 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeListen, Look, and Learn: Learning Without Forgetting through SAM-Audio
Jun 09, 2026Class-Incremental Learning (CIL) aims to continuously learn new classes without forgetting previously acquired knowledge. While recent CIL advances have spurred significant interest across various modalities, the audio-visual setting remains underexplored. Furthermore, although foundational multimodal models like SAM-Audio encapsulate rich static priors, our empirical analysis reveals that these representations struggle in incremental settings. This work bridges this gap by integrating SAM-Audio's audio-visual priors into the CIL setting. Specifically, we leverage its dense audio and visual representations and employ a novel guided attention strategy where the audio features contextually guide the visual representations. To further mitigate catastrophic forgetting, we introduce dual-level distillation objectives at both the feature and logit levels. Extensive evaluations on audio-visual CIL benchmarks demonstrate that our approach consistently outperforms state-of-the-art methods.
SAMwave: Wavelet-Driven Feature Enrichment for Effective Adaptation of Segment Anything Model
Jul 27, 2025The emergence of large foundation models has propelled significant advances in various domains. The Segment Anything Model (SAM), a leading model for image segmentation, exemplifies these advances, outperforming traditional methods. However, such foundation models often suffer from performance degradation when applied to complex tasks for which they are not trained. Existing methods typically employ adapter-based fine-tuning strategies to adapt SAM for tasks and leverage high-frequency features extracted from the Fourier domain. However, Our analysis reveals that these approaches offer limited benefits due to constraints in their feature extraction techniques. To overcome this, we propose \textbf{\textit{SAMwave}}, a novel and interpretable approach that utilizes the wavelet transform to extract richer, multi-scale high-frequency features from input data. Extending this, we introduce complex-valued adapters capable of capturing complex-valued spatial-frequency information via complex wavelet transforms. By adaptively integrating these wavelet coefficients, SAMwave enables SAM's encoder to capture information more relevant for dense prediction. Empirical evaluations on four challenging low-level vision tasks demonstrate that SAMwave significantly outperforms existing adaptation methods. This superior performance is consistent across both the SAM and SAM2 backbones and holds for both real and complex-valued adapter variants, highlighting the efficiency, flexibility, and interpretability of our proposed method for adapting segment anything models.
SymFace: Additional Facial Symmetry Loss for Deep Face Recognition
Sep 18, 2024
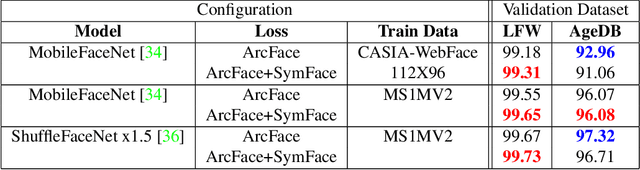


Over the past decade, there has been a steady advancement in enhancing face recognition algorithms leveraging advanced machine learning methods. The role of the loss function is pivotal in addressing face verification problems and playing a game-changing role. These loss functions have mainly explored variations among intra-class or inter-class separation. This research examines the natural phenomenon of facial symmetry in the face verification problem. The symmetry between the left and right hemi faces has been widely used in many research areas in recent decades. This paper adopts this simple approach judiciously by splitting the face image vertically into two halves. With the assumption that the natural phenomena of facial symmetry can enhance face verification methodology, we hypothesize that the two output embedding vectors of split faces must project close to each other in the output embedding space. Inspired by this concept, we penalize the network based on the disparity of embedding of the symmetrical pair of split faces. Symmetrical loss has the potential to minimize minor asymmetric features due to facial expression and lightning conditions, hence significantly increasing the inter-class variance among the classes and leading to more reliable face embedding. This loss function propels any network to outperform its baseline performance across all existing network architectures and configurations, enabling us to achieve SoTA results.
Comprehensive Saliency Fusion for Object Co-segmentation
Jan 30, 2022Object co-segmentation has drawn significant attention in recent years, thanks to its clarity on the expected foreground, the shared object in a group of images. Saliency fusion has been one of the promising ways to carry it out. However, prior works either fuse saliency maps of the same image or saliency maps of different images to extract the expected foregrounds. Also, they rely on hand-crafted saliency extraction and correspondence processes in most cases. This paper revisits the problem and proposes fusing saliency maps of both the same image and different images. It also leverages advances in deep learning for the saliency extraction and correspondence processes. Hence, we call it comprehensive saliency fusion. Our experiments reveal that our approach achieves much-improved object co-segmentation results compared to prior works on important benchmark datasets such as iCoseg, MSRC, and Internet Images.
* Published in IEEE ISM 2021. Please cite this paper in the following manner. H. S. Chhabra and K. Rao Jerripothula, "Comprehensive Saliency Fusion for Object Co-segmentation," 2021 IEEE International Symposium on Multimedia (ISM), 2021, pp. 107-110, doi: 10.1109/ISM52913.2021.00026
ASOC: Adaptive Self-aware Object Co-localization
Jan 27, 2022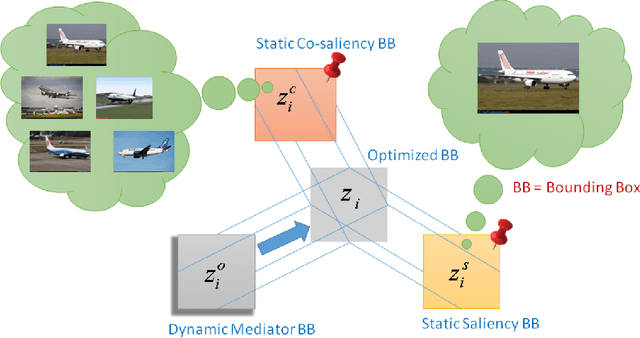
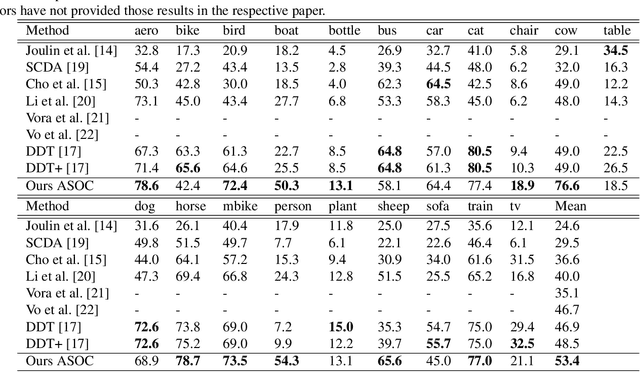

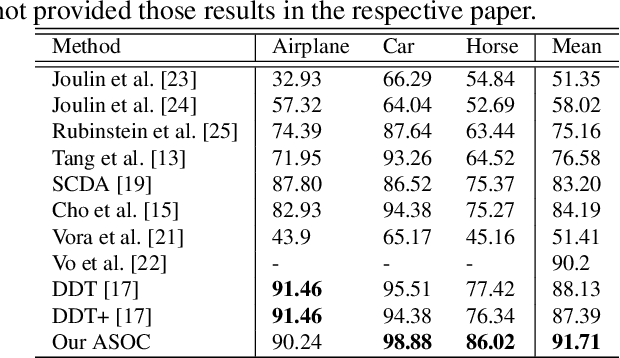
The primary goal of this paper is to localize objects in a group of semantically similar images jointly, also known as the object co-localization problem. Most related existing works are essentially weakly-supervised, relying prominently on the neighboring images' weak-supervision. Although weak supervision is beneficial, it is not entirely reliable, for the results are quite sensitive to the neighboring images considered. In this paper, we combine it with a self-awareness phenomenon to mitigate this issue. By self-awareness here, we refer to the solution derived from the image itself in the form of saliency cue, which can also be unreliable if applied alone. Nevertheless, combining these two paradigms together can lead to a better co-localization ability. Specifically, we introduce a dynamic mediator that adaptively strikes a proper balance between the two static solutions to provide an optimal solution. Therefore, we call this method \textit{ASOC}: Adaptive Self-aware Object Co-localization. We perform exhaustive experiments on several benchmark datasets and validate that weak-supervision supplemented with self-awareness has superior performance outperforming several compared competing methods.
* Published in IEEE ICME 2021. Please cite this paper in the following manner: K. R. Jerripothula and P. Mukherjee, "ASOC: Adaptive Self-Aware Object Co-Localization," 2021 IEEE International Conference on Multimedia and Expo (ICME), 2021, pp. 1-6, doi: 10.1109/ICME51207.2021.9428191
Eye-focused Detection of Bell's Palsy in Videos
Jan 27, 2022

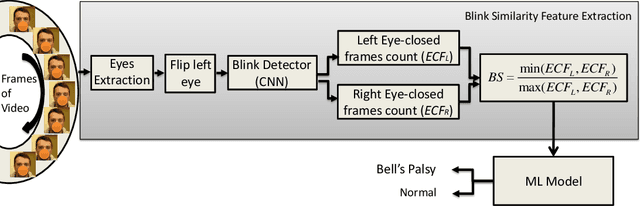

In this paper, we present how Bell's Palsy, a neurological disorder, can be detected just from a subject's eyes in a video. We notice that Bell's Palsy patients often struggle to blink their eyes on the affected side. As a result, we can observe a clear contrast between the blinking patterns of the two eyes. Although previous works did utilize images/videos to detect this disorder, none have explicitly focused on the eyes. Most of them require the entire face. One obvious advantage of having an eye-focused detection system is that subjects' anonymity is not at risk. Also, our AI decisions based on simple blinking patterns make them explainable and straightforward. Specifically, we develop a novel feature called blink similarity, which measures the similarity between the two blinking patterns. Our extensive experiments demonstrate that the proposed feature is quite robust, for it helps in Bell's Palsy detection even with very few labels. Our proposed eye-focused detection system is not only cheaper but also more convenient than several existing methods.
* Published in the Proceedings of the 34th Canadian Conference on Artificial Intelligence. Please cite this paper in the following manner: S. A. Ansari, K. R. Jerripothula, P. Nagpal, and A. Mittal. "Eye-focused Detection of Bell's Palsy in Videos". In: Proceedings of the 34th Canadian Conference on Artificial Intelligence (June 8, 2021). doi: 10.21428/594757db.d2f8342b
Detection of Gait Abnormalities caused by Neurological Disorders
Aug 16, 2020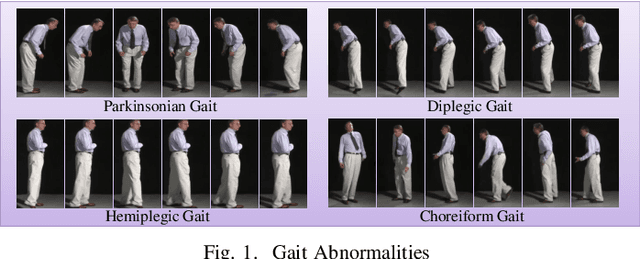

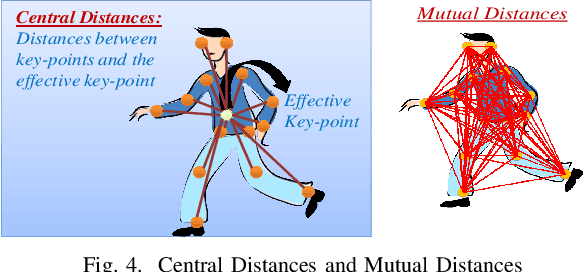

In this paper, we leverage gait to potentially detect some of the important neurological disorders, namely Parkinson's disease, Diplegia, Hemiplegia, and Huntington's Chorea. Persons with these neurological disorders often have a very abnormal gait, which motivates us to target gait for their potential detection. Some of the abnormalities involve the circumduction of legs, forward-bending, involuntary movements, etc. To detect such abnormalities in gait, we develop gait features from the key-points of the human pose, namely shoulders, elbows, hips, knees, ankles, etc. To evaluate the effectiveness of our gait features in detecting the abnormalities related to these diseases, we build a synthetic video dataset of persons mimicking the gait of persons with such disorders, considering the difficulty in finding a sufficient number of people with these disorders. We name it \textit{NeuroSynGait} video dataset. Experiments demonstrated that our gait features were indeed successful in detecting these abnormalities.
SGG: Spinbot, Grammarly and GloVe based Fake News Detection
Aug 16, 2020
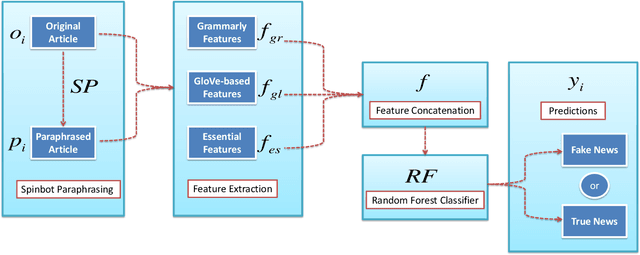

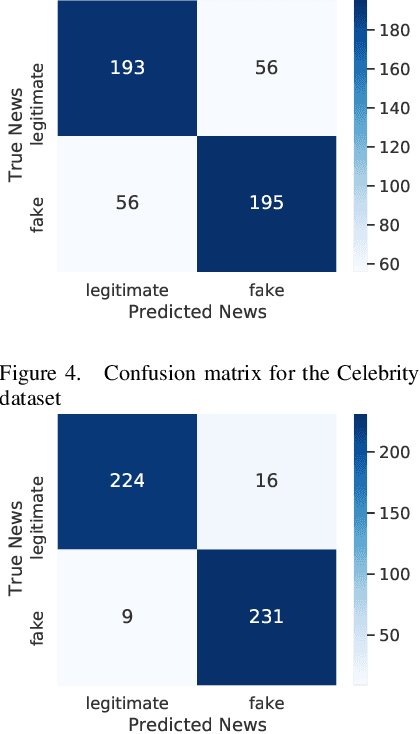
Recently, news consumption using online news portals has increased exponentially due to several reasons, such as low cost and easy accessibility. However, such online platforms inadvertently also become the cause of spreading false information across the web. They are being misused quite frequently as a medium to disseminate misinformation and hoaxes. Such malpractices call for a robust automatic fake news detection system that can keep us at bay from such misinformation and hoaxes. We propose a robust yet simple fake news detection system, leveraging the tools for paraphrasing, grammar-checking, and word-embedding. In this paper, we try to the potential of these tools in jointly unearthing the authenticity of a news article. Notably, we leverage Spinbot (for paraphrasing), Grammarly (for grammar-checking), and GloVe (for word-embedding) tools for this purpose. Using these tools, we were able to extract novel features that could yield state-of-the-art results on the Fake News AMT dataset and comparable results on Celebrity datasets when combined with some of the essential features. More importantly, the proposed method is found to be more robust empirically than the existing ones, as revealed in our cross-domain analysis and multi-domain analysis.
Feature-level Rating System using Customer Reviews and Review Votes
Jul 18, 2020
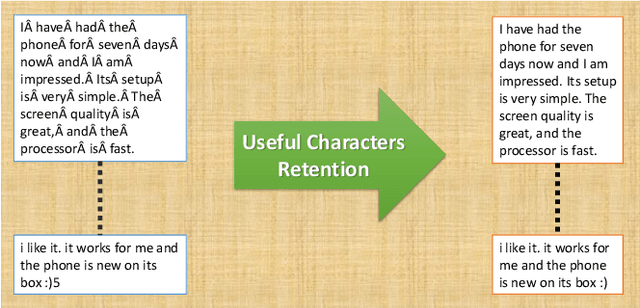


This work studies how we can obtain feature-level ratings of the mobile products from the customer reviews and review votes to influence decision making, both for new customers and manufacturers. Such a rating system gives a more comprehensive picture of the product than what a product-level rating system offers. While product-level ratings are too generic, feature-level ratings are particular; we exactly know what is good or bad about the product. There has always been a need to know which features fall short or are doing well according to the customer's perception. It keeps both the manufacturer and the customer well-informed in the decisions to make in improving the product and buying, respectively. Different customers are interested in different features. Thus, feature-level ratings can make buying decisions personalized. We analyze the customer reviews collected on an online shopping site (Amazon) about various mobile products and the review votes. Explicitly, we carry out a feature-focused sentiment analysis for this purpose. Eventually, our analysis yields ratings to 108 features for 4k+ mobiles sold online. It helps in decision making on how to improve the product (from the manufacturer's perspective) and in making the personalized buying decisions (from the buyer's perspective) a possibility. Our analysis has applications in recommender systems, consumer research, etc.
Image Co-skeletonization via Co-segmentation
Apr 12, 2020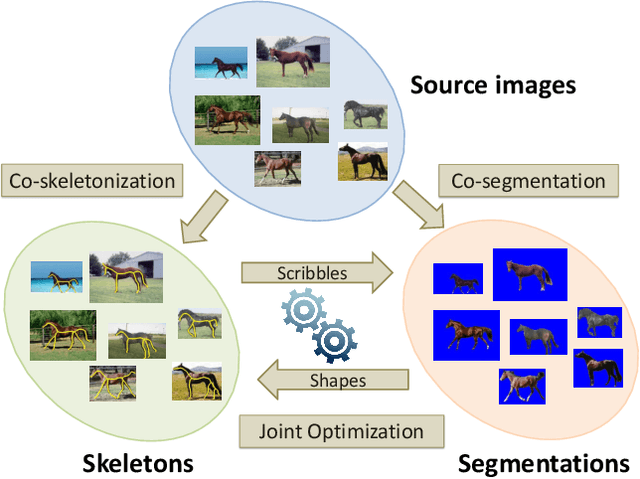

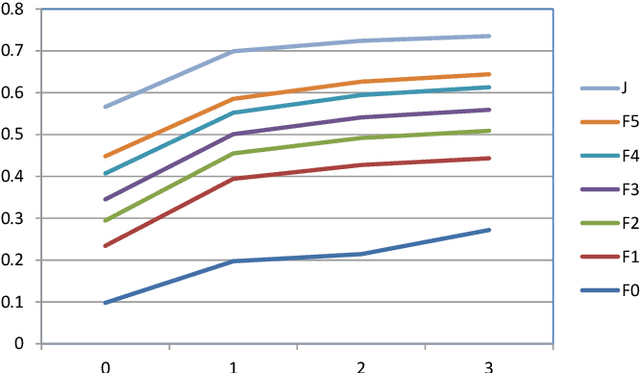

Recent advances in the joint processing of images have certainly shown its advantages over individual processing. Different from the existing works geared towards co-segmentation or co-localization, in this paper, we explore a new joint processing topic: image co-skeletonization, which is defined as joint skeleton extraction of objects in an image collection. Object skeletonization in a single natural image is a challenging problem because there is hardly any prior knowledge about the object. Therefore, we resort to the idea of object co-skeletonization, hoping that the commonness prior that exists across the images may help, just as it does for other joint processing problems such as co-segmentation. We observe that the skeleton can provide good scribbles for segmentation, and skeletonization, in turn, needs good segmentation. Therefore, we propose a coupled framework for co-skeletonization and co-segmentation tasks so that they are well informed by each other, and benefit each other synergistically. Since it is a new problem, we also construct a benchmark dataset by annotating nearly 1.8k images spread across 38 categories. Extensive experiments demonstrate that the proposed method achieves promising results in all the three possible scenarios of joint-processing: weakly-supervised, supervised, and unsupervised.