 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAD-Relight: Training-Free Banner Relighting via Illumination Translation with Diffusion Priors
Apr 27, 2026The recent surge in content consumption through streaming services has driven a growing demand for personalized content. Personalized advertisements (ads) play a crucial role in enhancing both user engagement and ad effectiveness. A key aspect of ad personalization involves replacing existing regions in a frame with custom, Photoshop-generated banners. However, existing ad-placement pipelines typically rely on simple geometric warping, ignoring the scene's underlying lighting conditions. Similarly, state-of-the-art diffusion-based object insertion and relighting models struggle to accurately relight these newly inserted banners, as they are not trained on ad-banner data, and training such a model for ad banners would require millions of images. This highlights the need for an effective relighting framework that enables seamless integration of custom banners into the original scene. Motivated by this, we present AD-Relight, a novel multi-stage training-free framework that adapts a diffusion-based relighting model at test time to relight newly added Photoshop-generated ad banners. Through extensive evaluation, we demonstrate that AD-Relight outperforms both relighting baselines and existing ad-placement methods based on simple warping. User studies further show that participants consistently prefer the outputs of AD-Relight over those of prior approaches.
Unified Multi-Dataset Training for TBPS
Jan 21, 2026Text-Based Person Search (TBPS) has seen significant progress with vision-language models (VLMs), yet it remains constrained by limited training data and the fact that VLMs are not inherently pre-trained for pedestrian-centric recognition. Existing TBPS methods therefore rely on dataset-centric fine-tuning to handle distribution shift, resulting in multiple independently trained models for different datasets. While synthetic data can increase the scale needed to fine-tune VLMs, it does not eliminate dataset-specific adaptation. This motivates a fundamental question: can we train a single unified TBPS model across multiple datasets? We show that naive joint training over all datasets remains sub-optimal because current training paradigms do not scale to a large number of unique person identities and are vulnerable to noisy image-text pairs. To address these challenges, we propose Scale-TBPS with two contributions: (i) a noise-aware unified dataset curation strategy that cohesively merges diverse TBPS datasets; and (ii) a scalable discriminative identity learning framework that remains effective under a large number of unique identities. Extensive experiments on CUHK-PEDES, ICFG-PEDES, RSTPReid, IIITD-20K, and UFine6926 demonstrate that a single Scale-TBPS model outperforms dataset-centric optimized models and naive joint training.
Boosting Weak Positives for Text Based Person Search
Jan 30, 2025



Large vision-language models have revolutionized cross-modal object retrieval, but text-based person search (TBPS) remains a challenging task due to limited data and fine-grained nature of the task. Existing methods primarily focus on aligning image-text pairs into a common representation space, often disregarding the fact that real world positive image-text pairs share a varied degree of similarity in between them. This leads models to prioritize easy pairs, and in some recent approaches, challenging samples are discarded as noise during training. In this work, we introduce a boosting technique that dynamically identifies and emphasizes these challenging samples during training. Our approach is motivated from classical boosting technique and dynamically updates the weights of the weak positives, wherein, the rank-1 match does not share the identity of the query. The weight allows these misranked pairs to contribute more towards the loss and the network has to pay more attention towards such samples. Our method achieves improved performance across four pedestrian datasets, demonstrating the effectiveness of our proposed module.
Keypoint Aware Masked Image Modelling
Jul 18, 2024SimMIM is a widely used method for pretraining vision transformers using masked image modeling. However, despite its success in fine-tuning performance, it has been shown to perform sub-optimally when used for linear probing. We propose an efficient patch-wise weighting derived from keypoint features which captures the local information and provides better context during SimMIM's reconstruction phase. Our method, KAMIM, improves the top-1 linear probing accuracy from 16.12% to 33.97%, and finetuning accuracy from 76.78% to 77.3% when tested on the ImageNet-1K dataset with a ViT-B when trained for the same number of epochs. We conduct extensive testing on different datasets, keypoint extractors, and model architectures and observe that patch-wise weighting augments linear probing performance for larger pretraining datasets. We also analyze the learned representations of a ViT-B trained using KAMIM and observe that they behave similar to contrastive learning with regard to its behavior, with longer attention distances and homogenous self-attention across layers. Our code is publicly available at https://github.com/madhava20217/KAMIM.
Resource Efficient Perception for Vision Systems
May 12, 2024



Despite the rapid advancement in the field of image recognition, the processing of high-resolution imagery remains a computational challenge. However, this processing is pivotal for extracting detailed object insights in areas ranging from autonomous vehicle navigation to medical imaging analyses. Our study introduces a framework aimed at mitigating these challenges by leveraging memory efficient patch based processing for high resolution images. It incorporates a global context representation alongside local patch information, enabling a comprehensive understanding of the image content. In contrast to traditional training methods which are limited by memory constraints, our method enables training of ultra high resolution images. We demonstrate the effectiveness of our method through superior performance on 7 different benchmarks across classification, object detection, and segmentation. Notably, the proposed method achieves strong performance even on resource-constrained devices like Jetson Nano. Our code is available at https://github.com/Visual-Conception-Group/Localized-Perception-Constrained-Vision-Systems.
Image Synthesis with Graph Conditioning: CLIP-Guided Diffusion Models for Scene Graphs
Jan 26, 2024Advancements in generative models have sparked significant interest in generating images while adhering to specific structural guidelines. Scene graph to image generation is one such task of generating images which are consistent with the given scene graph. However, the complexity of visual scenes poses a challenge in accurately aligning objects based on specified relations within the scene graph. Existing methods approach this task by first predicting a scene layout and generating images from these layouts using adversarial training. In this work, we introduce a novel approach to generate images from scene graphs which eliminates the need of predicting intermediate layouts. We leverage pre-trained text-to-image diffusion models and CLIP guidance to translate graph knowledge into images. Towards this, we first pre-train our graph encoder to align graph features with CLIP features of corresponding images using a GAN based training. Further, we fuse the graph features with CLIP embedding of object labels present in the given scene graph to create a graph consistent CLIP guided conditioning signal. In the conditioning input, object embeddings provide coarse structure of the image and graph features provide structural alignment based on relationships among objects. Finally, we fine tune a pre-trained diffusion model with the graph consistent conditioning signal with reconstruction and CLIP alignment loss. Elaborate experiments reveal that our method outperforms existing methods on standard benchmarks of COCO-stuff and Visual Genome dataset.
Language Guided Adversarial Purification
Sep 19, 2023


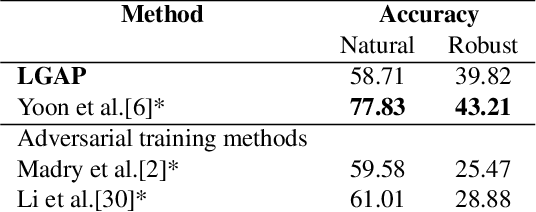
Adversarial purification using generative models demonstrates strong adversarial defense performance. These methods are classifier and attack-agnostic, making them versatile but often computationally intensive. Recent strides in diffusion and score networks have improved image generation and, by extension, adversarial purification. Another highly efficient class of adversarial defense methods known as adversarial training requires specific knowledge of attack vectors, forcing them to be trained extensively on adversarial examples. To overcome these limitations, we introduce a new framework, namely Language Guided Adversarial Purification (LGAP), utilizing pre-trained diffusion models and caption generators to defend against adversarial attacks. Given an input image, our method first generates a caption, which is then used to guide the adversarial purification process through a diffusion network. Our approach has been evaluated against strong adversarial attacks, proving its effectiveness in enhancing adversarial robustness. Our results indicate that LGAP outperforms most existing adversarial defense techniques without requiring specialized network training. This underscores the generalizability of models trained on large datasets, highlighting a promising direction for further research.
IIITD-20K: Dense captioning for Text-Image ReID
May 08, 2023


Text-to-Image (T2I) ReID has attracted a lot of attention in the recent past. CUHK-PEDES, RSTPReid and ICFG-PEDES are the three available benchmarks to evaluate T2I ReID methods. RSTPReid and ICFG-PEDES comprise of identities from MSMT17 but due to limited number of unique persons, the diversity is limited. On the other hand, CUHK-PEDES comprises of 13,003 identities but has relatively shorter text description on average. Further, these datasets are captured in a restricted environment with limited number of cameras. In order to further diversify the identities and provide dense captions, we propose a novel dataset called IIITD-20K. IIITD-20K comprises of 20,000 unique identities captured in the wild and provides a rich dataset for text-to-image ReID. With a minimum of 26 words for a description, each image is densely captioned. We further synthetically generate images and fine-grained captions using Stable-diffusion and BLIP models trained on our dataset. We perform elaborate experiments using state-of-art text-to-image ReID models and vision-language pre-trained models and present a comprehensive analysis of the dataset. Our experiments also reveal that synthetically generated data leads to a substantial performance improvement in both same dataset as well as cross dataset settings. Our dataset is available at https://bit.ly/3pkA3Rj.
Certified Zeroth-order Black-Box Defense with Robust UNet Denoiser
Apr 13, 2023



Certified defense methods against adversarial perturbations have been recently investigated in the black-box setting with a zeroth-order (ZO) perspective. However, these methods suffer from high model variance with low performance on high-dimensional datasets due to the ineffective design of the denoiser and are limited in their utilization of ZO techniques. To this end, we propose a certified ZO preprocessing technique for removing adversarial perturbations from the attacked image in the black-box setting using only model queries. We propose a robust UNet denoiser (RDUNet) that ensures the robustness of black-box models trained on high-dimensional datasets. We propose a novel black-box denoised smoothing (DS) defense mechanism, ZO-RUDS, by prepending our RDUNet to the black-box model, ensuring black-box defense. We further propose ZO-AE-RUDS in which RDUNet followed by autoencoder (AE) is prepended to the black-box model. We perform extensive experiments on four classification datasets, CIFAR-10, CIFAR-10, Tiny Imagenet, STL-10, and the MNIST dataset for image reconstruction tasks. Our proposed defense methods ZO-RUDS and ZO-AE-RUDS beat SOTA with a huge margin of $35\%$ and $9\%$, for low dimensional (CIFAR-10) and with a margin of $20.61\%$ and $23.51\%$ for high-dimensional (STL-10) datasets, respectively.
Meta Generative Attack on Person Reidentification
Jan 16, 2023Adversarial attacks have been recently investigated in person re-identification. These attacks perform well under cross dataset or cross model setting. However, the challenges present in cross-dataset cross-model scenario does not allow these models to achieve similar accuracy. To this end, we propose our method with the goal of achieving better transferability against different models and across datasets. We generate a mask to obtain better performance across models and use meta learning to boost the generalizability in the challenging cross-dataset cross-model setting. Experiments on Market-1501, DukeMTMC-reID and MSMT-17 demonstrate favorable results compared to other attacks.