 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-CLIP: Enabling Thermal Perception for Contrastive Language-Image Pretraining
May 30, 2026Thermal imaging offers a powerful alternative to visible-spectrum vision under challenging conditions such as low illumination and adverse weather, yet foundational vision-language models like CLIP fail to align thermal images with textual descriptions due to a fundamental thermal perception gap. We identify three major challenges: the lack of captioned thermal datasets, the inability of standard LLMs to reason about thermal phenomena, and a key representational challenge in thermal imaging where global scene context and object-level heat signatures conflict when learned together in a single embedding space. To address these, we introduce IR-Cap, the first physics-aware thermal captioning pipeline and dataset providing complementary global and fine-grained thermal descriptions across three public benchmarks, and T-CLIP, a decoupled dual-LoRA framework that independently adapts CLIP for scene-level and object-level thermal understanding. T-CLIP achieves consistent improvements over all baselines across three thermal benchmarks in cross-modal retrieval, and we provide an exploratory demonstration of its applicability to text-conditioned thermal image generation.
A Comprehensive Survey on Synthetic Infrared Image synthesis
Aug 14, 2024



Synthetic infrared (IR) scene and target generation is an important computer vision problem as it allows the generation of realistic IR images and targets for training and testing of various applications, such as remote sensing, surveillance, and target recognition. It also helps reduce the cost and risk associated with collecting real-world IR data. This survey paper aims to provide a comprehensive overview of the conventional mathematical modelling-based methods and deep learning-based methods used for generating synthetic IR scenes and targets. The paper discusses the importance of synthetic IR scene and target generation and briefly covers the mathematics of blackbody and grey body radiations, as well as IR image-capturing methods. The potential use cases of synthetic IR scenes and target generation are also described, highlighting the significance of these techniques in various fields. Additionally, the paper explores possible new ways of developing new techniques to enhance the efficiency and effectiveness of synthetic IR scenes and target generation while highlighting the need for further research to advance this field.
OCFormer: One-Class Transformer Network for Image Classification
Apr 25, 2022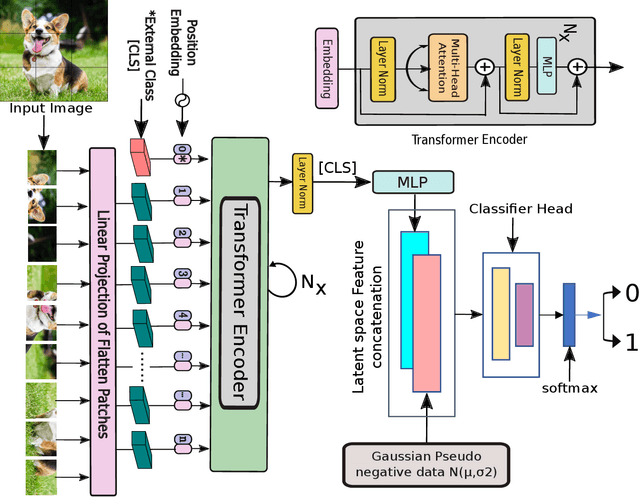

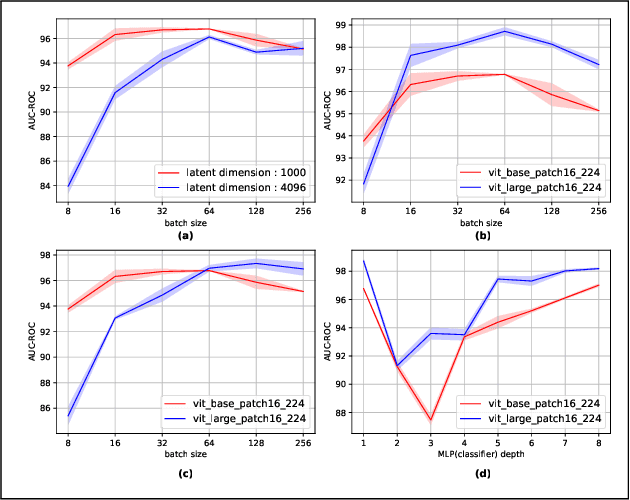
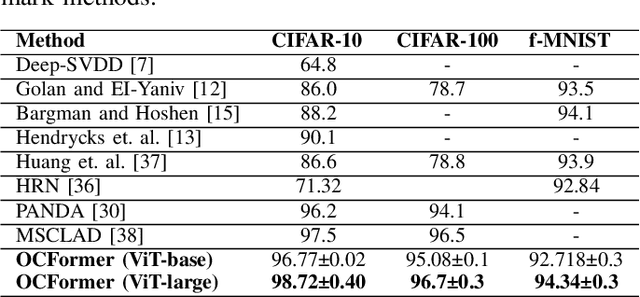
We propose a novel deep learning framework based on Vision Transformers (ViT) for one-class classification. The core idea is to use zero-centered Gaussian noise as a pseudo-negative class for latent space representation and then train the network using the optimal loss function. In prior works, there have been tremendous efforts to learn a good representation using varieties of loss functions, which ensures both discriminative and compact properties. The proposed one-class Vision Transformer (OCFormer) is exhaustively experimented on CIFAR-10, CIFAR-100, Fashion-MNIST and CelebA eyeglasses datasets. Our method has shown significant improvements over competing CNN based one-class classifier approaches.
ASOC: Adaptive Self-aware Object Co-localization
Jan 27, 2022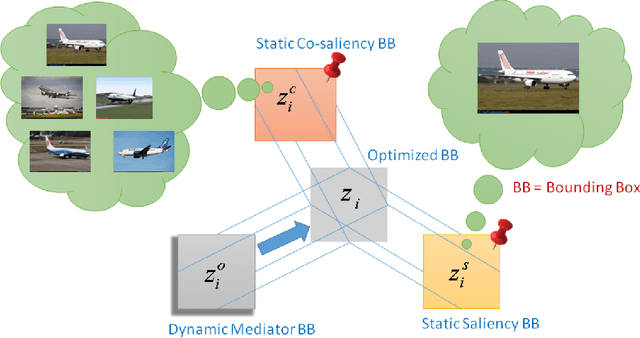
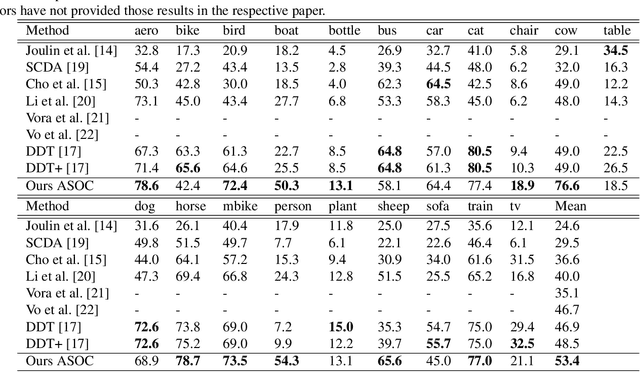

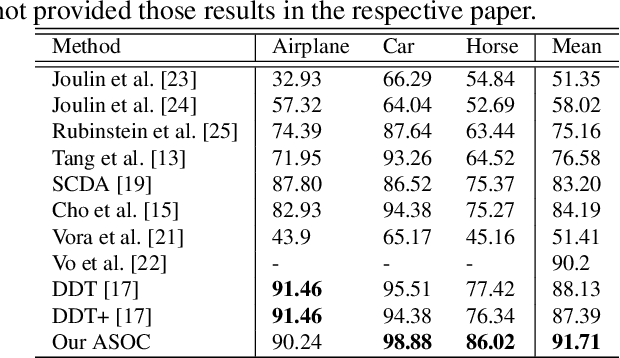
The primary goal of this paper is to localize objects in a group of semantically similar images jointly, also known as the object co-localization problem. Most related existing works are essentially weakly-supervised, relying prominently on the neighboring images' weak-supervision. Although weak supervision is beneficial, it is not entirely reliable, for the results are quite sensitive to the neighboring images considered. In this paper, we combine it with a self-awareness phenomenon to mitigate this issue. By self-awareness here, we refer to the solution derived from the image itself in the form of saliency cue, which can also be unreliable if applied alone. Nevertheless, combining these two paradigms together can lead to a better co-localization ability. Specifically, we introduce a dynamic mediator that adaptively strikes a proper balance between the two static solutions to provide an optimal solution. Therefore, we call this method \textit{ASOC}: Adaptive Self-aware Object Co-localization. We perform exhaustive experiments on several benchmark datasets and validate that weak-supervision supplemented with self-awareness has superior performance outperforming several compared competing methods.
* Published in IEEE ICME 2021. Please cite this paper in the following manner: K. R. Jerripothula and P. Mukherjee, "ASOC: Adaptive Self-Aware Object Co-Localization," 2021 IEEE International Conference on Multimedia and Expo (ICME), 2021, pp. 1-6, doi: 10.1109/ICME51207.2021.9428191
MaskMTL: Attribute prediction in masked facial images with deep multitask learning
Jan 11, 2022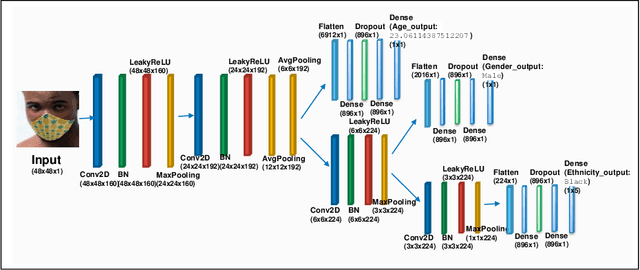
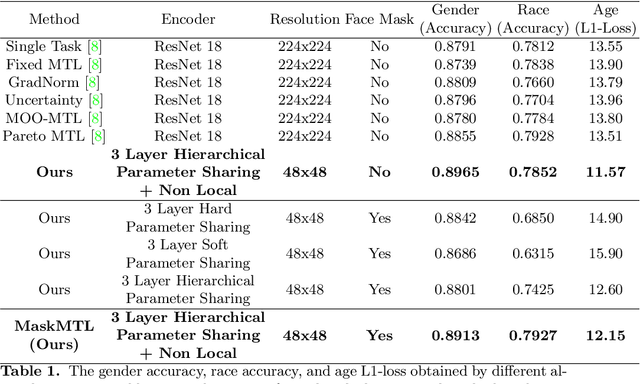

Predicting attributes in the landmark free facial images is itself a challenging task which gets further complicated when the face gets occluded due to the usage of masks. Smart access control gates which utilize identity verification or the secure login to personal electronic gadgets may utilize face as a biometric trait. Particularly, the Covid-19 pandemic increasingly validates the essentiality of hygienic and contactless identity verification. In such cases, the usage of masks become more inevitable and performing attribute prediction helps in segregating the target vulnerable groups from community spread or ensuring social distancing for them in a collaborative environment. We create a masked face dataset by efficiently overlaying masks of different shape, size and textures to effectively model variability generated by wearing mask. This paper presents a deep Multi-Task Learning (MTL) approach to jointly estimate various heterogeneous attributes from a single masked facial image. Experimental results on benchmark face attribute UTKFace dataset demonstrate that the proposed approach supersedes in performance to other competing techniques. The source code is available at https://github.com/ritikajha/Attribute-prediction-in-masked-facial-images-with-deep-multitask-learning
Hater-O-Genius Aggression Classification using Capsule Networks
May 24, 2021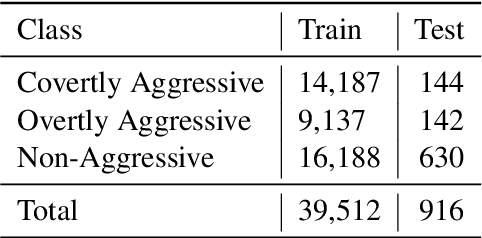
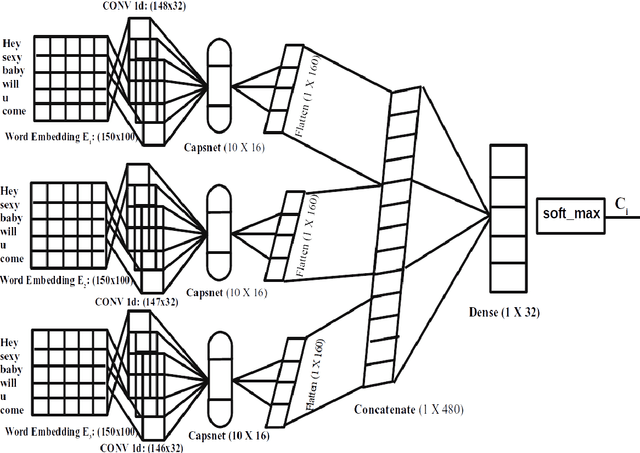
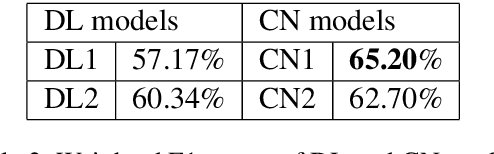
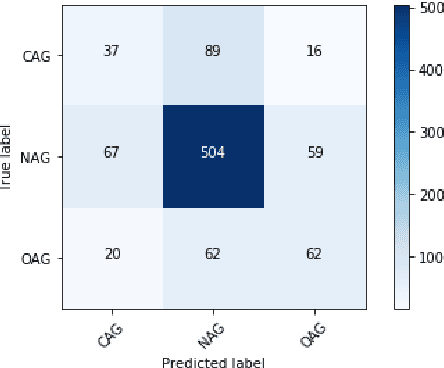
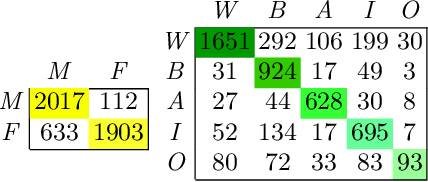
Contending hate speech in social media is one of the most challenging social problems of our time. There are various types of anti-social behavior in social media. Foremost of them is aggressive behavior, which is causing many social issues such as affecting the social lives and mental health of social media users. In this paper, we propose an end-to-end ensemble-based architecture to automatically identify and classify aggressive tweets. Tweets are classified into three categories - Covertly Aggressive, Overtly Aggressive, and Non-Aggressive. The proposed architecture is an ensemble of smaller subnetworks that are able to characterize the feature embeddings effectively. We demonstrate qualitatively that each of the smaller subnetworks is able to learn unique features. Our best model is an ensemble of Capsule Networks and results in a 65.2% F1 score on the Facebook test set, which results in a performance gain of 0.95% over the TRAC-2018 winners. The code and the model weights are publicly available at https://github.com/parthpatwa/Hater-O-Genius-Aggression-Classification-using-Capsule-Networks.
Generating Out of Distribution Adversarial Attack using Latent Space Poisoning
Dec 09, 2020



Traditional adversarial attacks rely upon the perturbations generated by gradients from the network which are generally safeguarded by gradient guided search to provide an adversarial counterpart to the network. In this paper, we propose a novel mechanism of generating adversarial examples where the actual image is not corrupted rather its latent space representation is utilized to tamper with the inherent structure of the image while maintaining the perceptual quality intact and to act as legitimate data samples. As opposed to gradient-based attacks, the latent space poisoning exploits the inclination of classifiers to model the independent and identical distribution of the training dataset and tricks it by producing out of distribution samples. We train a disentangled variational autoencoder (beta-VAE) to model the data in latent space and then we add noise perturbations using a class-conditioned distribution function to the latent space under the constraint that it is misclassified to the target label. Our empirical results on MNIST, SVHN, and CelebA dataset validate that the generated adversarial examples can easily fool robust l_0, l_2, l_inf norm classifiers designed using provably robust defense mechanisms.
Attentional networks for music generation
Feb 06, 2020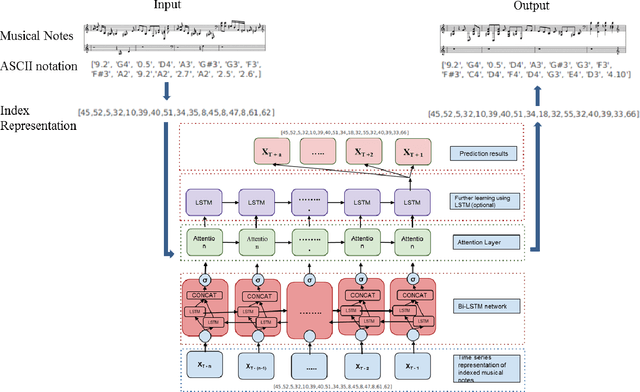
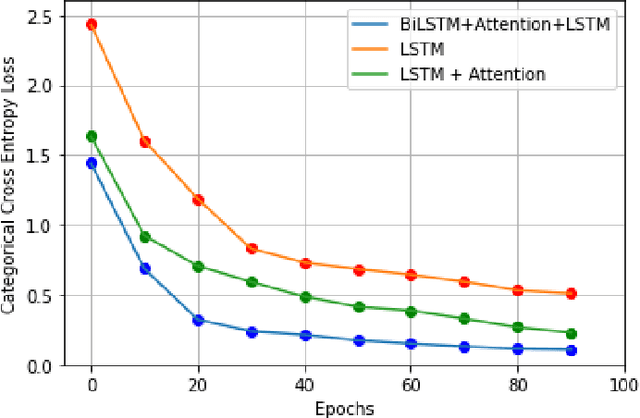
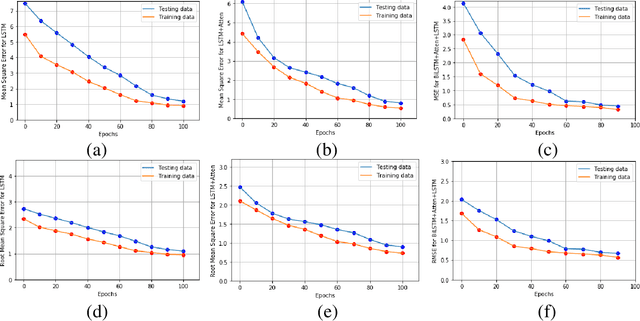
Realistic music generation has always remained as a challenging problem as it may lack structure or rationality. In this work, we propose a deep learning based music generation method in order to produce old style music particularly JAZZ with rehashed melodic structures utilizing a Bi-directional Long Short Term Memory (Bi-LSTM) Neural Network with Attention. Owing to the success in modelling long-term temporal dependencies in sequential data and its success in case of videos, Bi-LSTMs with attention serve as the natural choice and early utilization in music generation. We validate in our experiments that Bi-LSTMs with attention are able to preserve the richness and technical nuances of the music performed.
AnimePose: Multi-person 3D pose estimation and animation
Feb 06, 2020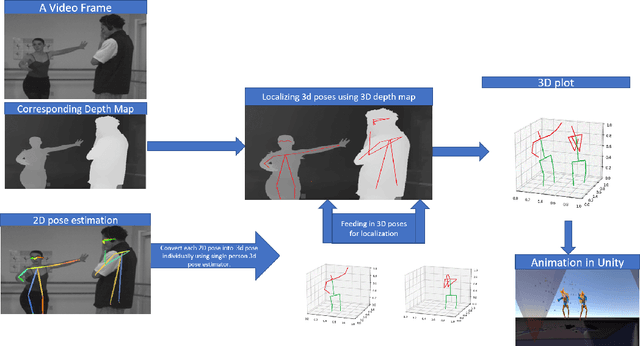



3D animation of humans in action is quite challenging as it involves using a huge setup with several motion trackers all over the person's body to track the movements of every limb. This is time-consuming and may cause the person discomfort in wearing exoskeleton body suits with motion sensors. In this work, we present a trivial yet effective solution to generate 3D animation of multiple persons from a 2D video using deep learning. Although significant improvement has been achieved recently in 3D human pose estimation, most of the prior works work well in case of single person pose estimation and multi-person pose estimation is still a challenging problem. In this work, we firstly propose a supervised multi-person 3D pose estimation and animation framework namely AnimePose for a given input RGB video sequence. The pipeline of the proposed system consists of various modules: i) Person detection and segmentation, ii) Depth Map estimation, iii) Lifting 2D to 3D information for person localization iv) Person trajectory prediction and human pose tracking. Our proposed system produces comparable results on previous state-of-the-art 3D multi-person pose estimation methods on publicly available datasets MuCo-3DHP and MuPoTS-3D datasets and it also outperforms previous state-of-the-art human pose tracking methods by a significant margin of 11.7% performance gain on MOTA score on Posetrack 2018 dataset.
Aerial multi-object tracking by detection using deep association networks
Sep 04, 2019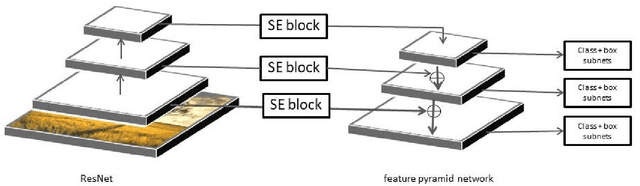
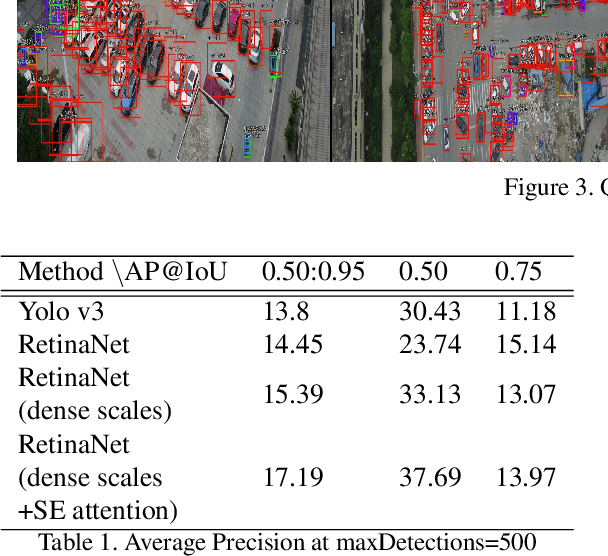

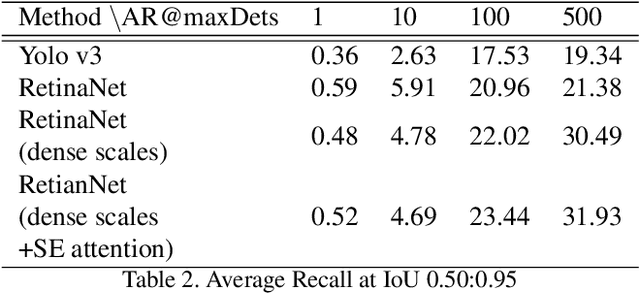
A lot a research is focused on object detection and it has achieved significant advances with deep learning techniques in recent years. Inspite of the existing research, these algorithms are not usually optimal for dealing with sequences or images captured by drone-based platforms, due to various challenges such as view point change, scales, density of object distribution and occlusion. In this paper, we develop a model for detection of objects in drone images using the VisDrone2019 DET dataset. Using the RetinaNet model as our base, we modify the anchor scales to better handle the detection of dense distribution and small size of the objects. We explicitly model the channel interdependencies by using "Squeeze-and-Excitation" (SE) blocks that adaptively recalibrates channel-wise feature responses. This helps to bring significant improvements in performance at a slight additional computational cost. Using this architecture for object detection, we build a custom DeepSORT network for object detection on the VisDrone2019 MOT dataset by training a custom Deep Association network for the algorithm.