 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Vision-Language Segmentation for Medical Imaging
Feb 16, 2026We introduce a novel uncertainty-aware multimodal segmentation framework that leverages both radiological images and associated clinical text for precise medical diagnosis. We propose a Modality Decoding Attention Block (MoDAB) with a lightweight State Space Mixer (SSMix) to enable efficient cross-modal fusion and long-range dependency modelling. To guide learning under ambiguity, we propose the Spectral-Entropic Uncertainty (SEU) Loss, which jointly captures spatial overlap, spectral consistency, and predictive uncertainty in a unified objective. In complex clinical circumstances with poor image quality, this formulation improves model reliability. Extensive experiments on various publicly available medical datasets, QATA-COVID19, MosMed++, and Kvasir-SEG, demonstrate that our method achieves superior segmentation performance while being significantly more computationally efficient than existing State-of-the-Art (SoTA) approaches. Our results highlight the importance of incorporating uncertainty modelling and structured modality alignment in vision-language medical segmentation tasks. Code: https://github.com/arya-domain/UA-VLS
Efficient Text-Guided Convolutional Adapter for the Diffusion Model
Feb 16, 2026We introduce the Nexus Adapters, novel text-guided efficient adapters to the diffusion-based framework for the Structure Preserving Conditional Generation (SPCG). Recently, structure-preserving methods have achieved promising results in conditional image generation by using a base model for prompt conditioning and an adapter for structure input, such as sketches or depth maps. These approaches are highly inefficient and sometimes require equal parameters in the adapter compared to the base architecture. It is not always possible to train the model since the diffusion model is itself costly, and doubling the parameter is highly inefficient. In these approaches, the adapter is not aware of the input prompt; therefore, it is optimal only for the structural input but not for the input prompt. To overcome the above challenges, we proposed two efficient adapters, Nexus Prime and Slim, which are guided by prompts and structural inputs. Each Nexus Block incorporates cross-attention mechanisms to enable rich multimodal conditioning. Therefore, the proposed adapter has a better understanding of the input prompt while preserving the structure. We conducted extensive experiments on the proposed models and demonstrated that the Nexus Prime adapter significantly enhances performance, requiring only 8M additional parameters compared to the baseline, T2I-Adapter. Furthermore, we also introduced a lightweight Nexus Slim adapter with 18M fewer parameters than the T2I-Adapter, which still achieved state-of-the-art results. Code: https://github.com/arya-domain/Nexus-Adapters
Hyperspectral Image Land Cover Captioning Dataset for Vision Language Models
May 18, 2025We introduce HyperCap, the first large-scale hyperspectral captioning dataset designed to enhance model performance and effectiveness in remote sensing applications. Unlike traditional hyperspectral imaging (HSI) datasets that focus solely on classification tasks, HyperCap integrates spectral data with pixel-wise textual annotations, enabling deeper semantic understanding of hyperspectral imagery. This dataset enhances model performance in tasks like classification and feature extraction, providing a valuable resource for advanced remote sensing applications. HyperCap is constructed from four benchmark datasets and annotated through a hybrid approach combining automated and manual methods to ensure accuracy and consistency. Empirical evaluations using state-of-the-art encoders and diverse fusion techniques demonstrate significant improvements in classification performance. These results underscore the potential of vision-language learning in HSI and position HyperCap as a foundational dataset for future research in the field.
TD-RD: A Top-Down Benchmark with Real-Time Framework for Road Damage Detection
Jan 24, 2025



Object detection has witnessed remarkable advancements over the past decade, largely driven by breakthroughs in deep learning and the proliferation of large scale datasets. However, the domain of road damage detection remains relatively under explored, despite its critical significance for applications such as infrastructure maintenance and road safety. This paper addresses this gap by introducing a novel top down benchmark that offers a complementary perspective to existing datasets, specifically tailored for road damage detection. Our proposed Top Down Road Damage Detection Dataset (TDRD) includes three primary categories of road damage cracks, potholes, and patches captured from a top down viewpoint. The dataset consists of 7,088 high resolution images, encompassing 12,882 annotated instances of road damage. Additionally, we present a novel real time object detection framework, TDYOLOV10, designed to handle the unique challenges posed by the TDRD dataset. Comparative studies with state of the art models demonstrate competitive baseline results. By releasing TDRD, we aim to accelerate research in this crucial area. A sample of the dataset will be made publicly available upon the paper's acceptance.
Leveraging Task-Specific Knowledge from LLM for Semi-Supervised 3D Medical Image Segmentation
Jul 06, 2024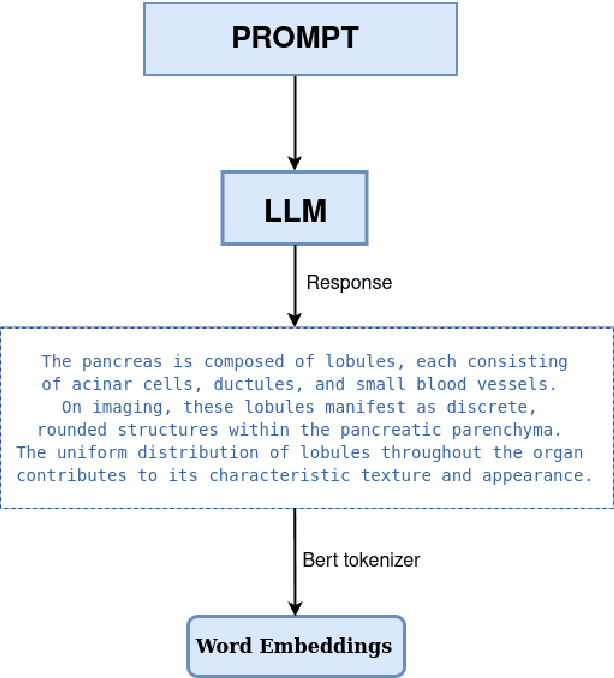
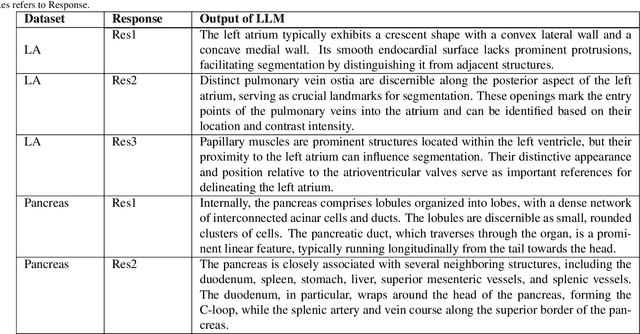
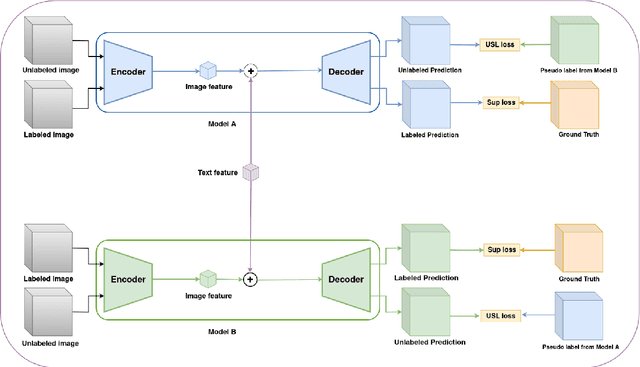
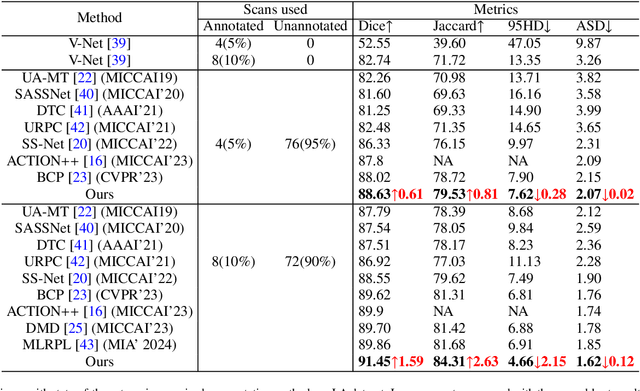
Traditional supervised 3D medical image segmentation models need voxel-level annotations, which require huge human effort, time, and cost. Semi-supervised learning (SSL) addresses this limitation of supervised learning by facilitating learning with a limited annotated and larger amount of unannotated training samples. However, state-of-the-art SSL models still struggle to fully exploit the potential of learning from unannotated samples. To facilitate effective learning from unannotated data, we introduce LLM-SegNet, which exploits a large language model (LLM) to integrate task-specific knowledge into our co-training framework. This knowledge aids the model in comprehensively understanding the features of the region of interest (ROI), ultimately leading to more efficient segmentation. Additionally, to further reduce erroneous segmentation, we propose a Unified Segmentation loss function. This loss function reduces erroneous segmentation by not only prioritizing regions where the model is confident in predicting between foreground or background pixels but also effectively addressing areas where the model lacks high confidence in predictions. Experiments on publicly available Left Atrium, Pancreas-CT, and Brats-19 datasets demonstrate the superior performance of LLM-SegNet compared to the state-of-the-art. Furthermore, we conducted several ablation studies to demonstrate the effectiveness of various modules and loss functions leveraged by LLM-SegNet.
Are Vision xLSTM Embedded UNet More Reliable in Medical 3D Image Segmentation?
Jun 24, 2024The advancement of developing efficient medical image segmentation has evolved from initial dependence on Convolutional Neural Networks (CNNs) to the present investigation of hybrid models that combine CNNs with Vision Transformers. Furthermore, there is an increasing focus on creating architectures that are both high-performing in medical image segmentation tasks and computationally efficient to be deployed on systems with limited resources. Although transformers have several advantages like capturing global dependencies in the input data, they face challenges such as high computational and memory complexity. This paper investigates the integration of CNNs and Vision Extended Long Short-Term Memory (Vision-xLSTM) models by introducing a novel approach called UVixLSTM. The Vision-xLSTM blocks captures temporal and global relationships within the patches extracted from the CNN feature maps. The convolutional feature reconstruction path upsamples the output volume from the Vision-xLSTM blocks to produce the segmentation output. Our primary objective is to propose that Vision-xLSTM forms a reliable backbone for medical image segmentation tasks, offering excellent segmentation performance and reduced computational complexity. UVixLSTM exhibits superior performance compared to state-of-the-art networks on the publicly-available Synapse dataset. Code is available at: https://github.com/duttapallabi2907/UVixLSTM
How to Learn More? Exploring Kolmogorov-Arnold Networks for Hyperspectral Image Classification
Jun 22, 2024



Convolutional Neural Networks (CNNs) and vision transformers (ViTs) have shown excellent capability in complex hyperspectral image (HSI) classification. However, these models require a significant number of training data and are computational resources. On the other hand, modern Multi-Layer Perceptrons (MLPs) have demonstrated great classification capability. These modern MLP-based models require significantly less training data compared to CNNs and ViTs, achieving the state-of-the-art classification accuracy. Recently, Kolmogorov-Arnold Networks (KANs) were proposed as viable alternatives for MLPs. Because of their internal similarity to splines and their external similarity to MLPs, KANs are able to optimize learned features with remarkable accuracy in addition to being able to learn new features. Thus, in this study, we assess the effectiveness of KANs for complex HSI data classification. Moreover, to enhance the HSI classification accuracy obtained by the KANs, we develop and propose a Hybrid architecture utilizing 1D, 2D, and 3D KANs. To demonstrate the effectiveness of the proposed KAN architecture, we conducted extensive experiments on three newly created HSI benchmark datasets: QUH-Pingan, QUH-Tangdaowan, and QUH-Qingyun. The results underscored the competitive or better capability of the developed hybrid KAN-based model across these benchmark datasets over several other CNN- and ViT-based algorithms, including 1D-CNN, 2DCNN, 3D CNN, VGG-16, ResNet-50, EfficientNet, RNN, and ViT. The code are publicly available at (https://github.com/aj1365/HSIConvKAN)
Multi-dimension Transformer with Attention-based Filtering for Medical Image Segmentation
May 20, 2024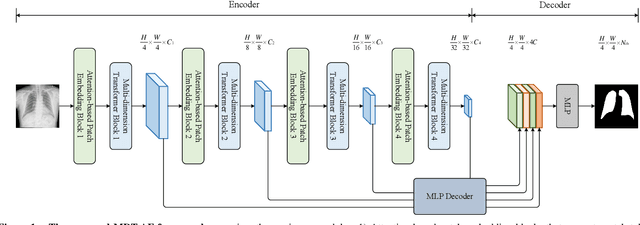
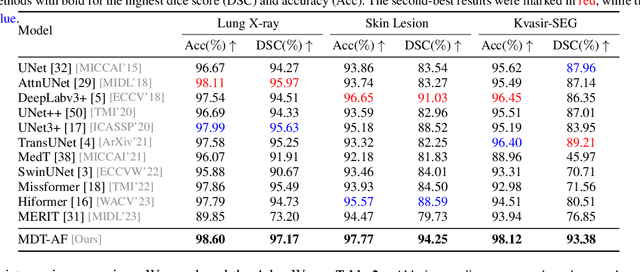
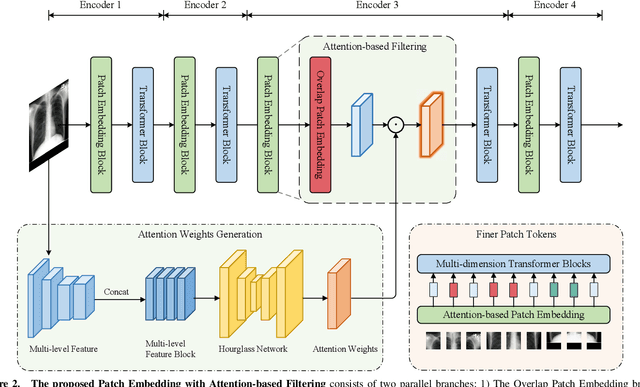
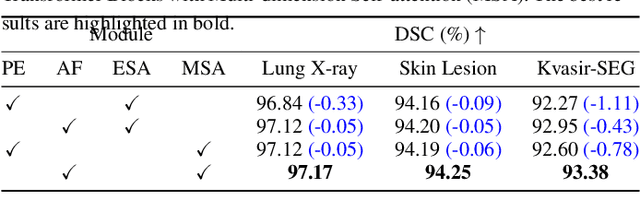
The accurate segmentation of medical images is crucial for diagnosing and treating diseases. Recent studies demonstrate that vision transformer-based methods have significantly improved performance in medical image segmentation, primarily due to their superior ability to establish global relationships among features and adaptability to various inputs. However, these methods struggle with the low signal-to-noise ratio inherent to medical images. Additionally, the effective utilization of channel and spatial information, which are essential for medical image segmentation, is limited by the representation capacity of self-attention. To address these challenges, we propose a multi-dimension transformer with attention-based filtering (MDT-AF), which redesigns the patch embedding and self-attention mechanism for medical image segmentation. MDT-AF incorporates an attention-based feature filtering mechanism into the patch embedding blocks and employs a coarse-to-fine process to mitigate the impact of low signal-to-noise ratio. To better capture complex structures in medical images, MDT-AF extends the self-attention mechanism to incorporate spatial and channel dimensions, enriching feature representation. Moreover, we introduce an interaction mechanism to improve the feature aggregation between spatial and channel dimensions. Experimental results on three public medical image segmentation benchmarks show that MDT-AF achieves state-of-the-art (SOTA) performance.
Reliable or Deceptive? Investigating Gated Features for Smooth Visual Explanations in CNNs
Apr 30, 2024Deep learning models have achieved remarkable success across diverse domains. However, the intricate nature of these models often impedes a clear understanding of their decision-making processes. This is where Explainable AI (XAI) becomes indispensable, offering intuitive explanations for model decisions. In this work, we propose a simple yet highly effective approach, ScoreCAM++, which introduces modifications to enhance the promising ScoreCAM method for visual explainability. Our proposed approach involves altering the normalization function within the activation layer utilized in ScoreCAM, resulting in significantly improved results compared to previous efforts. Additionally, we apply an activation function to the upsampled activation layers to enhance interpretability. This improvement is achieved by selectively gating lower-priority values within the activation layer. Through extensive experiments and qualitative comparisons, we demonstrate that ScoreCAM++ consistently achieves notably superior performance and fairness in interpreting the decision-making process compared to both ScoreCAM and previous methods.
GLFNET: Global-Local (frequency) Filter Networks for efficient medical image segmentation
Mar 01, 2024



We propose a novel transformer-style architecture called Global-Local Filter Network (GLFNet) for medical image segmentation and demonstrate its state-of-the-art performance. We replace the self-attention mechanism with a combination of global-local filter blocks to optimize model efficiency. The global filters extract features from the whole feature map whereas the local filters are being adaptively created as 4x4 patches of the same feature map and add restricted scale information. In particular, the feature extraction takes place in the frequency domain rather than the commonly used spatial (image) domain to facilitate faster computations. The fusion of information from both spatial and frequency spaces creates an efficient model with regards to complexity, required data and performance. We test GLFNet on three benchmark datasets achieving state-of-the-art performance on all of them while being almost twice as efficient in terms of GFLOP operations.