 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Skill Discovery as Exploration for Learning Agile Locomotion
Aug 12, 2025Exploration is crucial for enabling legged robots to learn agile locomotion behaviors that can overcome diverse obstacles. However, such exploration is inherently challenging, and we often rely on extensive reward engineering, expert demonstrations, or curriculum learning - all of which limit generalizability. In this work, we propose Skill Discovery as Exploration (SDAX), a novel learning framework that significantly reduces human engineering effort. SDAX leverages unsupervised skill discovery to autonomously acquire a diverse repertoire of skills for overcoming obstacles. To dynamically regulate the level of exploration during training, SDAX employs a bi-level optimization process that autonomously adjusts the degree of exploration. We demonstrate that SDAX enables quadrupedal robots to acquire highly agile behaviors including crawling, climbing, leaping, and executing complex maneuvers such as jumping off vertical walls. Finally, we deploy the learned policy on real hardware, validating its successful transfer to the real world.
Revisit Anything: Visual Place Recognition via Image Segment Retrieval
Sep 26, 2024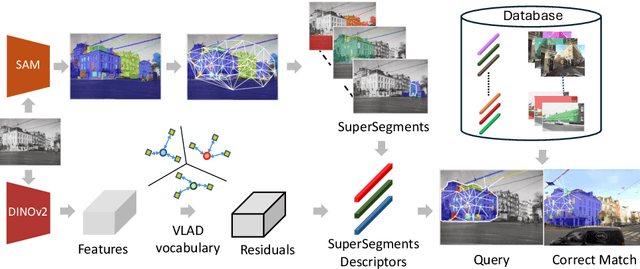
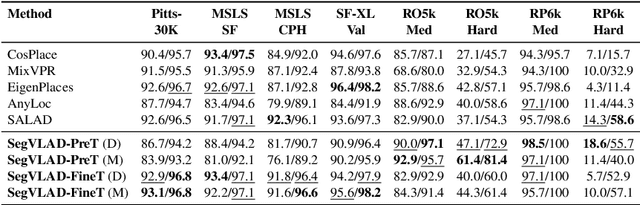

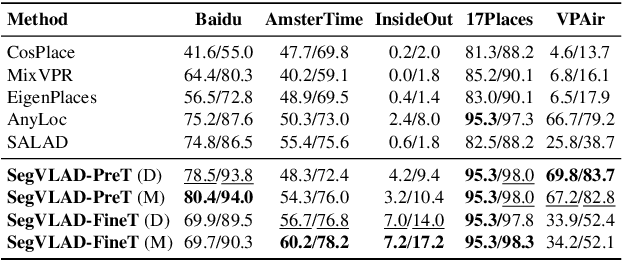
Accurately recognizing a revisited place is crucial for embodied agents to localize and navigate. This requires visual representations to be distinct, despite strong variations in camera viewpoint and scene appearance. Existing visual place recognition pipelines encode the "whole" image and search for matches. This poses a fundamental challenge in matching two images of the same place captured from different camera viewpoints: "the similarity of what overlaps can be dominated by the dissimilarity of what does not overlap". We address this by encoding and searching for "image segments" instead of the whole images. We propose to use open-set image segmentation to decompose an image into `meaningful' entities (i.e., things and stuff). This enables us to create a novel image representation as a collection of multiple overlapping subgraphs connecting a segment with its neighboring segments, dubbed SuperSegment. Furthermore, to efficiently encode these SuperSegments into compact vector representations, we propose a novel factorized representation of feature aggregation. We show that retrieving these partial representations leads to significantly higher recognition recall than the typical whole image based retrieval. Our segments-based approach, dubbed SegVLAD, sets a new state-of-the-art in place recognition on a diverse selection of benchmark datasets, while being applicable to both generic and task-specialized image encoders. Finally, we demonstrate the potential of our method to ``revisit anything'' by evaluating our method on an object instance retrieval task, which bridges the two disparate areas of research: visual place recognition and object-goal navigation, through their common aim of recognizing goal objects specific to a place. Source code: https://github.com/AnyLoc/Revisit-Anything.