 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExponential Convergence of (Stochastic) Gradient Descent for Separable Logistic Regression
Feb 21, 2026Gradient descent and stochastic gradient descent are central to modern machine learning, yet their behavior under large step sizes remains theoretically unclear. Recent work suggests that acceleration often arises near the edge of stability, where optimization trajectories become unstable and difficult to analyze. Existing results for separable logistic regression achieve faster convergence by explicitly leveraging such unstable regimes through constant or adaptive large step sizes. In this paper, we show that instability is not inherent to acceleration. We prove that gradient descent with a simple, non-adaptive increasing step-size schedule achieves exponential convergence for separable logistic regression under a margin condition, while remaining entirely within a stable optimization regime. The resulting method is anytime and does not require prior knowledge of the optimization horizon or target accuracy. We also establish exponential convergence of stochastic gradient descent using a lightweight adaptive step-size rule that avoids line search and specialized procedures, improving upon existing polynomial-rate guarantees. Together, our results demonstrate that carefully structured step-size growth alone suffices to obtain exponential acceleration for both gradient descent and stochastic gradient descent.
Multi-agent Multi-armed Bandits with Minimum Reward Guarantee Fairness
Feb 21, 2025We investigate the problem of maximizing social welfare while ensuring fairness in a multi-agent multi-armed bandit (MA-MAB) setting. In this problem, a centralized decision-maker takes actions over time, generating random rewards for various agents. Our goal is to maximize the sum of expected cumulative rewards, a.k.a. social welfare, while ensuring that each agent receives an expected reward that is at least a constant fraction of the maximum possible expected reward. Our proposed algorithm, RewardFairUCB, leverages the Upper Confidence Bound (UCB) technique to achieve sublinear regret bounds for both fairness and social welfare. The fairness regret measures the positive difference between the minimum reward guarantee and the expected reward of a given policy, whereas the social welfare regret measures the difference between the social welfare of the optimal fair policy and that of the given policy. We show that RewardFairUCB algorithm achieves instance-independent social welfare regret guarantees of $\tilde{O}(T^{1/2})$ and a fairness regret upper bound of $\tilde{O}(T^{3/4})$. We also give the lower bound of $\Omega(\sqrt{T})$ for both social welfare and fairness regret. We evaluate RewardFairUCB's performance against various baseline and heuristic algorithms using simulated data and real world data, highlighting trade-offs between fairness and social welfare regrets.
Submodular Framework for Structured-Sparse Optimal Transport
Jun 07, 2024Unbalanced optimal transport (UOT) has recently gained much attention due to its flexible framework for handling un-normalized measures and its robustness properties. In this work, we explore learning (structured) sparse transport plans in the UOT setting, i.e., transport plans have an upper bound on the number of non-sparse entries in each column (structured sparse pattern) or in the whole plan (general sparse pattern). We propose novel sparsity-constrained UOT formulations building on the recently explored maximum mean discrepancy based UOT. We show that the proposed optimization problem is equivalent to the maximization of a weakly submodular function over a uniform matroid or a partition matroid. We develop efficient gradient-based discrete greedy algorithms and provide the corresponding theoretical guarantees. Empirically, we observe that our proposed greedy algorithms select a diverse support set and we illustrate the efficacy of the proposed approach in various applications.
Empirical Optimal Transport between Conditional Distributions
May 25, 2023Given samples from two joint distributions, we consider the problem of Optimal Transportation (OT) between the corresponding distributions conditioned on a common variable. The objective of this work is to estimate the associated transport cost (Wasserstein distance) as well as the transport plan between the conditionals as a function of the conditioned value. Since matching conditional distributions is at the core of supervised training of discriminative models and (implicit) conditional-generative models, OT between conditionals has the potential to be employed in diverse machine learning applications. However, since the conditionals involved in OT are implicitly specified via the joint samples, it is challenging to formulate this problem, especially when (i) the variable conditioned on is continuous and (ii) the marginal of this variable in the two distributions is different. We overcome these challenges by employing a specific kernel MMD (Maximum Mean Discrepancy) based regularizer that ensures the marginals of our conditional transport plan are close to the conditionals specified via the given joint samples. Under mild conditions, we prove that our estimator for this regularized transport cost is statistically consistent and derive finite-sample bounds on the estimation error. Application-specific details for parameterizing our conditional transport plan are also presented. Furthermore, we empirically evaluate our methodology on benchmark datasets in applications like classification, prompt learning for few-shot classification, and conditional-generation in the context of predicting cell responses to cancer treatment.
Improving Attribution Methods by Learning Submodular Functions
Apr 27, 2021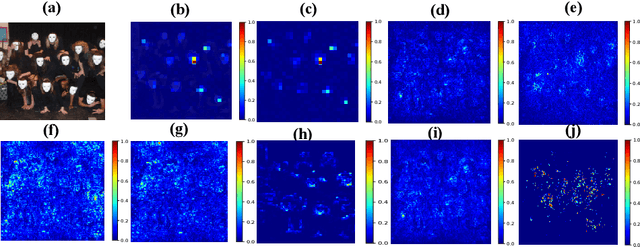
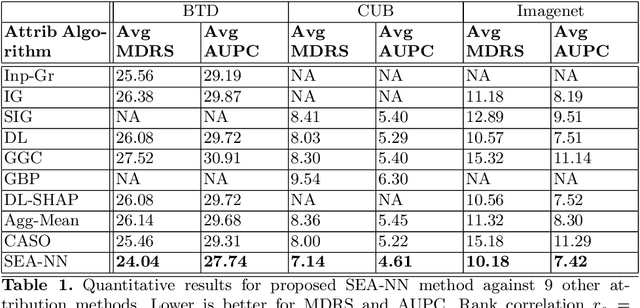
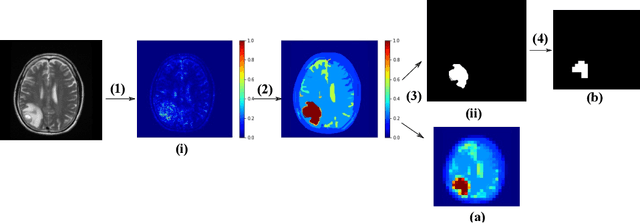
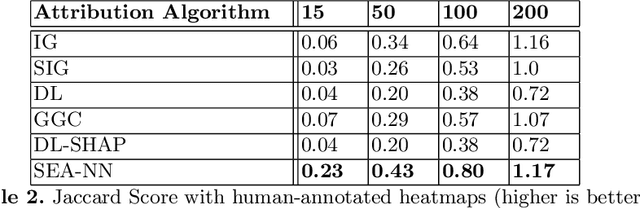
This work explores the novel idea of learning a submodular scoring function to improve the specificity/selectivity of existing feature attribution methods. Submodular scores are natural for attribution as they are known to accurately model the principle of diminishing returns. A new formulation for learning a deep submodular set function that is consistent with the real-valued attribution maps obtained by existing attribution methods is proposed. This formulation not only ensures that the scores for the heat maps that include the highly attributed features across the existing methods are high, but also that the score saturates even for the most specific heat map. The final attribution value of a feature is then defined as the marginal gain in the induced submodular score of the feature in the context of other highly attributed features, thus decreasing the attribution of redundant yet discriminatory features. Experiments on multiple datasets illustrate that the proposed attribution method achieves higher specificity while not degrading the discriminative power.
Neural Network Attributions: A Causal Perspective
Feb 07, 2019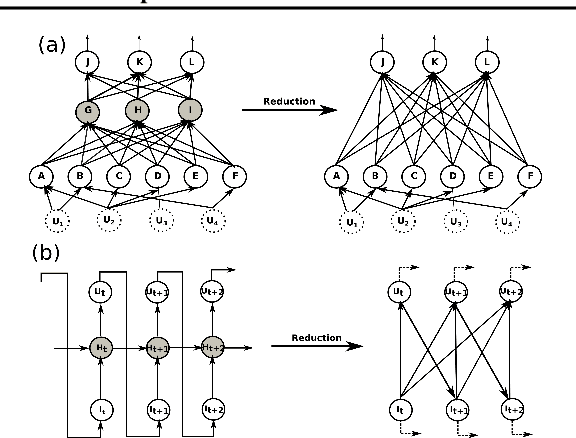
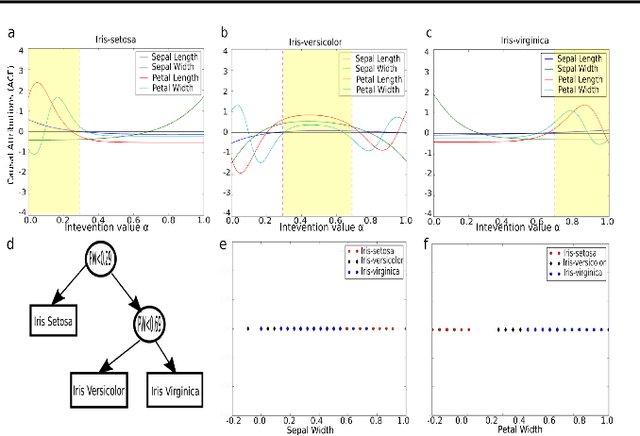
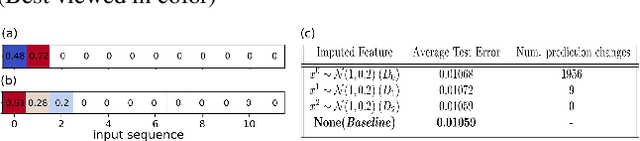
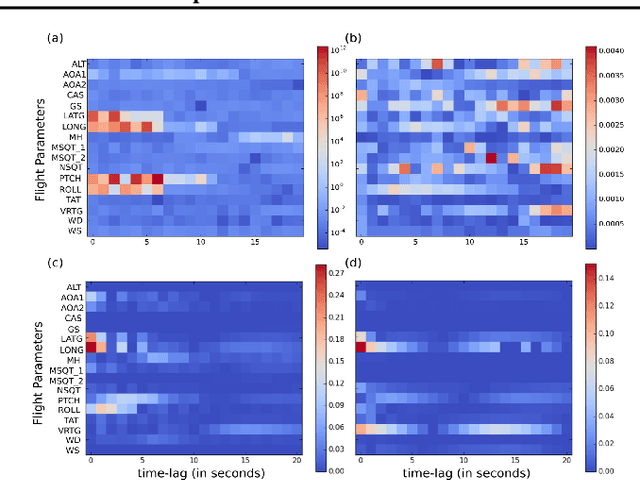
We propose a new attribution method for neural networks developed using first principles of causality (to the best of our knowledge, the first such). The neural network architecture is viewed as a Structural Causal Model, and a methodology to compute the causal effect of each feature on the output is presented. With reasonable assumptions on the causal structure of the input data, we propose algorithms to efficiently compute the causal effects, as well as scale the approach to data with large dimensionality. We also show how this method can be used for recurrent neural networks. We report experimental results on both simulated and real datasets showcasing the promise and usefulness of the proposed algorithm.