 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnseen Classes at a Later Time? No Problem
Mar 30, 2022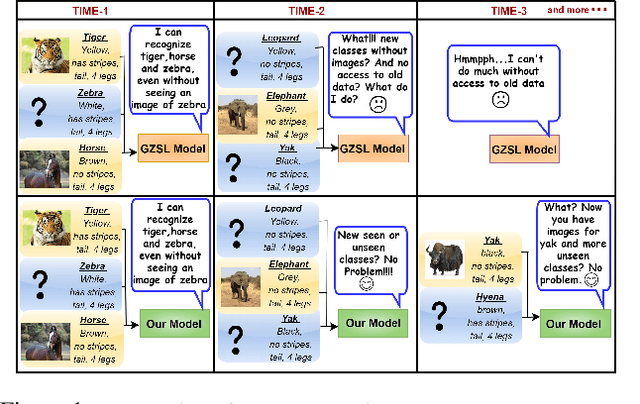
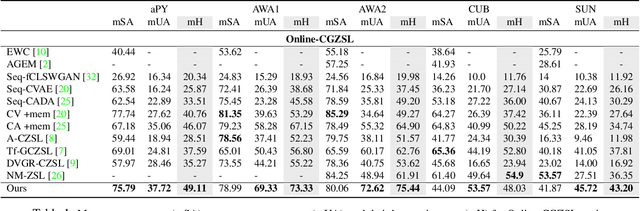
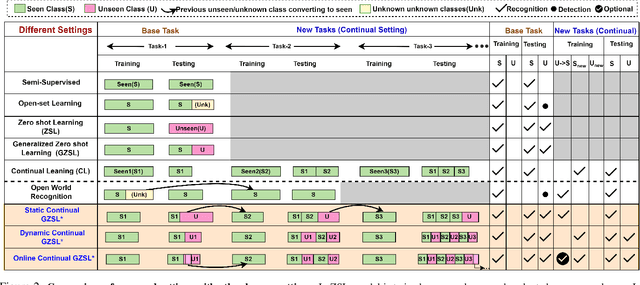
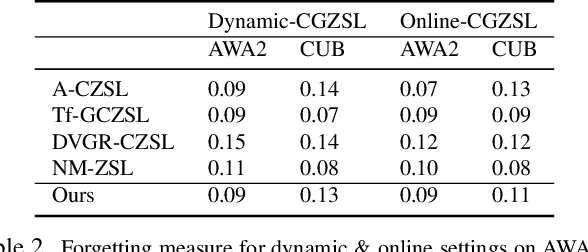
Recent progress towards learning from limited supervision has encouraged efforts towards designing models that can recognize novel classes at test time (generalized zero-shot learning or GZSL). GZSL approaches assume knowledge of all classes, with or without labeled data, beforehand. However, practical scenarios demand models that are adaptable and can handle dynamic addition of new seen and unseen classes on the fly (that is continual generalized zero-shot learning or CGZSL). One solution is to sequentially retrain and reuse conventional GZSL methods, however, such an approach suffers from catastrophic forgetting leading to suboptimal generalization performance. A few recent efforts towards tackling CGZSL have been limited by difference in settings, practicality, data splits and protocols followed-inhibiting fair comparison and a clear direction forward. Motivated from these observations, in this work, we firstly consolidate the different CGZSL setting variants and propose a new Online-CGZSL setting which is more practical and flexible. Secondly, we introduce a unified feature-generative framework for CGZSL that leverages bi-directional incremental alignment to dynamically adapt to addition of new classes, with or without labeled data, that arrive over time in any of these CGZSL settings. Our comprehensive experiments and analysis on five benchmark datasets and comparison with baselines show that our approach consistently outperforms existing methods, especially on the more practical Online setting.
Unsupervised Identification of Relevant Prior Cases
Jul 19, 2021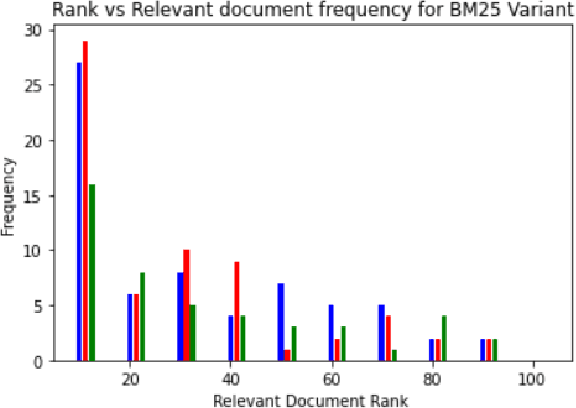
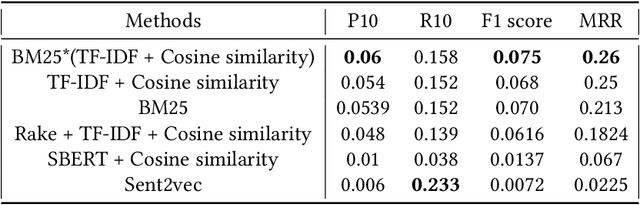
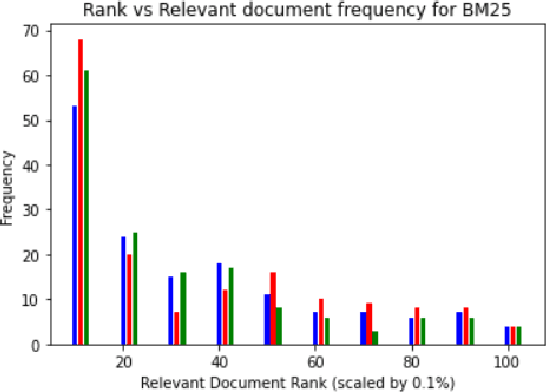

Document retrieval has taken its role in almost all domains of knowledge understanding, including the legal domain. Precedent refers to a court decision that is considered as authority for deciding subsequent cases involving identical or similar facts or similar legal issues. In this work, we propose different unsupervised approaches to solve the task of identifying relevant precedents to a given query case. Our proposed approaches are using word embeddings like word2vec, doc2vec, and sent2vec, finding cosine similarity using TF-IDF, retrieving relevant documents using BM25 scores, using the pre-trained model and SBERT to find the most similar document, and using the product of BM25 and TF-IDF scores to find the most relevant document for a given query. We compared all the methods based on precision@10, recall@10, and MRR. Based on the comparative analysis, we found that the TF-IDF score multiplied by the BM25 score gives the best result. In this paper, we have also presented the analysis that we did to improve the BM25 score.