmatically generated data having many visually similar query snippets and target document pairs from two datasets - Flamingo Forms and PubLayNet. We also do a human study to validate the generated data.
Learning to Censor by Noisy Sampling
Mar 23, 2022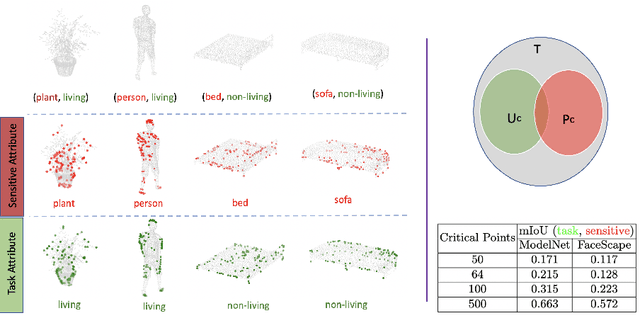
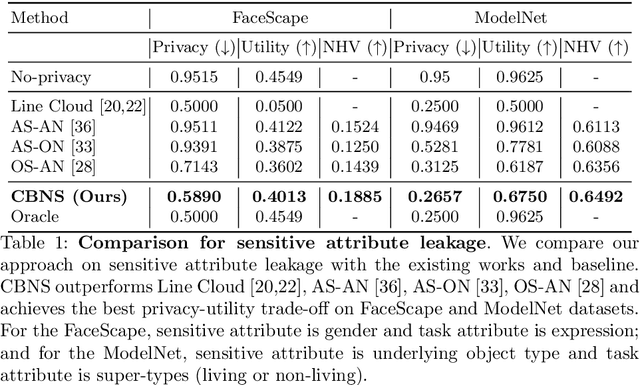

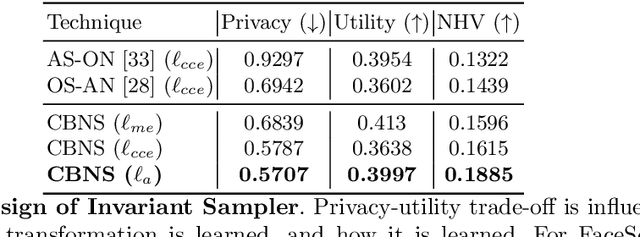
Point clouds are an increasingly ubiquitous input modality and the raw signal can be efficiently processed with recent progress in deep learning. This signal may, often inadvertently, capture sensitive information that can leak semantic and geometric properties of the scene which the data owner does not want to share. The goal of this work is to protect sensitive information when learning from point clouds; by censoring the sensitive information before the point cloud is released for downstream tasks. Specifically, we focus on preserving utility for perception tasks while mitigating attribute leakage attacks. The key motivating insight is to leverage the localized saliency of perception tasks on point clouds to provide good privacy-utility trade-offs. We realize this through a mechanism called Censoring by Noisy Sampling (CBNS), which is composed of two modules: i) Invariant Sampler: a differentiable point-cloud sampler which learns to remove points invariant to utility and ii) Noisy Distorter: which learns to distort sampled points to decouple the sensitive information from utility, and mitigate privacy leakage. We validate the effectiveness of CBNS through extensive comparisons with state-of-the-art baselines and sensitivity analyses of key design choices. Results show that CBNS achieves superior privacy-utility trade-offs on multiple datasets.
AdaSplit: Adaptive Trade-offs for Resource-constrained Distributed Deep Learning
Dec 02, 2021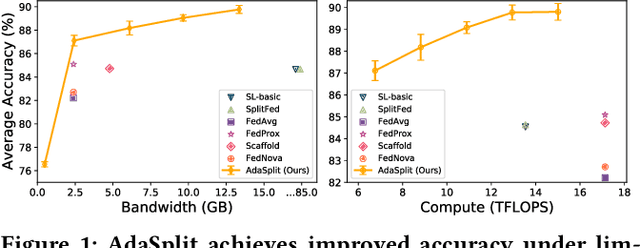
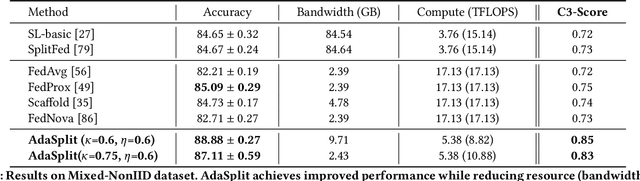
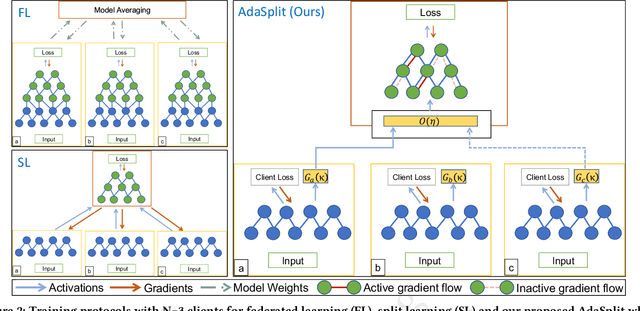
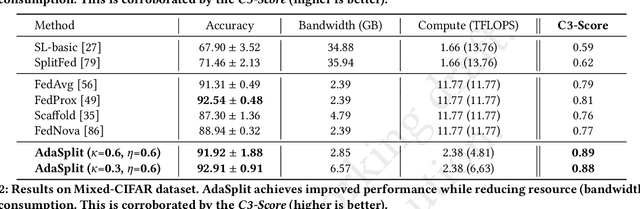
Distributed deep learning frameworks like federated learning (FL) and its variants are enabling personalized experiences across a wide range of web clients and mobile/IoT devices. However, FL-based frameworks are constrained by computational resources at clients due to the exploding growth of model parameters (eg. billion parameter model). Split learning (SL), a recent framework, reduces client compute load by splitting the model training between client and server. This flexibility is extremely useful for low-compute setups but is often achieved at cost of increase in bandwidth consumption and may result in sub-optimal convergence, especially when client data is heterogeneous. In this work, we introduce AdaSplit which enables efficiently scaling SL to low resource scenarios by reducing bandwidth consumption and improving performance across heterogeneous clients. To capture and benchmark this multi-dimensional nature of distributed deep learning, we also introduce C3-Score, a metric to evaluate performance under resource budgets. We validate the effectiveness of AdaSplit under limited resources through extensive experimental comparison with strong federated and split learning baselines. We also present a sensitivity analysis of key design choices in AdaSplit which validates the ability of AdaSplit to provide adaptive trade-offs across variable resource budgets.