 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneEdited: A City-Scale Benchmark for 3D HD Map Updating via Image-Guided Change Detection
Nov 19, 2025



Accurate, up-to-date High-Definition (HD) maps are critical for urban planning, infrastructure monitoring, and autonomous navigation. However, these maps quickly become outdated as environments evolve, creating a need for robust methods that not only detect changes but also incorporate them into updated 3D representations. While change detection techniques have advanced significantly, there remains a clear gap between detecting changes and actually updating 3D maps, particularly when relying on 2D image-based change detection. To address this gap, we introduce SceneEdited, the first city-scale dataset explicitly designed to support research on HD map maintenance through 3D point cloud updating. SceneEdited contains over 800 up-to-date scenes covering 73 km of driving and approximate 3 $\text{km}^2$ of urban area, with more than 23,000 synthesized object changes created both manually and automatically across 2000+ out-of-date versions, simulating realistic urban modifications such as missing roadside infrastructure, buildings, overpasses, and utility poles. Each scene includes calibrated RGB images, LiDAR scans, and detailed change masks for training and evaluation. We also provide baseline methods using a foundational image-based structure-from-motion pipeline for updating outdated scenes, as well as a comprehensive toolkit supporting scalability, trackability, and portability for future dataset expansion and unification of out-of-date object annotations. Both the dataset and the toolkit are publicly available at https://github.com/ChadLin9596/ScenePoint-ETK, establising a standardized benchmark for 3D map updating research.
SegMASt3R: Geometry Grounded Segment Matching
Oct 06, 2025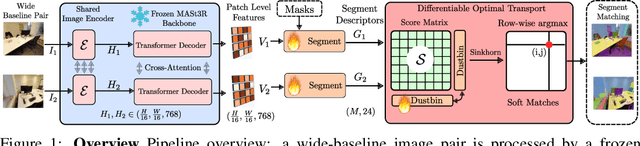
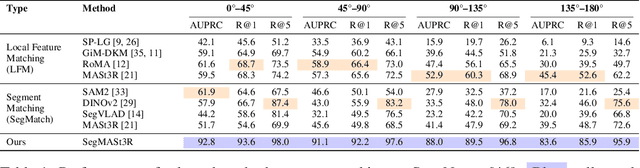


Segment matching is an important intermediate task in computer vision that establishes correspondences between semantically or geometrically coherent regions across images. Unlike keypoint matching, which focuses on localized features, segment matching captures structured regions, offering greater robustness to occlusions, lighting variations, and viewpoint changes. In this paper, we leverage the spatial understanding of 3D foundation models to tackle wide-baseline segment matching, a challenging setting involving extreme viewpoint shifts. We propose an architecture that uses the inductive bias of these 3D foundation models to match segments across image pairs with up to 180 degree view-point change. Extensive experiments show that our approach outperforms state-of-the-art methods, including the SAM2 video propagator and local feature matching methods, by upto 30% on the AUPRC metric, on ScanNet++ and Replica datasets. We further demonstrate benefits of the proposed model on relevant downstream tasks, including 3D instance segmentation and image-goal navigation. Project Page: https://segmast3r.github.io/
ObjectReact: Learning Object-Relative Control for Visual Navigation
Sep 11, 2025Visual navigation using only a single camera and a topological map has recently become an appealing alternative to methods that require additional sensors and 3D maps. This is typically achieved through an "image-relative" approach to estimating control from a given pair of current observation and subgoal image. However, image-level representations of the world have limitations because images are strictly tied to the agent's pose and embodiment. In contrast, objects, being a property of the map, offer an embodiment- and trajectory-invariant world representation. In this work, we present a new paradigm of learning "object-relative" control that exhibits several desirable characteristics: a) new routes can be traversed without strictly requiring to imitate prior experience, b) the control prediction problem can be decoupled from solving the image matching problem, and c) high invariance can be achieved in cross-embodiment deployment for variations across both training-testing and mapping-execution settings. We propose a topometric map representation in the form of a "relative" 3D scene graph, which is used to obtain more informative object-level global path planning costs. We train a local controller, dubbed "ObjectReact", conditioned directly on a high-level "WayObject Costmap" representation that eliminates the need for an explicit RGB input. We demonstrate the advantages of learning object-relative control over its image-relative counterpart across sensor height variations and multiple navigation tasks that challenge the underlying spatial understanding capability, e.g., navigating a map trajectory in the reverse direction. We further show that our sim-only policy is able to generalize well to real-world indoor environments. Code and supplementary material are accessible via project page: https://object-react.github.io/
TANGO: Traversability-Aware Navigation with Local Metric Control for Topological Goals
Sep 10, 2025Visual navigation in robotics traditionally relies on globally-consistent 3D maps or learned controllers, which can be computationally expensive and difficult to generalize across diverse environments. In this work, we present a novel RGB-only, object-level topometric navigation pipeline that enables zero-shot, long-horizon robot navigation without requiring 3D maps or pre-trained controllers. Our approach integrates global topological path planning with local metric trajectory control, allowing the robot to navigate towards object-level sub-goals while avoiding obstacles. We address key limitations of previous methods by continuously predicting local trajectory using monocular depth and traversability estimation, and incorporating an auto-switching mechanism that falls back to a baseline controller when necessary. The system operates using foundational models, ensuring open-set applicability without the need for domain-specific fine-tuning. We demonstrate the effectiveness of our method in both simulated environments and real-world tests, highlighting its robustness and deployability. Our approach outperforms existing state-of-the-art methods, offering a more adaptable and effective solution for visual navigation in open-set environments. The source code is made publicly available: https://github.com/podgorki/TANGO.
Affordance-Centric Policy Learning: Sample Efficient and Generalisable Robot Policy Learning using Affordance-Centric Task Frames
Oct 15, 2024



Affordances are central to robotic manipulation, where most tasks can be simplified to interactions with task-specific regions on objects. By focusing on these key regions, we can abstract away task-irrelevant information, simplifying the learning process, and enhancing generalisation. In this paper, we propose an affordance-centric policy-learning approach that centres and appropriately \textit{orients} a \textit{task frame} on these affordance regions allowing us to achieve both \textbf{intra-category invariance} -- where policies can generalise across different instances within the same object category -- and \textbf{spatial invariance} -- which enables consistent performance regardless of object placement in the environment. We propose a method to leverage existing generalist large vision models to extract and track these affordance frames, and demonstrate that our approach can learn manipulation tasks using behaviour cloning from as little as 10 demonstrations, with equivalent generalisation to an image-based policy trained on 305 demonstrations. We provide video demonstrations on our project site: https://affordance-policy.github.io.
VLAD-BuFF: Burst-aware Fast Feature Aggregation for Visual Place Recognition
Sep 28, 2024Visual Place Recognition (VPR) is a crucial component of many visual localization pipelines for embodied agents. VPR is often formulated as an image retrieval task aimed at jointly learning local features and an aggregation method. The current state-of-the-art VPR methods rely on VLAD aggregation, which can be trained to learn a weighted contribution of features through their soft assignment to cluster centers. However, this process has two key limitations. Firstly, the feature-to-cluster weighting does not account for over-represented repetitive structures within a cluster, e.g., shadows or window panes; this phenomenon is also referred to as the `burstiness' problem, classically solved by discounting repetitive features before aggregation. Secondly, feature to cluster comparisons are compute-intensive for state-of-the-art image encoders with high-dimensional local features. This paper addresses these limitations by introducing VLAD-BuFF with two novel contributions: i) a self-similarity based feature discounting mechanism to learn Burst-aware features within end-to-end VPR training, and ii) Fast Feature aggregation by reducing local feature dimensions specifically through PCA-initialized learnable pre-projection. We benchmark our method on 9 public datasets, where VLAD-BuFF sets a new state of the art. Our method is able to maintain its high recall even for 12x reduced local feature dimensions, thus enabling fast feature aggregation without compromising on recall. Through additional qualitative studies, we show how our proposed weighting method effectively downweights the non-distinctive features. Source code: https://github.com/Ahmedest61/VLAD-BuFF/.
Revisit Anything: Visual Place Recognition via Image Segment Retrieval
Sep 26, 2024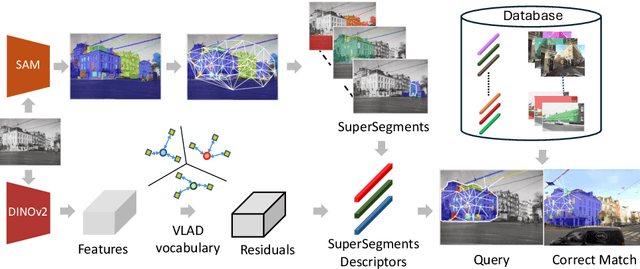
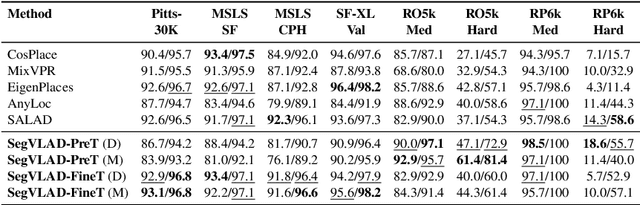

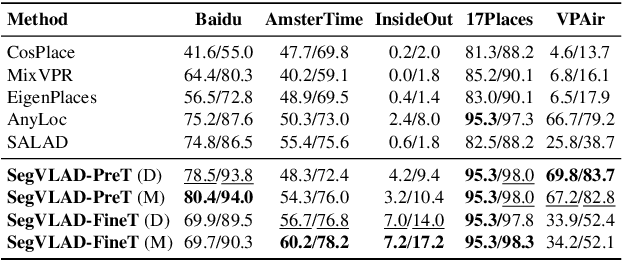
Accurately recognizing a revisited place is crucial for embodied agents to localize and navigate. This requires visual representations to be distinct, despite strong variations in camera viewpoint and scene appearance. Existing visual place recognition pipelines encode the "whole" image and search for matches. This poses a fundamental challenge in matching two images of the same place captured from different camera viewpoints: "the similarity of what overlaps can be dominated by the dissimilarity of what does not overlap". We address this by encoding and searching for "image segments" instead of the whole images. We propose to use open-set image segmentation to decompose an image into `meaningful' entities (i.e., things and stuff). This enables us to create a novel image representation as a collection of multiple overlapping subgraphs connecting a segment with its neighboring segments, dubbed SuperSegment. Furthermore, to efficiently encode these SuperSegments into compact vector representations, we propose a novel factorized representation of feature aggregation. We show that retrieving these partial representations leads to significantly higher recognition recall than the typical whole image based retrieval. Our segments-based approach, dubbed SegVLAD, sets a new state-of-the-art in place recognition on a diverse selection of benchmark datasets, while being applicable to both generic and task-specialized image encoders. Finally, we demonstrate the potential of our method to ``revisit anything'' by evaluating our method on an object instance retrieval task, which bridges the two disparate areas of research: visual place recognition and object-goal navigation, through their common aim of recognizing goal objects specific to a place. Source code: https://github.com/AnyLoc/Revisit-Anything.
Robust Scene Change Detection Using Visual Foundation Models and Cross-Attention Mechanisms
Sep 25, 2024



We present a novel method for scene change detection that leverages the robust feature extraction capabilities of a visual foundational model, DINOv2, and integrates full-image cross-attention to address key challenges such as varying lighting, seasonal variations, and viewpoint differences. In order to effectively learn correspondences and mis-correspondences between an image pair for the change detection task, we propose to a) ``freeze'' the backbone in order to retain the generality of dense foundation features, and b) employ ``full-image'' cross-attention to better tackle the viewpoint variations between the image pair. We evaluate our approach on two benchmark datasets, VL-CMU-CD and PSCD, along with their viewpoint-varied versions. Our experiments demonstrate significant improvements in F1-score, particularly in scenarios involving geometric changes between image pairs. The results indicate our method's superior generalization capabilities over existing state-of-the-art approaches, showing robustness against photometric and geometric variations as well as better overall generalization when fine-tuned to adapt to new environments. Detailed ablation studies further validate the contributions of each component in our architecture. Source code will be made publicly available upon acceptance.
RoboHop: Segment-based Topological Map Representation for Open-World Visual Navigation
May 09, 2024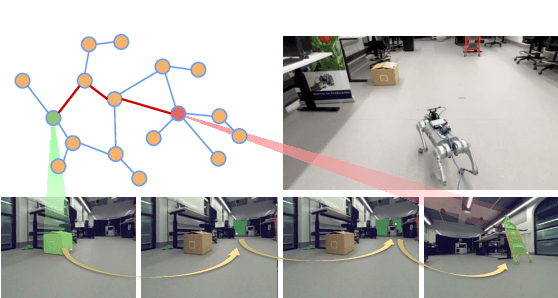
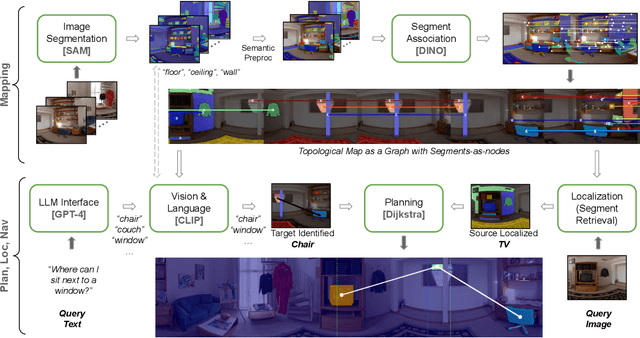
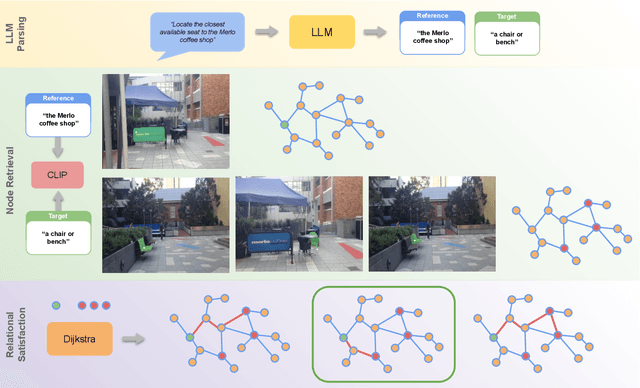

Mapping is crucial for spatial reasoning, planning and robot navigation. Existing approaches range from metric, which require precise geometry-based optimization, to purely topological, where image-as-node based graphs lack explicit object-level reasoning and interconnectivity. In this paper, we propose a novel topological representation of an environment based on "image segments", which are semantically meaningful and open-vocabulary queryable, conferring several advantages over previous works based on pixel-level features. Unlike 3D scene graphs, we create a purely topological graph with segments as nodes, where edges are formed by a) associating segment-level descriptors between pairs of consecutive images and b) connecting neighboring segments within an image using their pixel centroids. This unveils a "continuous sense of a place", defined by inter-image persistence of segments along with their intra-image neighbours. It further enables us to represent and update segment-level descriptors through neighborhood aggregation using graph convolution layers, which improves robot localization based on segment-level retrieval. Using real-world data, we show how our proposed map representation can be used to i) generate navigation plans in the form of "hops over segments" and ii) search for target objects using natural language queries describing spatial relations of objects. Furthermore, we quantitatively analyze data association at the segment level, which underpins inter-image connectivity during mapping and segment-level localization when revisiting the same place. Finally, we show preliminary trials on segment-level `hopping' based zero-shot real-world navigation. Project page with supplementary details: oravus.github.io/RoboHop/
QueSTMaps: Queryable Semantic Topological Maps for 3D Scene Understanding
Apr 09, 2024Understanding the structural organisation of 3D indoor scenes in terms of rooms is often accomplished via floorplan extraction. Robotic tasks such as planning and navigation require a semantic understanding of the scene as well. This is typically achieved via object-level semantic segmentation. However, such methods struggle to segment out topological regions like "kitchen" in the scene. In this work, we introduce a two-step pipeline. First, we extract a topological map, i.e., floorplan of the indoor scene using a novel multi-channel occupancy representation. Then, we generate CLIP-aligned features and semantic labels for every room instance based on the objects it contains using a self-attention transformer. Our language-topology alignment supports natural language querying, e.g., a "place to cook" locates the "kitchen". We outperform the current state-of-the-art on room segmentation by ~20% and room classification by ~12%. Our detailed qualitative analysis and ablation studies provide insights into the problem of joint structural and semantic 3D scene understanding.