 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-CLIP: Enabling Thermal Perception for Contrastive Language-Image Pretraining
May 30, 2026Thermal imaging offers a powerful alternative to visible-spectrum vision under challenging conditions such as low illumination and adverse weather, yet foundational vision-language models like CLIP fail to align thermal images with textual descriptions due to a fundamental thermal perception gap. We identify three major challenges: the lack of captioned thermal datasets, the inability of standard LLMs to reason about thermal phenomena, and a key representational challenge in thermal imaging where global scene context and object-level heat signatures conflict when learned together in a single embedding space. To address these, we introduce IR-Cap, the first physics-aware thermal captioning pipeline and dataset providing complementary global and fine-grained thermal descriptions across three public benchmarks, and T-CLIP, a decoupled dual-LoRA framework that independently adapts CLIP for scene-level and object-level thermal understanding. T-CLIP achieves consistent improvements over all baselines across three thermal benchmarks in cross-modal retrieval, and we provide an exploratory demonstration of its applicability to text-conditioned thermal image generation.
Prompt Codebooks: Discrete Compositional Optimization for Language Model Instruction Refinement
May 27, 2026Automatic prompt optimization (APO) has driven significant gains in LLM-based agentic workflows. However, existing methods treat each task's prompt as a monolithic, instance-blind string optimized through global edits, producing brittle updates and preventing the reuse of learned sub-behaviors. We propose Prompt Codebooks (PCO), a novel compositional prompt optimization framework that recasts APO as discrete learning over a finite vocabulary of natural-language instincts - atomic, reusable instruction units. PCO organizes prompt-construction knowledge in a discrete codebook and routes each input to a small subset of entries via an LLM-based encoder; a generator composes them into a prompt for the frozen target model; a critic emits a structured verdict that decomposes by attribution into per-variable textual gradients, jointly training the encoder, generator, and codebook under a language-valued min-max objective. The resulting routing is per-instance: different inputs in the same task receive different instinct compositions, a regime structurally inexpressible under instance-blind methods. Across six benchmarks on Qwen3-8B and LLaMA-3.1-8B, PCO improves over zero-shot by up to +30.36 points, surpasses the strongest prior baseline (GEPA) by +3.34 on HotpotQA and +1.11 in aggregate, and reduces deployed prompt length by up to 14.1x versus MIPROv2 and 3.0x versus GEPA using only K=16 instincts.
Continual Segmentation under Joint Nonstationarity
May 19, 2026Evolving data streams induce joint nonstationarity in continual semantic segmentation, where semantic classes, input distributions, and supervision availability change simultaneously over time. This setting reflects practical structured prediction systems, yet remains largely unexplored in prior continual learning work, which typically studies these factors in isolation. We formalize continual segmentation under coupled class, domain, and label shifts and investigate learning in heterogeneous dense prediction environments with limited annotations and abundant unlabeled data. To address instability and overfitting arising from few-shot supervision under distribution drift, we introduce gradient-adaptive stabilization, a parameter-wise regularization mechanism implemented via gradient-scaled stochastic perturbations that promotes a principled stability-plasticity tradeoff. We further leverage unlabeled data through semi-supervised learning and introduce prototype anchored supervision that validates pseudo-labels via joint confidence and prototype consistency. Together, these mechanisms enable learning under joint nonstationarity in continual segmentation. Extensive empirical evaluation across class-incremental, domain-incremental, and few-shot regimes demonstrates consistent improvements over prior methods in heterogeneous structured prediction settings. Our results expose fundamental failure modes of existing continual segmentation approaches and provide insight into learning robust dense predictors in dynamically evolving environments.
Stride-Net: Fairness-Aware Disentangled Representation Learning for Chest X-Ray Diagnosis
Feb 11, 2026Deep neural networks for chest X-ray classification achieve strong average performance, yet often underperform for specific demographic subgroups, raising critical concerns about clinical safety and equity. Existing debiasing methods frequently yield inconsistent improvements across datasets or attain fairness by degrading overall diagnostic utility, treating fairness as a post hoc constraint rather than a property of the learned representation. In this work, we propose Stride-Net (Sensitive Attribute Resilient Learning via Disentanglement and Learnable Masking with Embedding Alignment), a fairness-aware framework that learns disease-discriminative yet demographically invariant representations for chest X-ray analysis. Stride-Net operates at the patch level, using a learnable stride-based mask to select label-aligned image regions while suppressing sensitive attribute information through adversarial confusion loss. To anchor representations in clinical semantics and discourage shortcut learning, we further enforce semantic alignment between image features and BioBERT-based disease label embeddings via Group Optimal Transport. We evaluate Stride-Net on the MIMIC-CXR and CheXpert benchmarks across race and intersectional race-gender subgroups. Across architectures including ResNet and Vision Transformers, Stride-Net consistently improves fairness metrics while matching or exceeding baseline accuracy, achieving a more favorable accuracy-fairness trade-off than prior debiasing approaches. Our code is available at https://github.com/Daraksh/Fairness_StrideNet.
Unified Multi-Dataset Training for TBPS
Jan 21, 2026Text-Based Person Search (TBPS) has seen significant progress with vision-language models (VLMs), yet it remains constrained by limited training data and the fact that VLMs are not inherently pre-trained for pedestrian-centric recognition. Existing TBPS methods therefore rely on dataset-centric fine-tuning to handle distribution shift, resulting in multiple independently trained models for different datasets. While synthetic data can increase the scale needed to fine-tune VLMs, it does not eliminate dataset-specific adaptation. This motivates a fundamental question: can we train a single unified TBPS model across multiple datasets? We show that naive joint training over all datasets remains sub-optimal because current training paradigms do not scale to a large number of unique person identities and are vulnerable to noisy image-text pairs. To address these challenges, we propose Scale-TBPS with two contributions: (i) a noise-aware unified dataset curation strategy that cohesively merges diverse TBPS datasets; and (ii) a scalable discriminative identity learning framework that remains effective under a large number of unique identities. Extensive experiments on CUHK-PEDES, ICFG-PEDES, RSTPReid, IIITD-20K, and UFine6926 demonstrate that a single Scale-TBPS model outperforms dataset-centric optimized models and naive joint training.
Generative QoE Modeling: A Lightweight Approach for Telecom Networks
Apr 30, 2025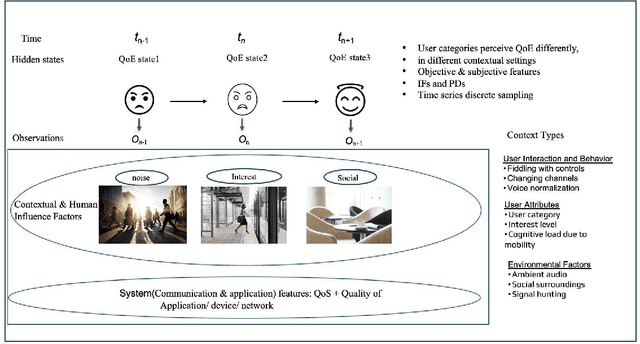
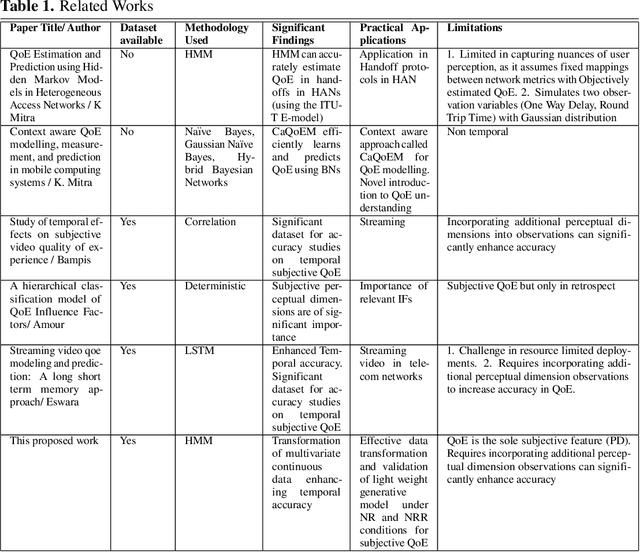

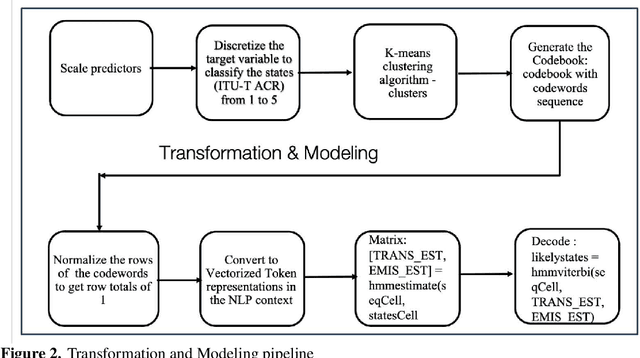
Quality of Experience (QoE) prediction plays a crucial role in optimizing resource management and enhancing user satisfaction across both telecommunication and OTT services. While recent advances predominantly rely on deep learning models, this study introduces a lightweight generative modeling framework that balances computational efficiency, interpretability, and predictive accuracy. By validating the use of Vector Quantization (VQ) as a preprocessing technique, continuous network features are effectively transformed into discrete categorical symbols, enabling integration with a Hidden Markov Model (HMM) for temporal sequence modeling. This VQ-HMM pipeline enhances the model's capacity to capture dynamic QoE patterns while supporting probabilistic inference on new and unseen data. Experimental results on publicly available time-series datasets incorporating both objective indicators and subjective QoE scores demonstrate the viability of this approach in real-time and resource-constrained environments, where inference latency is also critical. The framework offers a scalable alternative to complex deep learning methods, particularly in scenarios with limited computational resources or where latency constraints are critical.
Leveraging band diversity for feature selection in EO data
Feb 07, 2025

Hyperspectral imaging (HSI) is a powerful earth observation technology that captures and processes information across a wide spectrum of wavelengths. Hyperspectral imaging provides comprehensive and detailed spectral data that is invaluable for a wide range of reconstruction problems. However due to complexity in analysis it often becomes difficult to handle this data. To address the challenge of handling large number of bands in reconstructing high quality HSI, we propose to form groups of bands. In this position paper we propose a method of selecting diverse bands using determinantal point processes in correlated bands. To address the issue of overlapping bands that may arise from grouping, we use spectral angle mapper analysis. This analysis can be fed to any Machine learning model to enable detailed analysis and monitoring with high precision and accuracy.
DiffSTR: Controlled Diffusion Models for Scene Text Removal
Oct 29, 2024To prevent unauthorized use of text in images, Scene Text Removal (STR) has become a crucial task. It focuses on automatically removing text and replacing it with a natural, text-less background while preserving significant details such as texture, color, and contrast. Despite its importance in privacy protection, STR faces several challenges, including boundary artifacts, inconsistent texture and color, and preserving correct shadows. Most STR approaches estimate a text region mask to train a model, solving for image translation or inpainting to generate a text-free image. Thus, the quality of the generated image depends on the accuracy of the inpainting mask and the generator's capability. In this work, we leverage the superior capabilities of diffusion models in generating high-quality, consistent images to address the STR problem. We introduce a ControlNet diffusion model, treating STR as an inpainting task. To enhance the model's robustness, we develop a mask pretraining pipeline to condition our diffusion model. This involves training a masked autoencoder (MAE) using a combination of box masks and coarse stroke masks, and fine-tuning it using masks derived from our novel segmentation-based mask refinement framework. This framework iteratively refines an initial mask and segments it using the SLIC and Hierarchical Feature Selection (HFS) algorithms to produce an accurate final text mask. This improves mask prediction and utilizes rich textural information in natural scene images to provide accurate inpainting masks. Experiments on the SCUT-EnsText and SCUT-Syn datasets demonstrate that our method significantly outperforms existing state-of-the-art techniques.
A Comprehensive Survey on Synthetic Infrared Image synthesis
Aug 14, 2024



Synthetic infrared (IR) scene and target generation is an important computer vision problem as it allows the generation of realistic IR images and targets for training and testing of various applications, such as remote sensing, surveillance, and target recognition. It also helps reduce the cost and risk associated with collecting real-world IR data. This survey paper aims to provide a comprehensive overview of the conventional mathematical modelling-based methods and deep learning-based methods used for generating synthetic IR scenes and targets. The paper discusses the importance of synthetic IR scene and target generation and briefly covers the mathematics of blackbody and grey body radiations, as well as IR image-capturing methods. The potential use cases of synthetic IR scenes and target generation are also described, highlighting the significance of these techniques in various fields. Additionally, the paper explores possible new ways of developing new techniques to enhance the efficiency and effectiveness of synthetic IR scenes and target generation while highlighting the need for further research to advance this field.
Optimizing Vision Transformers with Data-Free Knowledge Transfer
Aug 12, 2024The groundbreaking performance of transformers in Natural Language Processing (NLP) tasks has led to their replacement of traditional Convolutional Neural Networks (CNNs), owing to the efficiency and accuracy achieved through the self-attention mechanism. This success has inspired researchers to explore the use of transformers in computer vision tasks to attain enhanced long-term semantic awareness. Vision transformers (ViTs) have excelled in various computer vision tasks due to their superior ability to capture long-distance dependencies using the self-attention mechanism. Contemporary ViTs like Data Efficient Transformers (DeiT) can effectively learn both global semantic information and local texture information from images, achieving performance comparable to traditional CNNs. However, their impressive performance comes with a high computational cost due to very large number of parameters, hindering their deployment on devices with limited resources like smartphones, cameras, drones etc. Additionally, ViTs require a large amount of data for training to achieve performance comparable to benchmark CNN models. Therefore, we identified two key challenges in deploying ViTs on smaller form factor devices: the high computational requirements of large models and the need for extensive training data. As a solution to these challenges, we propose compressing large ViT models using Knowledge Distillation (KD), which is implemented data-free to circumvent limitations related to data availability. Additionally, we conducted experiments on object detection within the same environment in addition to classification tasks. Based on our analysis, we found that datafree knowledge distillation is an effective method to overcome both issues, enabling the deployment of ViTs on less resourceconstrained devices.