 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Memorization in Large Language Models through the Lens of Model Attribution
Jan 09, 2025



Large Language Models (LLMs) are prevalent in modern applications but often memorize training data, leading to privacy breaches and copyright issues. Existing research has mainly focused on posthoc analyses, such as extracting memorized content or developing memorization metrics, without exploring the underlying architectural factors that contribute to memorization. In this work, we investigate memorization from an architectural lens by analyzing how attention modules at different layers impact its memorization and generalization performance. Using attribution techniques, we systematically intervene in the LLM architecture by bypassing attention modules at specific blocks while keeping other components like layer normalization and MLP transformations intact. We provide theorems analyzing our intervention mechanism from a mathematical view, bounding the difference in layer outputs with and without our attributions. Our theoretical and empirical analyses reveal that attention modules in deeper transformer blocks are primarily responsible for memorization, whereas earlier blocks are crucial for the models generalization and reasoning capabilities. We validate our findings through comprehensive experiments on different LLM families (Pythia and GPTNeo) and five benchmark datasets. Our insights offer a practical approach to mitigate memorization in LLMs while preserving their performance, contributing to safer and more ethical deployment in real world applications.
DoPTA: Improving Document Layout Analysis using Patch-Text Alignment
Dec 17, 2024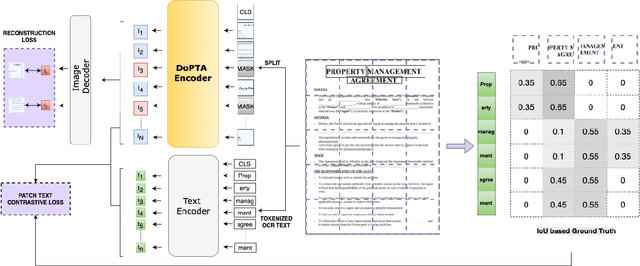
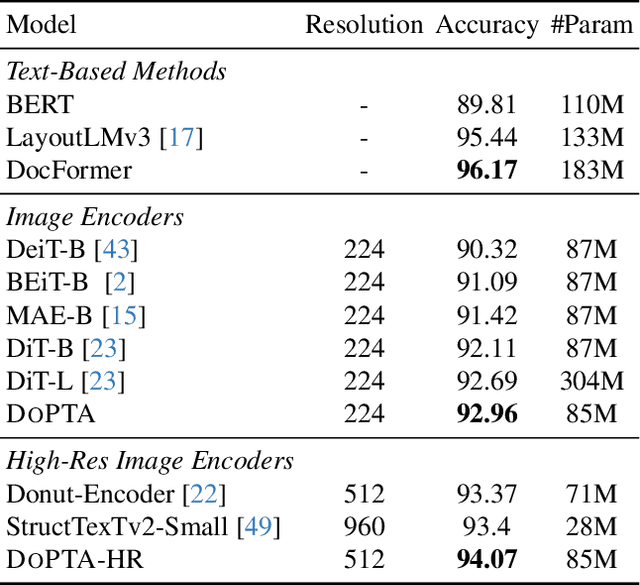

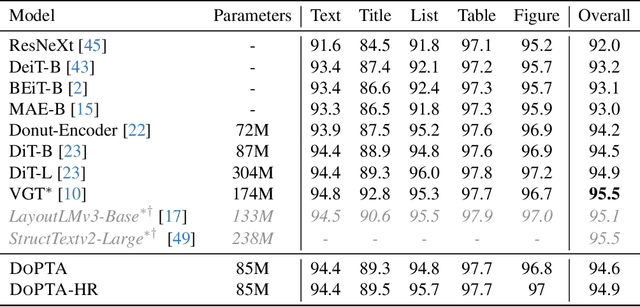
The advent of multimodal learning has brought a significant improvement in document AI. Documents are now treated as multimodal entities, incorporating both textual and visual information for downstream analysis. However, works in this space are often focused on the textual aspect, using the visual space as auxiliary information. While some works have explored pure vision based techniques for document image understanding, they require OCR identified text as input during inference, or do not align with text in their learning procedure. Therefore, we present a novel image-text alignment technique specially designed for leveraging the textual information in document images to improve performance on visual tasks. Our document encoder model DoPTA - trained with this technique demonstrates strong performance on a wide range of document image understanding tasks, without requiring OCR during inference. Combined with an auxiliary reconstruction objective, DoPTA consistently outperforms larger models, while using significantly lesser pre-training compute. DoPTA also sets new state-of-the art results on D4LA, and FUNSD, two challenging document visual analysis benchmarks.
ReEdit: Multimodal Exemplar-Based Image Editing with Diffusion Models
Nov 06, 2024



Modern Text-to-Image (T2I) Diffusion models have revolutionized image editing by enabling the generation of high-quality photorealistic images. While the de facto method for performing edits with T2I models is through text instructions, this approach non-trivial due to the complex many-to-many mapping between natural language and images. In this work, we address exemplar-based image editing -- the task of transferring an edit from an exemplar pair to a content image(s). We propose ReEdit, a modular and efficient end-to-end framework that captures edits in both text and image modalities while ensuring the fidelity of the edited image. We validate the effectiveness of ReEdit through extensive comparisons with state-of-the-art baselines and sensitivity analyses of key design choices. Our results demonstrate that ReEdit consistently outperforms contemporary approaches both qualitatively and quantitatively. Additionally, ReEdit boasts high practical applicability, as it does not require any task-specific optimization and is four times faster than the next best baseline.
Towards Estimating Transferability using Hard Subsets
Jan 17, 2023
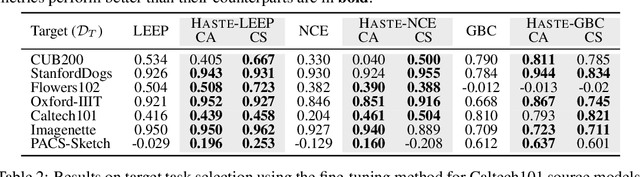
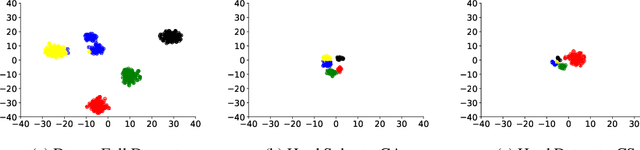
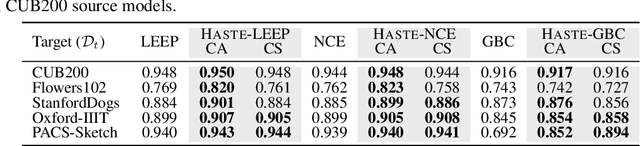
As transfer learning techniques are increasingly used to transfer knowledge from the source model to the target task, it becomes important to quantify which source models are suitable for a given target task without performing computationally expensive fine tuning. In this work, we propose HASTE (HArd Subset TransfErability), a new strategy to estimate the transferability of a source model to a particular target task using only a harder subset of target data. By leveraging the internal and output representations of model, we introduce two techniques, one class agnostic and another class specific, to identify harder subsets and show that HASTE can be used with any existing transferability metric to improve their reliability. We further analyze the relation between HASTE and the optimal average log likelihood as well as negative conditional entropy and empirically validate our theoretical bounds. Our experimental results across multiple source model architectures, target datasets, and transfer learning tasks show that HASTE modified metrics are consistently better or on par with the state of the art transferability metrics.
Improving Attribution Methods by Learning Submodular Functions
Apr 27, 2021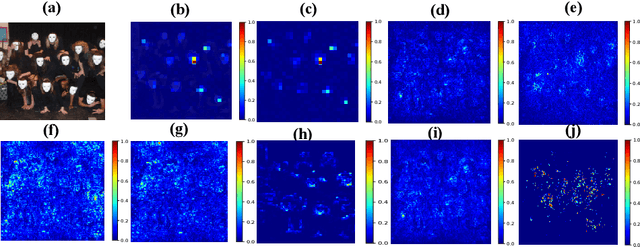
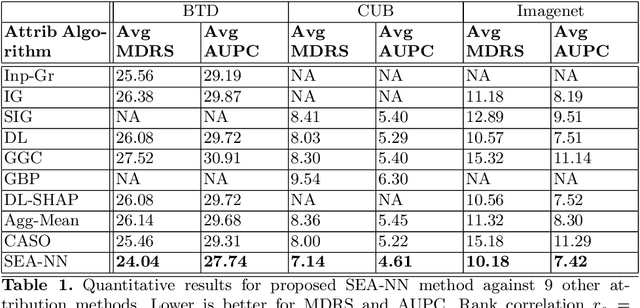
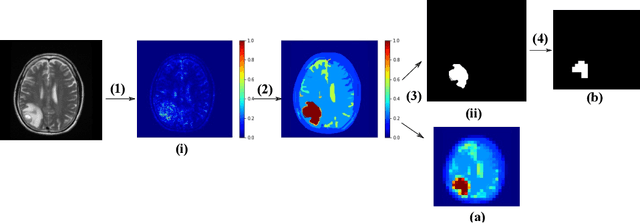
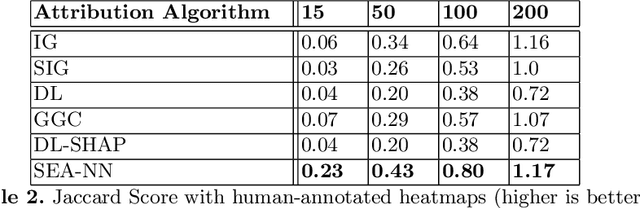
This work explores the novel idea of learning a submodular scoring function to improve the specificity/selectivity of existing feature attribution methods. Submodular scores are natural for attribution as they are known to accurately model the principle of diminishing returns. A new formulation for learning a deep submodular set function that is consistent with the real-valued attribution maps obtained by existing attribution methods is proposed. This formulation not only ensures that the scores for the heat maps that include the highly attributed features across the existing methods are high, but also that the score saturates even for the most specific heat map. The final attribution value of a feature is then defined as the marginal gain in the induced submodular score of the feature in the context of other highly attributed features, thus decreasing the attribution of redundant yet discriminatory features. Experiments on multiple datasets illustrate that the proposed attribution method achieves higher specificity while not degrading the discriminative power.