 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUAP-BEV: Uncertainty Aware Planning using Bird's Eye View generated from Surround Monocular Images
Jun 08, 2023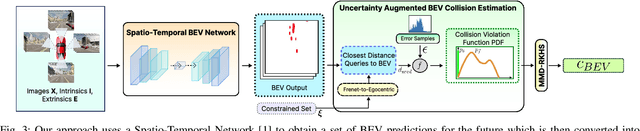

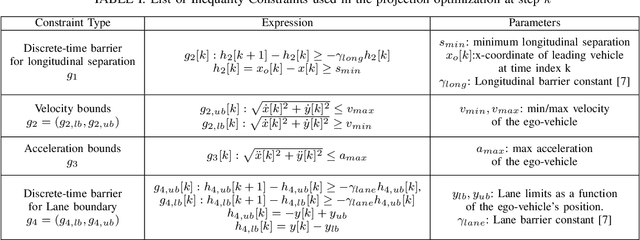
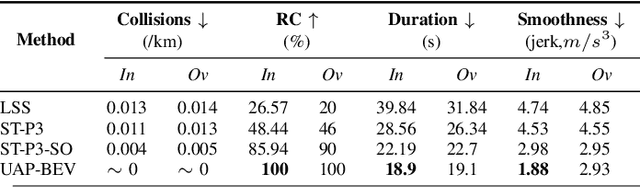
Autonomous driving requires accurate reasoning of the location of objects from raw sensor data. Recent end-to-end learning methods go from raw sensor data to a trajectory output via Bird's Eye View(BEV) segmentation as an interpretable intermediate representation. Motion planning over cost maps generated via Birds Eye View (BEV) segmentation has emerged as a prominent approach in autonomous driving. However, the current approaches have two critical gaps. First, the optimization process is simplistic and involves just evaluating a fixed set of trajectories over the cost map. The trajectory samples are not adapted based on their associated cost values. Second, the existing cost maps do not account for the uncertainty in the cost maps that can arise due to noise in RGB images, and BEV annotations. As a result, these approaches can struggle in challenging scenarios where there is abrupt cut-in, stopping, overtaking, merging, etc from the neighboring vehicles. In this paper, we propose UAP-BEV: A novel approach that models the noise in Spatio-Temporal BEV predictions to create an uncertainty-aware occupancy grid map. Using queries of the distance to the closest occupied cell, we obtain a sample estimate of the collision probability of the ego-vehicle. Subsequently, our approach uses gradient-free sampling-based optimization to compute low-cost trajectories over the cost map. Importantly, the sampling distribution is adapted based on the optimal cost values of the sampled trajectories. By explicitly modeling probabilistic collision avoidance in the BEV space, our approach is able to outperform the cost-map-based baselines in collision avoidance, route completion, time to completion, and smoothness. To further validate our method, we also show results on the real-world dataset NuScenes, where we report improvements in collision avoidance and smoothness.
CAFIN: Centrality Aware Fairness inducing IN-processing for Unsupervised Representation Learning on Graphs
Apr 10, 2023Unsupervised representation learning on (large) graphs has received significant attention in the research community due to the compactness and richness of the learned embeddings and the abundance of unlabelled graph data. When deployed, these node representations must be generated with appropriate fairness constraints to minimize bias induced by them on downstream tasks. Consequently, group and individual fairness notions for graph learning algorithms have been investigated for specific downstream tasks. One major limitation of these fairness notions is that they do not consider the connectivity patterns in the graph leading to varied node influence (or centrality power). In this paper, we design a centrality-aware fairness framework for inductive graph representation learning algorithms. We propose CAFIN (Centrality Aware Fairness inducing IN-processing), an in-processing technique that leverages graph structure to improve GraphSAGE's representations - a popular framework in the unsupervised inductive setting. We demonstrate the efficacy of CAFIN in the inductive setting on two popular downstream tasks - Link prediction and Node Classification. Empirically, they consistently minimize the disparity in fairness between groups across datasets (varying from 18 to 80% reduction in imparity, a measure of group fairness) from different domains while incurring only a minimal performance cost.
GDIP: Gated Differentiable Image Processing for Object-Detection in Adverse Conditions
Sep 29, 2022
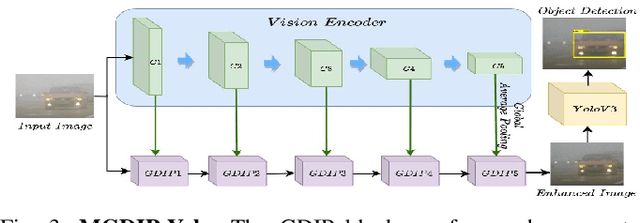
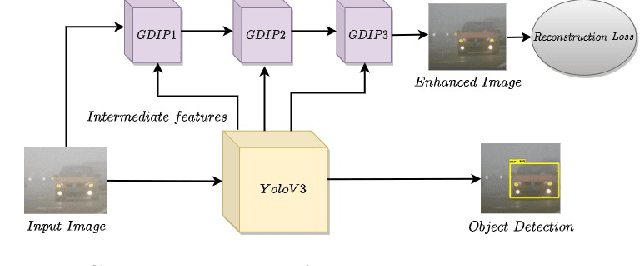
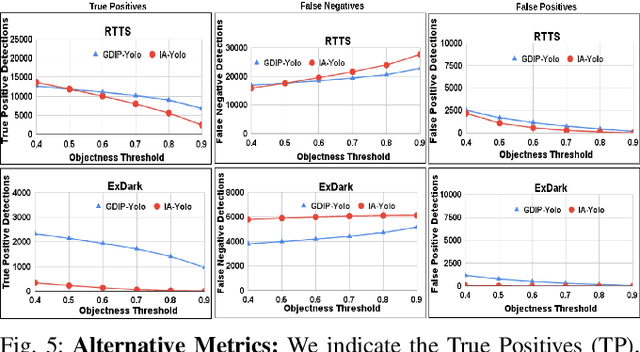
Detecting objects under adverse weather and lighting conditions is crucial for the safe and continuous operation of an autonomous vehicle, and remains an unsolved problem. We present a Gated Differentiable Image Processing (GDIP) block, a domain-agnostic network architecture, which can be plugged into existing object detection networks (e.g., Yolo) and trained end-to-end with adverse condition images such as those captured under fog and low lighting. Our proposed GDIP block learns to enhance images directly through the downstream object detection loss. This is achieved by learning parameters of multiple image pre-processing (IP) techniques that operate concurrently, with their outputs combined using weights learned through a novel gating mechanism. We further improve GDIP through a multi-stage guidance procedure for progressive image enhancement. Finally, trading off accuracy for speed, we propose a variant of GDIP that can be used as a regularizer for training Yolo, which eliminates the need for GDIP-based image enhancement during inference, resulting in higher throughput and plausible real-world deployment. We demonstrate significant improvement in detection performance over several state-of-the-art methods through quantitative and qualitative studies on synthetic datasets such as PascalVOC, and real-world foggy (RTTS) and low-lighting (ExDark) datasets.