 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Every Token Counts: Optimal Segmentation for Low-Resource Language Models
Dec 09, 2024Traditional greedy tokenization methods have been a critical step in Natural Language Processing (NLP), influencing how text is converted into tokens and directly impacting model performance. While subword tokenizers like Byte-Pair Encoding (BPE) are widely used, questions remain about their optimality across model scales and languages. In this work, we demonstrate through extensive experiments that an optimal BPE configuration significantly reduces token count compared to greedy segmentation, yielding improvements in token-saving percentages and performance benefits, particularly for smaller models. We evaluate tokenization performance across various intrinsic and extrinsic tasks, including generation and classification. Our findings suggest that compression-optimized tokenization strategies could provide substantial advantages for multilingual and low-resource language applications, highlighting a promising direction for further research and inclusive NLP.
Talk2BEV: Language-enhanced Bird's-eye View Maps for Autonomous Driving
Oct 03, 2023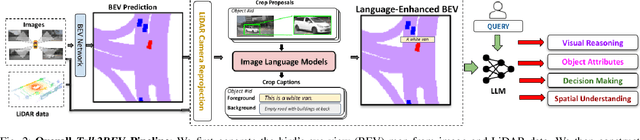
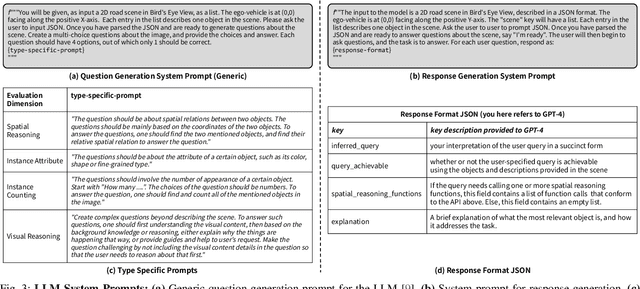

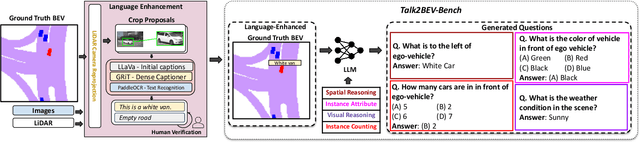
Talk2BEV is a large vision-language model (LVLM) interface for bird's-eye view (BEV) maps in autonomous driving contexts. While existing perception systems for autonomous driving scenarios have largely focused on a pre-defined (closed) set of object categories and driving scenarios, Talk2BEV blends recent advances in general-purpose language and vision models with BEV-structured map representations, eliminating the need for task-specific models. This enables a single system to cater to a variety of autonomous driving tasks encompassing visual and spatial reasoning, predicting the intents of traffic actors, and decision-making based on visual cues. We extensively evaluate Talk2BEV on a large number of scene understanding tasks that rely on both the ability to interpret free-form natural language queries, and in grounding these queries to the visual context embedded into the language-enhanced BEV map. To enable further research in LVLMs for autonomous driving scenarios, we develop and release Talk2BEV-Bench, a benchmark encompassing 1000 human-annotated BEV scenarios, with more than 20,000 questions and ground-truth responses from the NuScenes dataset.
UAP-BEV: Uncertainty Aware Planning using Bird's Eye View generated from Surround Monocular Images
Jun 08, 2023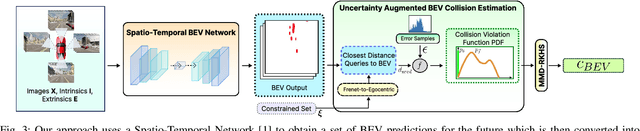

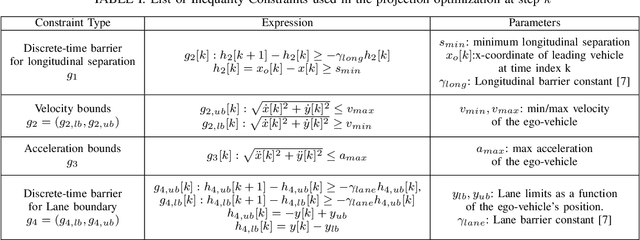
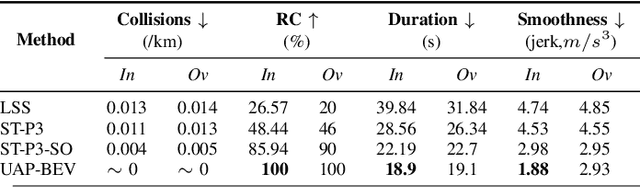
Autonomous driving requires accurate reasoning of the location of objects from raw sensor data. Recent end-to-end learning methods go from raw sensor data to a trajectory output via Bird's Eye View(BEV) segmentation as an interpretable intermediate representation. Motion planning over cost maps generated via Birds Eye View (BEV) segmentation has emerged as a prominent approach in autonomous driving. However, the current approaches have two critical gaps. First, the optimization process is simplistic and involves just evaluating a fixed set of trajectories over the cost map. The trajectory samples are not adapted based on their associated cost values. Second, the existing cost maps do not account for the uncertainty in the cost maps that can arise due to noise in RGB images, and BEV annotations. As a result, these approaches can struggle in challenging scenarios where there is abrupt cut-in, stopping, overtaking, merging, etc from the neighboring vehicles. In this paper, we propose UAP-BEV: A novel approach that models the noise in Spatio-Temporal BEV predictions to create an uncertainty-aware occupancy grid map. Using queries of the distance to the closest occupied cell, we obtain a sample estimate of the collision probability of the ego-vehicle. Subsequently, our approach uses gradient-free sampling-based optimization to compute low-cost trajectories over the cost map. Importantly, the sampling distribution is adapted based on the optimal cost values of the sampled trajectories. By explicitly modeling probabilistic collision avoidance in the BEV space, our approach is able to outperform the cost-map-based baselines in collision avoidance, route completion, time to completion, and smoothness. To further validate our method, we also show results on the real-world dataset NuScenes, where we report improvements in collision avoidance and smoothness.