 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalk2BEV: Language-enhanced Bird's-eye View Maps for Autonomous Driving
Oct 03, 2023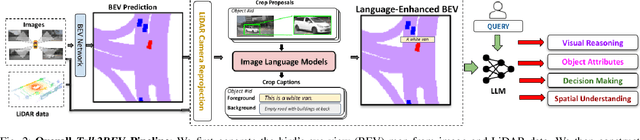
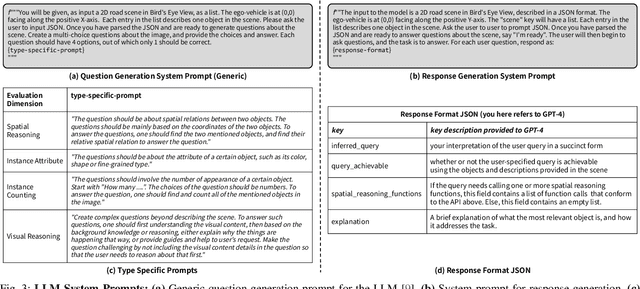

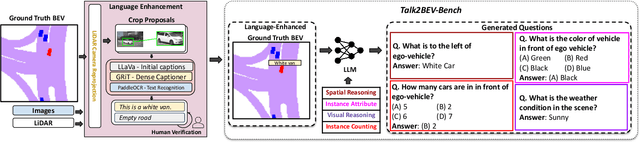
Talk2BEV is a large vision-language model (LVLM) interface for bird's-eye view (BEV) maps in autonomous driving contexts. While existing perception systems for autonomous driving scenarios have largely focused on a pre-defined (closed) set of object categories and driving scenarios, Talk2BEV blends recent advances in general-purpose language and vision models with BEV-structured map representations, eliminating the need for task-specific models. This enables a single system to cater to a variety of autonomous driving tasks encompassing visual and spatial reasoning, predicting the intents of traffic actors, and decision-making based on visual cues. We extensively evaluate Talk2BEV on a large number of scene understanding tasks that rely on both the ability to interpret free-form natural language queries, and in grounding these queries to the visual context embedded into the language-enhanced BEV map. To enable further research in LVLMs for autonomous driving scenarios, we develop and release Talk2BEV-Bench, a benchmark encompassing 1000 human-annotated BEV scenarios, with more than 20,000 questions and ground-truth responses from the NuScenes dataset.
UAP-BEV: Uncertainty Aware Planning using Bird's Eye View generated from Surround Monocular Images
Jun 08, 2023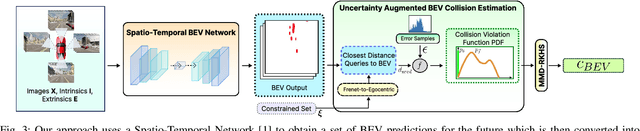

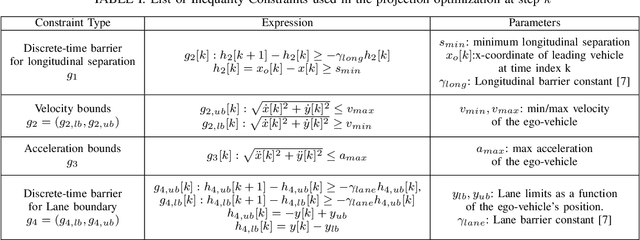
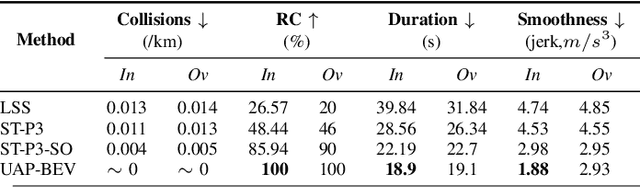
Autonomous driving requires accurate reasoning of the location of objects from raw sensor data. Recent end-to-end learning methods go from raw sensor data to a trajectory output via Bird's Eye View(BEV) segmentation as an interpretable intermediate representation. Motion planning over cost maps generated via Birds Eye View (BEV) segmentation has emerged as a prominent approach in autonomous driving. However, the current approaches have two critical gaps. First, the optimization process is simplistic and involves just evaluating a fixed set of trajectories over the cost map. The trajectory samples are not adapted based on their associated cost values. Second, the existing cost maps do not account for the uncertainty in the cost maps that can arise due to noise in RGB images, and BEV annotations. As a result, these approaches can struggle in challenging scenarios where there is abrupt cut-in, stopping, overtaking, merging, etc from the neighboring vehicles. In this paper, we propose UAP-BEV: A novel approach that models the noise in Spatio-Temporal BEV predictions to create an uncertainty-aware occupancy grid map. Using queries of the distance to the closest occupied cell, we obtain a sample estimate of the collision probability of the ego-vehicle. Subsequently, our approach uses gradient-free sampling-based optimization to compute low-cost trajectories over the cost map. Importantly, the sampling distribution is adapted based on the optimal cost values of the sampled trajectories. By explicitly modeling probabilistic collision avoidance in the BEV space, our approach is able to outperform the cost-map-based baselines in collision avoidance, route completion, time to completion, and smoothness. To further validate our method, we also show results on the real-world dataset NuScenes, where we report improvements in collision avoidance and smoothness.
Multi-Modal Model Predictive Control through Batch Non-Holonomic Trajectory Optimization: Application to Highway Driving
Sep 21, 2021



Standard Model Predictive Control (MPC) or trajectory optimization approaches perform only a local search to solve a complex non-convex optimization problem. As a result, they cannot capture the multi-modal characteristic of human driving. A global optimizer can be a potential solution but is computationally intractable in a real-time setting. In this paper, we present a real-time MPC capable of searching over different driving modalities. Our basic idea is simple: we run several goal-directed parallel trajectory optimizations and score the resulting trajectories based on user-defined meta cost functions. This allows us to perform a global search over several locally optimal motion plans. Although conceptually straightforward, realizing this idea in real-time with existing optimizers is highly challenging from technical and computational standpoints. With this motivation, we present a novel batch non-holonomic trajectory optimization whose underlying matrix algebra is easily parallelizable across problem instances and reduces to computing large batch matrix-vector products. This structure, in turn, is achieved by deriving a linearization-free multi-convex reformulation of the non-holonomic kinematics and collision avoidance constraints. We extensively validate our approach using both synthetic and real data sets (NGSIM) of traffic scenarios. We highlight how our algorithm automatically takes lane-change and overtaking decisions based on the defined meta cost function. Our batch optimizer achieves trajectories with lower meta cost, up to 6x faster than competing baselines.
Detection of AI-Synthesized Speech Using Cepstral & Bispectral Statistics
Sep 03, 2020
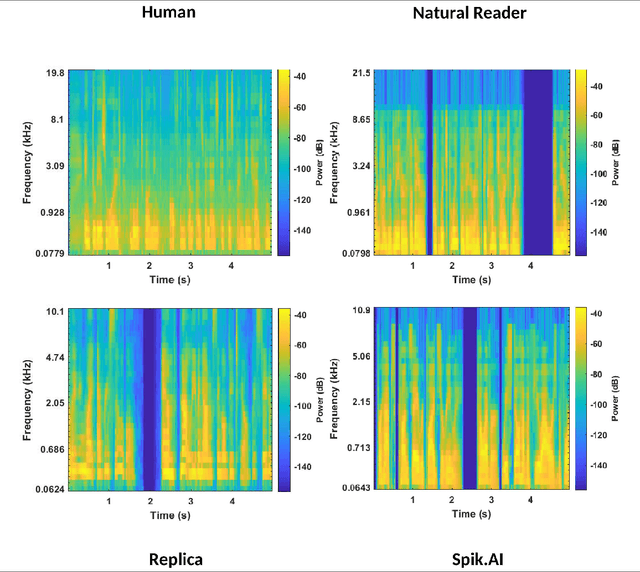

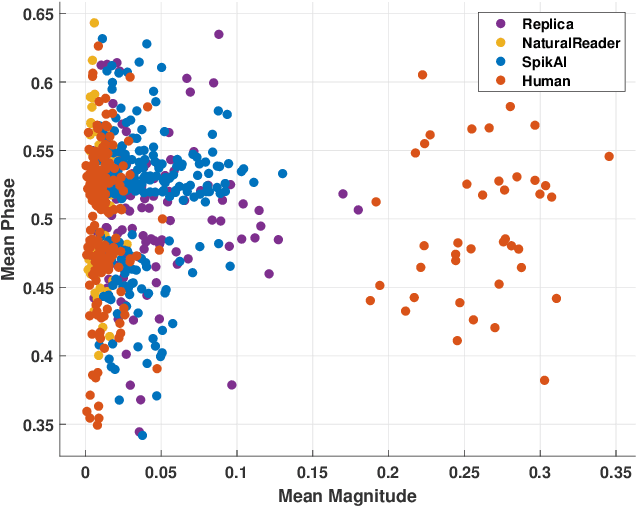
Digital technology has made possible unimaginable applications come true. It seems exciting to have a handful of tools for easy editing and manipulation, but it raises alarming concerns that can propagate as speech clones, duplicates, or maybe deep fakes. Validating the authenticity of a speech is one of the primary problems of digital audio forensics. We propose an approach to distinguish human speech from AI synthesized speech exploiting the Bi-spectral and Cepstral analysis. Higher-order statistics have less correlation for human speech in comparison to a synthesized speech. Also, Cepstral analysis revealed a durable power component in human speech that is missing for a synthesized speech. We integrate both these analyses and propose a machine learning model to detect AI synthesized speech.