 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalk2BEV: Language-enhanced Bird's-eye View Maps for Autonomous Driving
Paper and Code
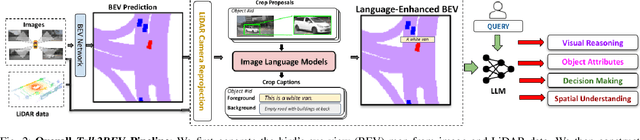
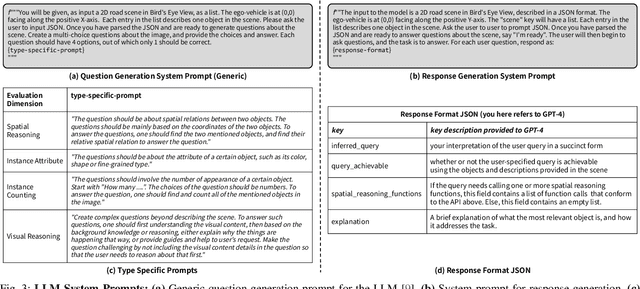

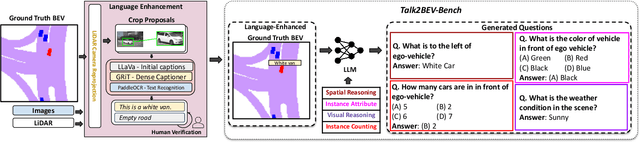
Talk2BEV is a large vision-language model (LVLM) interface for bird's-eye view (BEV) maps in autonomous driving contexts. While existing perception systems for autonomous driving scenarios have largely focused on a pre-defined (closed) set of object categories and driving scenarios, Talk2BEV blends recent advances in general-purpose language and vision models with BEV-structured map representations, eliminating the need for task-specific models. This enables a single system to cater to a variety of autonomous driving tasks encompassing visual and spatial reasoning, predicting the intents of traffic actors, and decision-making based on visual cues. We extensively evaluate Talk2BEV on a large number of scene understanding tasks that rely on both the ability to interpret free-form natural language queries, and in grounding these queries to the visual context embedded into the language-enhanced BEV map. To enable further research in LVLMs for autonomous driving scenarios, we develop and release Talk2BEV-Bench, a benchmark encompassing 1000 human-annotated BEV scenarios, with more than 20,000 questions and ground-truth responses from the NuScenes dataset.