 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDART: Learning-Enhanced Model Predictive Control for Dual-Arm Non-Prehensile Manipulation
Apr 20, 2026What appears effortless to a human waiter remains a major challenge for robots. Manipulating objects nonprehensilely on a tray is inherently difficult, and the complexity is amplified in dual-arm settings. Such tasks are highly relevant to service robotics in domains such as hotels and hospitality, where robots must transport and reposition diverse objects with precision. We present DART, a novel dual-arm framework that integrates nonlinear Model Predictive Control (MPC) with an optimization-based impedance controller to achieve accurate object motion relative to a dynamically controlled tray. The framework systematically evaluates three complementary strategies for modeling tray-object dynamics as the state transition function within our MPC formulation: (i) a physics-based analytical model, (ii) an online regression based identification model that adapts in real-time, and (iii) a reinforcement learning-based dynamics model that generalizes across object properties. Our pipeline is validated in simulation with objects of varying mass, geometry, and friction coefficients. Extensive evaluations highlight the trade-offs among the three modeling strategies in terms of settling time, steady-state error, control effort, and generalization across objects. To the best of our knowledge, DART constitutes the first framework for non-prehensile dual-arm manipulation of objects on a tray. Project Link: https://dart-icra.github.io/dart/
SPOT: Spatio-Temporal Obstacle-free Trajectory Planning for UAVs in an Unknown Dynamic Environment
Feb 01, 2026We address the problem of reactive motion planning for quadrotors operating in unknown environments with dynamic obstacles. Our approach leverages a 4-dimensional spatio-temporal planner, integrated with vision-based Safe Flight Corridor (SFC) generation and trajectory optimization. Unlike prior methods that rely on map fusion, our framework is mapless, enabling collision avoidance directly from perception while reducing computational overhead. Dynamic obstacles are detected and tracked using a vision-based object segmentation and tracking pipeline, allowing robust classification of static versus dynamic elements in the scene. To further enhance robustness, we introduce a backup planning module that reactively avoids dynamic obstacles when no direct path to the goal is available, mitigating the risk of collisions during deadlock situations. We validate our method extensively in both simulation and real-world hardware experiments, and benchmark it against state-of-the-art approaches, showing significant advantages for reactive UAV navigation in dynamic, unknown environments.
SegMASt3R: Geometry Grounded Segment Matching
Oct 06, 2025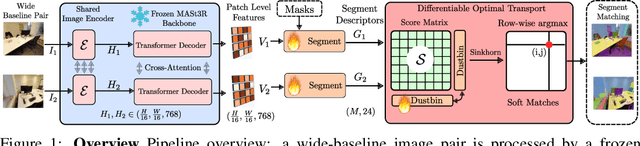
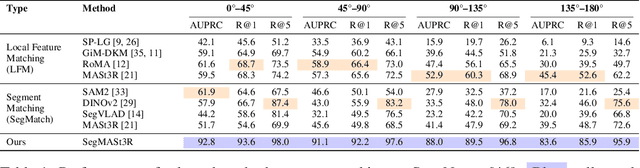


Segment matching is an important intermediate task in computer vision that establishes correspondences between semantically or geometrically coherent regions across images. Unlike keypoint matching, which focuses on localized features, segment matching captures structured regions, offering greater robustness to occlusions, lighting variations, and viewpoint changes. In this paper, we leverage the spatial understanding of 3D foundation models to tackle wide-baseline segment matching, a challenging setting involving extreme viewpoint shifts. We propose an architecture that uses the inductive bias of these 3D foundation models to match segments across image pairs with up to 180 degree view-point change. Extensive experiments show that our approach outperforms state-of-the-art methods, including the SAM2 video propagator and local feature matching methods, by upto 30% on the AUPRC metric, on ScanNet++ and Replica datasets. We further demonstrate benefits of the proposed model on relevant downstream tasks, including 3D instance segmentation and image-goal navigation. Project Page: https://segmast3r.github.io/
ObjectReact: Learning Object-Relative Control for Visual Navigation
Sep 11, 2025Visual navigation using only a single camera and a topological map has recently become an appealing alternative to methods that require additional sensors and 3D maps. This is typically achieved through an "image-relative" approach to estimating control from a given pair of current observation and subgoal image. However, image-level representations of the world have limitations because images are strictly tied to the agent's pose and embodiment. In contrast, objects, being a property of the map, offer an embodiment- and trajectory-invariant world representation. In this work, we present a new paradigm of learning "object-relative" control that exhibits several desirable characteristics: a) new routes can be traversed without strictly requiring to imitate prior experience, b) the control prediction problem can be decoupled from solving the image matching problem, and c) high invariance can be achieved in cross-embodiment deployment for variations across both training-testing and mapping-execution settings. We propose a topometric map representation in the form of a "relative" 3D scene graph, which is used to obtain more informative object-level global path planning costs. We train a local controller, dubbed "ObjectReact", conditioned directly on a high-level "WayObject Costmap" representation that eliminates the need for an explicit RGB input. We demonstrate the advantages of learning object-relative control over its image-relative counterpart across sensor height variations and multiple navigation tasks that challenge the underlying spatial understanding capability, e.g., navigating a map trajectory in the reverse direction. We further show that our sim-only policy is able to generalize well to real-world indoor environments. Code and supplementary material are accessible via project page: https://object-react.github.io/
Anticipate & Act : Integrating LLMs and Classical Planning for Efficient Task Execution in Household Environments
Feb 04, 2025



Assistive agents performing household tasks such as making the bed or cooking breakfast often compute and execute actions that accomplish one task at a time. However, efficiency can be improved by anticipating upcoming tasks and computing an action sequence that jointly achieves these tasks. State-of-the-art methods for task anticipation use data-driven deep networks and Large Language Models (LLMs), but they do so at the level of high-level tasks and/or require many training examples. Our framework leverages the generic knowledge of LLMs through a small number of prompts to perform high-level task anticipation, using the anticipated tasks as goals in a classical planning system to compute a sequence of finer-granularity actions that jointly achieve these goals. We ground and evaluate our framework's abilities in realistic scenarios in the VirtualHome environment and demonstrate a 31% reduction in execution time compared with a system that does not consider upcoming tasks.
AdaptBot: Combining LLM with Knowledge Graphs and Human Input for Generic-to-Specific Task Decomposition and Knowledge Refinement
Feb 04, 2025Embodied agents assisting humans are often asked to complete a new task in a new scenario. An agent preparing a particular dish in the kitchen based on a known recipe may be asked to prepare a new dish or to perform cleaning tasks in the storeroom. There may not be sufficient resources, e.g., time or labeled examples, to train the agent for these new situations. Large Language Models (LLMs) trained on considerable knowledge across many domains are able to predict a sequence of abstract actions for such new tasks and scenarios, although it may not be possible for the agent to execute this action sequence due to task-, agent-, or domain-specific constraints. Our framework addresses these challenges by leveraging the generic predictions provided by LLM and the prior domain-specific knowledge encoded in a Knowledge Graph (KG), enabling an agent to quickly adapt to new tasks and scenarios. The robot also solicits and uses human input as needed to refine its existing knowledge. Based on experimental evaluation over cooking and cleaning tasks in simulation domains, we demonstrate that the interplay between LLM, KG, and human input leads to substantial performance gains compared with just using the LLM output.
GPD: Guided Polynomial Diffusion for Motion Planning
Jan 30, 2025



Diffusion-based motion planners are becoming popular due to their well-established performance improvements, stemming from sample diversity and the ease of incorporating new constraints directly during inference. However, a primary limitation of the diffusion process is the requirement for a substantial number of denoising steps, especially when the denoising process is coupled with gradient-based guidance. In this paper, we introduce, diffusion in the parametric space of trajectories, where the parameters are represented as Bernstein coefficients. We show that this representation greatly improves the effectiveness of the cost function guidance and the inference speed. We also introduce a novel stitching algorithm that leverages the diversity in diffusion-generated trajectories to produce collision-free trajectories with just a single cost function-guided model. We demonstrate that our approaches outperform current SOTA diffusion-based motion planners for manipulators and provide an ablation study on key components.
Revisit Anything: Visual Place Recognition via Image Segment Retrieval
Sep 26, 2024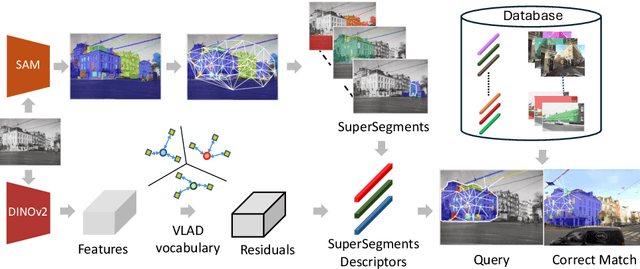
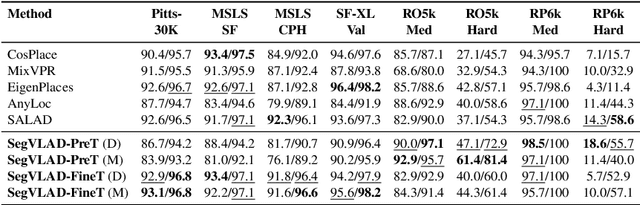

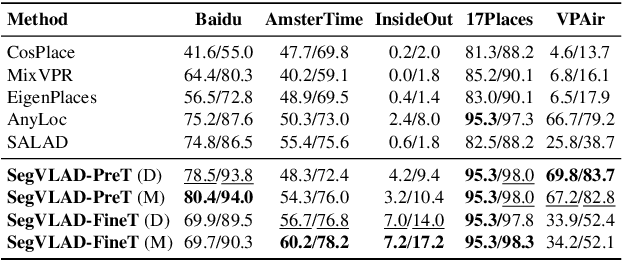
Accurately recognizing a revisited place is crucial for embodied agents to localize and navigate. This requires visual representations to be distinct, despite strong variations in camera viewpoint and scene appearance. Existing visual place recognition pipelines encode the "whole" image and search for matches. This poses a fundamental challenge in matching two images of the same place captured from different camera viewpoints: "the similarity of what overlaps can be dominated by the dissimilarity of what does not overlap". We address this by encoding and searching for "image segments" instead of the whole images. We propose to use open-set image segmentation to decompose an image into `meaningful' entities (i.e., things and stuff). This enables us to create a novel image representation as a collection of multiple overlapping subgraphs connecting a segment with its neighboring segments, dubbed SuperSegment. Furthermore, to efficiently encode these SuperSegments into compact vector representations, we propose a novel factorized representation of feature aggregation. We show that retrieving these partial representations leads to significantly higher recognition recall than the typical whole image based retrieval. Our segments-based approach, dubbed SegVLAD, sets a new state-of-the-art in place recognition on a diverse selection of benchmark datasets, while being applicable to both generic and task-specialized image encoders. Finally, we demonstrate the potential of our method to ``revisit anything'' by evaluating our method on an object instance retrieval task, which bridges the two disparate areas of research: visual place recognition and object-goal navigation, through their common aim of recognizing goal objects specific to a place. Source code: https://github.com/AnyLoc/Revisit-Anything.
Keypoint Aware Masked Image Modelling
Jul 18, 2024SimMIM is a widely used method for pretraining vision transformers using masked image modeling. However, despite its success in fine-tuning performance, it has been shown to perform sub-optimally when used for linear probing. We propose an efficient patch-wise weighting derived from keypoint features which captures the local information and provides better context during SimMIM's reconstruction phase. Our method, KAMIM, improves the top-1 linear probing accuracy from 16.12% to 33.97%, and finetuning accuracy from 76.78% to 77.3% when tested on the ImageNet-1K dataset with a ViT-B when trained for the same number of epochs. We conduct extensive testing on different datasets, keypoint extractors, and model architectures and observe that patch-wise weighting augments linear probing performance for larger pretraining datasets. We also analyze the learned representations of a ViT-B trained using KAMIM and observe that they behave similar to contrastive learning with regard to its behavior, with longer attention distances and homogenous self-attention across layers. Our code is publicly available at https://github.com/madhava20217/KAMIM.
Using LLMs in Software Requirements Specifications: An Empirical Evaluation
Apr 27, 2024The creation of a Software Requirements Specification (SRS) document is important for any software development project. Given the recent prowess of Large Language Models (LLMs) in answering natural language queries and generating sophisticated textual outputs, our study explores their capability to produce accurate, coherent, and structured drafts of these documents to accelerate the software development lifecycle. We assess the performance of GPT-4 and CodeLlama in drafting an SRS for a university club management system and compare it against human benchmarks using eight distinct criteria. Our results suggest that LLMs can match the output quality of an entry-level software engineer to generate an SRS, delivering complete and consistent drafts. We also evaluate the capabilities of LLMs to identify and rectify problems in a given requirements document. Our experiments indicate that GPT-4 is capable of identifying issues and giving constructive feedback for rectifying them, while CodeLlama's results for validation were not as encouraging. We repeated the generation exercise for four distinct use cases to study the time saved by employing LLMs for SRS generation. The experiment demonstrates that LLMs may facilitate a significant reduction in development time for entry-level software engineers. Hence, we conclude that the LLMs can be gainfully used by software engineers to increase productivity by saving time and effort in generating, validating and rectifying software requirements.