 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-R$^3$: On (In-)Consistency of Multi-modal Large Language Models (MLLMs)
Oct 07, 2024With the advent of Large Language Models (LLMs) and Multimodal (Visio-lingual) LLMs, a flurry of research has emerged, analyzing the performance of such models across a diverse array of tasks. While most studies focus on evaluating the capabilities of state-of-the-art (SoTA) MLLM models through task accuracy (e.g., Visual Question Answering, grounding) across various datasets, our work explores the related but complementary aspect of consistency - the ability of an MLLM model to produce semantically similar or identical responses to semantically similar queries. We note that consistency is a fundamental prerequisite (necessary but not sufficient condition) for robustness and trust in MLLMs. Humans, in particular, are known to be highly consistent (even if not always accurate) in their responses, and consistency is inherently expected from AI systems. Armed with this perspective, we propose the MM-R$^3$ benchmark, which analyses the performance in terms of consistency and accuracy in SoTA MLLMs with three tasks: Question Rephrasing, Image Restyling, and Context Reasoning. Our analysis reveals that consistency does not always align with accuracy, indicating that models with higher accuracy are not necessarily more consistent, and vice versa. Furthermore, we propose a simple yet effective mitigation strategy in the form of an adapter module trained to minimize inconsistency across prompts. With our proposed strategy, we are able to achieve absolute improvements of 5.7% and 12.5%, on average on widely used MLLMs such as BLIP-2 and LLaVa 1.5M in terms of consistency over their existing counterparts.
SceneGPT: A Language Model for 3D Scene Understanding
Aug 13, 2024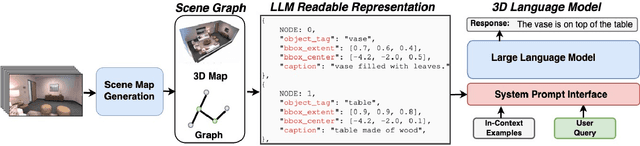
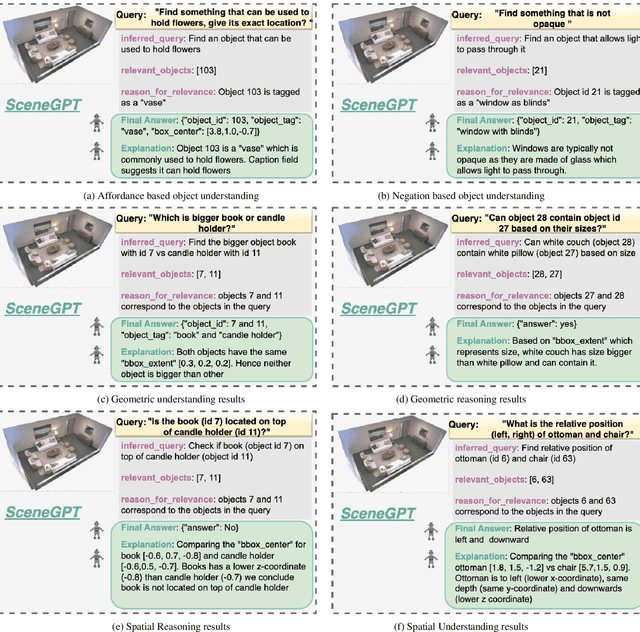
Building models that can understand and reason about 3D scenes is difficult owing to the lack of data sources for 3D supervised training and large-scale training regimes. In this work we ask - How can the knowledge in a pre-trained language model be leveraged for 3D scene understanding without any 3D pre-training. The aim of this work is to establish whether pre-trained LLMs possess priors/knowledge required for reasoning in 3D space and how can we prompt them such that they can be used for general purpose spatial reasoning and object understanding in 3D. To this end, we present SceneGPT, an LLM based scene understanding system which can perform 3D spatial reasoning without training or explicit 3D supervision. The key components of our framework are - 1) a 3D scene graph, that serves as scene representation, encoding the objects in the scene and their spatial relationships 2) a pre-trained LLM that can be adapted with in context learning for 3D spatial reasoning. We evaluate our framework qualitatively on object and scene understanding tasks including object semantics, physical properties and affordances (object-level) and spatial understanding (scene-level).
Response Wide Shut: Surprising Observations in Basic Vision Language Model Capabilities
Aug 13, 2024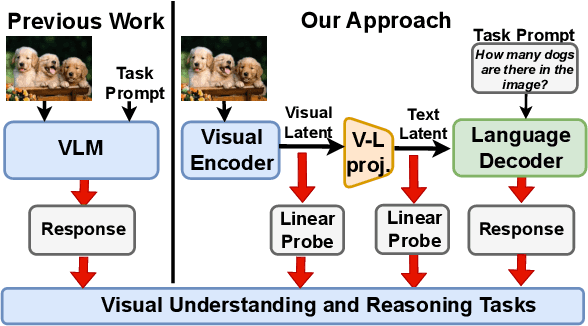



Vision-Language Models (VLMs) have emerged as general purpose tools for addressing a variety of complex computer vision problems. Such models have been shown to be highly capable, but, at the same time, also lacking some basic visual understanding skills. In this paper, we set out to understand the limitations of SoTA VLMs on fundamental visual tasks: object classification, understanding spatial arrangement, and ability to delineate individual object instances (through counting), by constructing a series of tests that probe which components of design, specifically, maybe lacking. Importantly, we go significantly beyond the current benchmarks, that simply measure final performance of VLM, by also comparing and contrasting it to performance of probes trained directly on features obtained from visual encoder (image embeddings), as well as intermediate vision-language projection used to bridge image-encoder and LLM-decoder ouput in many SoTA models (e.g., LLaVA, BLIP, InstructBLIP). In doing so, we uncover nascent shortcomings in VLMs response and make a number of important observations which could help train and develop more effective VLM models in future.
Do Vision-Language Foundational models show Robust Visual Perception?
Aug 13, 2024

Recent advances in vision-language foundational models have enabled development of systems that can perform visual understanding and reasoning tasks. However, it is unclear if these models are robust to distribution shifts, and how their performance and generalization capabilities vary under changes in data distribution. In this project we strive to answer the question "Are vision-language foundational models robust to distribution shifts like human perception?" Specifically, we consider a diverse range of vision-language models and compare how the performance of these systems is affected by corruption based distribution shifts (such as \textit{motion blur, fog, snow, gaussian noise}) commonly found in practical real-world scenarios. We analyse the generalization capabilities qualitatively and quantitatively on zero-shot image classification task under aforementioned distribution shifts. Our code will be avaible at \url{https://github.com/shivam-chandhok/CPSC-540-Project}
Talk2BEV: Language-enhanced Bird's-eye View Maps for Autonomous Driving
Oct 03, 2023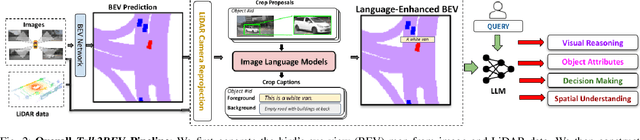
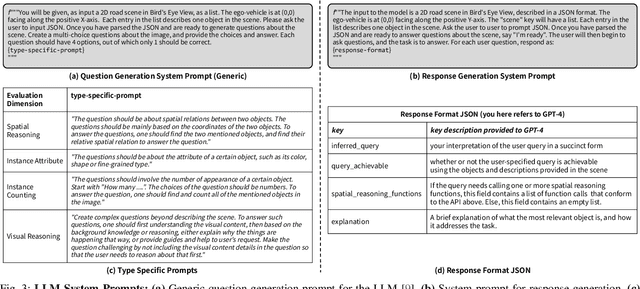

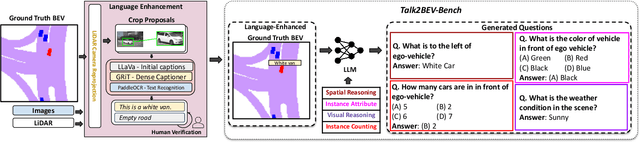
Talk2BEV is a large vision-language model (LVLM) interface for bird's-eye view (BEV) maps in autonomous driving contexts. While existing perception systems for autonomous driving scenarios have largely focused on a pre-defined (closed) set of object categories and driving scenarios, Talk2BEV blends recent advances in general-purpose language and vision models with BEV-structured map representations, eliminating the need for task-specific models. This enables a single system to cater to a variety of autonomous driving tasks encompassing visual and spatial reasoning, predicting the intents of traffic actors, and decision-making based on visual cues. We extensively evaluate Talk2BEV on a large number of scene understanding tasks that rely on both the ability to interpret free-form natural language queries, and in grounding these queries to the visual context embedded into the language-enhanced BEV map. To enable further research in LVLMs for autonomous driving scenarios, we develop and release Talk2BEV-Bench, a benchmark encompassing 1000 human-annotated BEV scenarios, with more than 20,000 questions and ground-truth responses from the NuScenes dataset.
Empirical Optimal Transport between Conditional Distributions
May 25, 2023Given samples from two joint distributions, we consider the problem of Optimal Transportation (OT) between the corresponding distributions conditioned on a common variable. The objective of this work is to estimate the associated transport cost (Wasserstein distance) as well as the transport plan between the conditionals as a function of the conditioned value. Since matching conditional distributions is at the core of supervised training of discriminative models and (implicit) conditional-generative models, OT between conditionals has the potential to be employed in diverse machine learning applications. However, since the conditionals involved in OT are implicitly specified via the joint samples, it is challenging to formulate this problem, especially when (i) the variable conditioned on is continuous and (ii) the marginal of this variable in the two distributions is different. We overcome these challenges by employing a specific kernel MMD (Maximum Mean Discrepancy) based regularizer that ensures the marginals of our conditional transport plan are close to the conditionals specified via the given joint samples. Under mild conditions, we prove that our estimator for this regularized transport cost is statistically consistent and derive finite-sample bounds on the estimation error. Application-specific details for parameterizing our conditional transport plan are also presented. Furthermore, we empirically evaluate our methodology on benchmark datasets in applications like classification, prompt learning for few-shot classification, and conditional-generation in the context of predicting cell responses to cancer treatment.
Hardware Software Co-design of Statistical and Deep Learning Frameworks for Wideband Sensing on Zynq System on Chip
Sep 06, 2022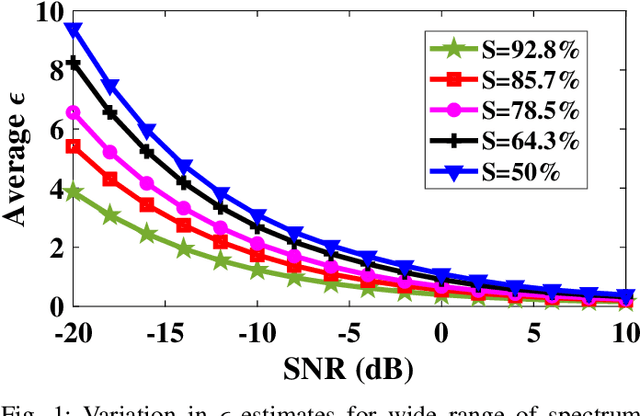
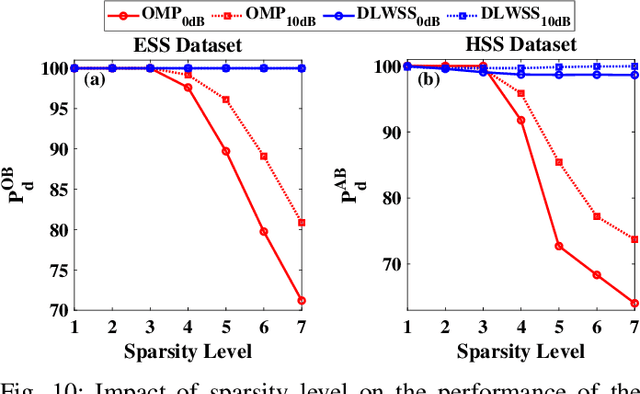
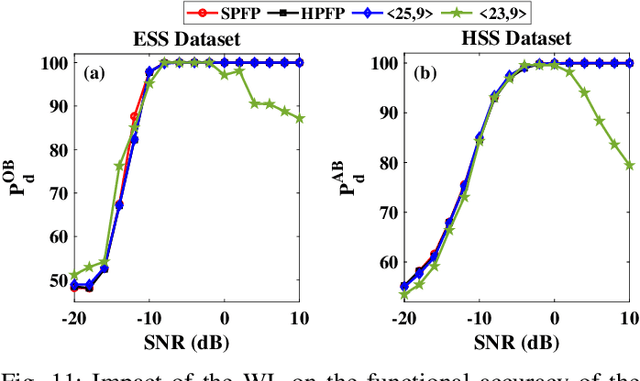
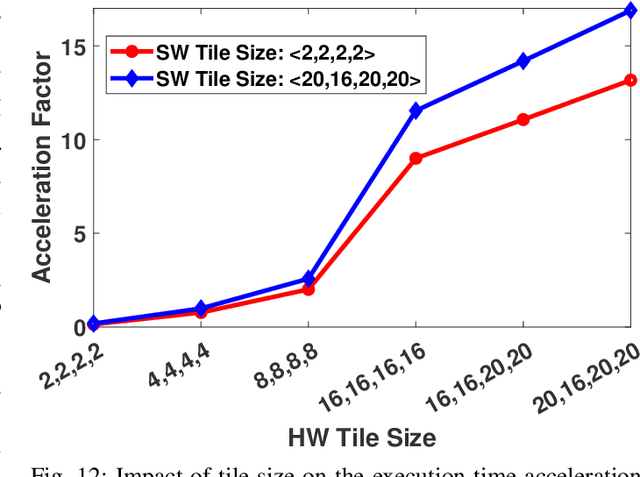
With the introduction of spectrum sharing and heterogeneous services in next-generation networks, the base stations need to sense the wideband spectrum and identify the spectrum resources to meet the quality-of-service, bandwidth, and latency constraints. Sub-Nyquist sampling (SNS) enables digitization for sparse wideband spectrum without needing Nyquist speed analog-to-digital converters. However, SNS demands additional signal processing algorithms for spectrum reconstruction, such as the well-known orthogonal matching pursuit (OMP) algorithm. OMP is also widely used in other compressed sensing applications. The first contribution of this work is efficiently mapping the OMP algorithm on the Zynq system-on-chip (ZSoC) consisting of an ARM processor and FPGA. Experimental analysis shows a significant degradation in OMP performance for sparse spectrum. Also, OMP needs prior knowledge of spectrum sparsity. We address these challenges via deep-learning-based architectures and efficiently map them on the ZSoC platform as second contribution. Via hardware-software co-design, different versions of the proposed architecture obtained by partitioning between software (ARM processor) and hardware (FPGA) are considered. The resource, power, and execution time comparisons for given memory constraints and a wide range of word lengths are presented for these architectures.
INDIGO: Intrinsic Multimodality for Domain Generalization
Jun 13, 2022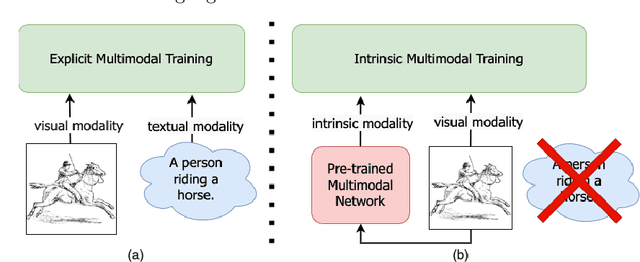
For models to generalize under unseen domains (a.k.a domain generalization), it is crucial to learn feature representations that are domain-agnostic and capture the underlying semantics that makes up an object category. Recent advances towards weakly supervised vision-language models that learn holistic representations from cheap weakly supervised noisy text annotations have shown their ability on semantic understanding by capturing object characteristics that generalize under different domains. However, when multiple source domains are involved, the cost of curating textual annotations for every image in the dataset can blow up several times, depending on their number. This makes the process tedious and infeasible, hindering us from directly using these supervised vision-language approaches to achieve the best generalization on an unseen domain. Motivated from this, we study how multimodal information from existing pre-trained multimodal networks can be leveraged in an "intrinsic" way to make systems generalize under unseen domains. To this end, we propose IntriNsic multimodality for DomaIn GeneralizatiOn (INDIGO), a simple and elegant way of leveraging the intrinsic modality present in these pre-trained multimodal networks along with the visual modality to enhance generalization to unseen domains at test-time. We experiment on several Domain Generalization settings (ClosedDG, OpenDG, and Limited sources) and show state-of-the-art generalization performance on unseen domains. Further, we provide a thorough analysis to develop a holistic understanding of INDIGO.
Unseen Classes at a Later Time? No Problem
Mar 30, 2022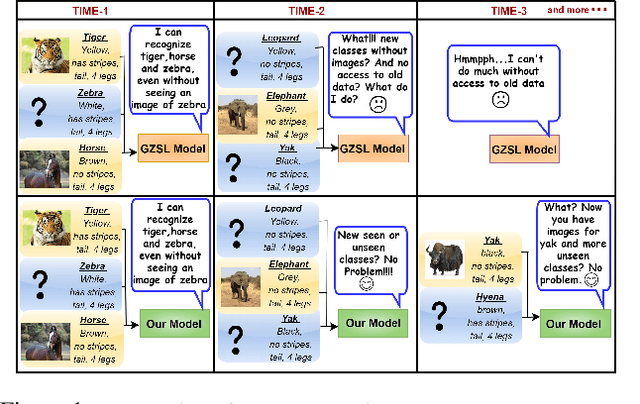
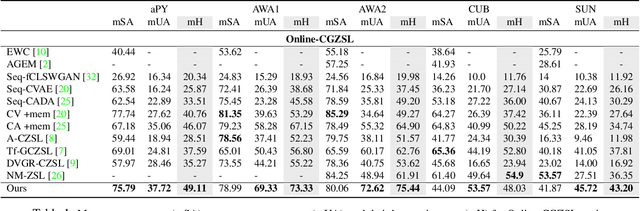
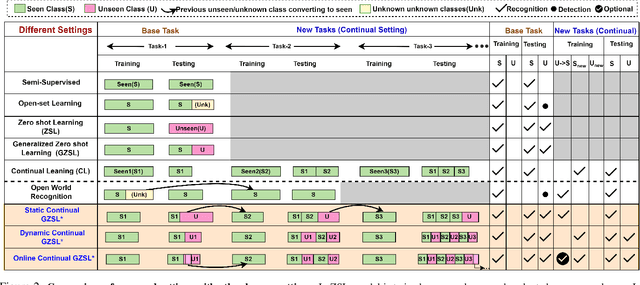
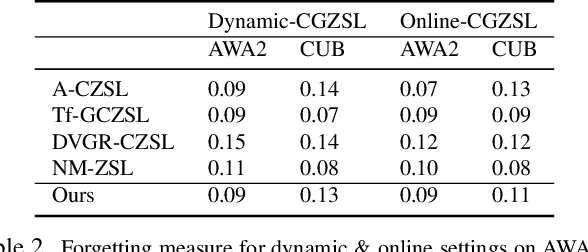
Recent progress towards learning from limited supervision has encouraged efforts towards designing models that can recognize novel classes at test time (generalized zero-shot learning or GZSL). GZSL approaches assume knowledge of all classes, with or without labeled data, beforehand. However, practical scenarios demand models that are adaptable and can handle dynamic addition of new seen and unseen classes on the fly (that is continual generalized zero-shot learning or CGZSL). One solution is to sequentially retrain and reuse conventional GZSL methods, however, such an approach suffers from catastrophic forgetting leading to suboptimal generalization performance. A few recent efforts towards tackling CGZSL have been limited by difference in settings, practicality, data splits and protocols followed-inhibiting fair comparison and a clear direction forward. Motivated from these observations, in this work, we firstly consolidate the different CGZSL setting variants and propose a new Online-CGZSL setting which is more practical and flexible. Secondly, we introduce a unified feature-generative framework for CGZSL that leverages bi-directional incremental alignment to dynamically adapt to addition of new classes, with or without labeled data, that arrive over time in any of these CGZSL settings. Our comprehensive experiments and analysis on five benchmark datasets and comparison with baselines show that our approach consistently outperforms existing methods, especially on the more practical Online setting.
Resource Constrained Neural Networks for 5G Direction-of-Arrival Estimation in Micro-controllers
Jul 23, 2021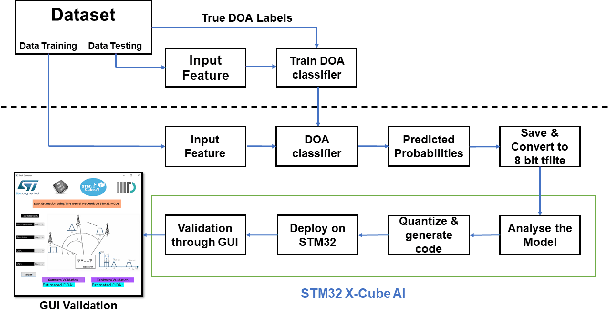
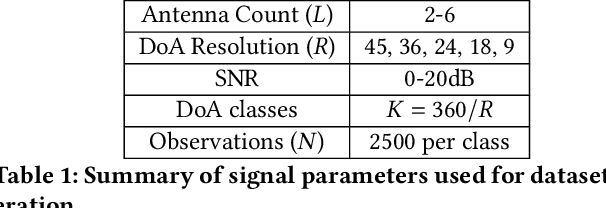
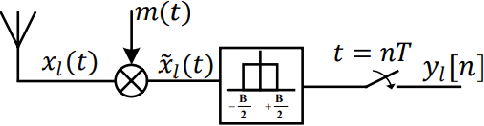
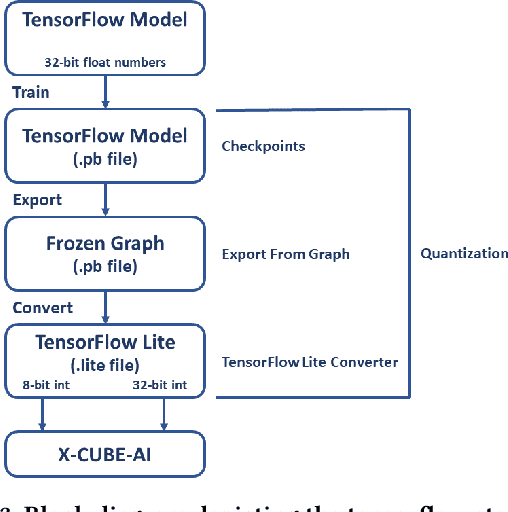
With the introduction of shared spectrum sensing and beam-forming based multi-antenna transceivers, 5G networks demand spectrum sensing to identify opportunities in time, frequency, and spatial domains. Narrow beam-forming makes it difficult to have spatial sensing (direction-of-arrival, DoA, estimation) in a centralized manner, and with the evolution of paradigms such as artificial intelligence of Things (AIOT), ultra-reliable low latency communication (URLLC) services and distributed networks, intelligence for edge devices (Edge-AI) is highly desirable. It helps to reduce the data-communication overhead compared to cloud-AI-centric networks and is more secure and free from scalability limitations. However, achieving desired functional accuracy is a challenge on edge devices such as microcontroller units (MCU) due to area, memory, and power constraints. In this work, we propose low complexity neural network-based algorithm for accurate DoA estimation and its efficient mapping on the off-the-self MCUs. An ad-hoc graphical-user interface (GUI) is developed to configure the STM32 NUCLEO-H743ZI2 MCU with the proposed algorithm and to validate its functionality. The performance of the proposed algorithm is analyzed for different signal-to-noise ratios (SNR), word-length, the number of antennas, and DoA resolution. In-depth experimental results show that it outperforms the conventional statistical spatial sensing approach.