 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpochX: Building the Infrastructure for an Emergent Agent Civilization
Mar 28, 2026General-purpose technologies reshape economies less by improving individual tools than by enabling new ways to organize production and coordination. We believe AI agents are approaching a similar inflection point: as foundation models make broad task execution and tool use increasingly accessible, the binding constraint shifts from raw capability to how work is delegated, verified, and rewarded at scale. We introduce EpochX, a credits-native marketplace infrastructure for human-agent production networks. EpochX treats humans and agents as peer participants who can post tasks or claim them. Claimed tasks can be decomposed into subtasks and executed through an explicit delivery workflow with verification and acceptance. Crucially, EpochX is designed so that each completed transaction can produce reusable ecosystem assets, including skills, workflows, execution traces, and distilled experience. These assets are stored with explicit dependency structure, enabling retrieval, composition, and cumulative improvement over time. EpochX also introduces a native credit mechanism to make participation economically viable under real compute costs. Credits lock task bounties, budget delegation, settle rewards upon acceptance, and compensate creators when verified assets are reused. By formalizing the end-to-end transaction model together with its asset and incentive layers, EpochX reframes agentic AI as an organizational design problem: building infrastructures where verifiable work leaves persistent, reusable artifacts, and where value flows support durable human-agent collaboration.
Learnable Instance Attention Filtering for Adaptive Detector Distillation
Mar 27, 2026As deep vision models grow increasingly complex to achieve higher performance, deployment efficiency has become a critical concern. Knowledge distillation (KD) mitigates this issue by transferring knowledge from large teacher models to compact student models. While many feature-based KD methods rely on spatial filtering to guide distillation, they typically treat all object instances uniformly, ignoring instance-level variability. Moreover, existing attention filtering mechanisms are typically heuristic or teacher-driven, rather than learned with the student. To address these limitations, we propose Learnable Instance Attention Filtering for Adaptive Detector Distillation (LIAF-KD), a novel framework that introduces learnable instance selectors to dynamically evaluate and reweight instance importance during distillation. Notably, the student contributes to this process based on its evolving learning state. Experiments on the KITTI and COCO datasets demonstrate consistent improvements, with a 2% gain on a GFL ResNet-50 student without added complexity, outperforming state-of-the-art methods.
From Performance to Practice: Knowledge-Distilled Segmentator for On-Premises Clinical Workflows
Jan 14, 2026Deploying medical image segmentation models in routine clinical workflows is often constrained by on-premises infrastructure, where computational resources are fixed and cloud-based inference may be restricted by governance and security policies. While high-capacity models achieve strong segmentation accuracy, their computational demands hinder practical deployment and long-term maintainability in hospital environments. We present a deployment-oriented framework that leverages knowledge distillation to translate a high-performing segmentation model into a scalable family of compact student models, without modifying the inference pipeline. The proposed approach preserves architectural compatibility with existing clinical systems while enabling systematic capacity reduction. The framework is evaluated on a multi-site brain MRI dataset comprising 1,104 3D volumes, with independent testing on 101 curated cases, and is further examined on abdominal CT to assess cross-modality generalizability. Under aggressive parameter reduction (94%), the distilled student model preserves nearly all of the teacher's segmentation accuracy (98.7%), while achieving substantial efficiency gains, including up to a 67% reduction in CPU inference latency without additional deployment overhead. These results demonstrate that knowledge distillation provides a practical and reliable pathway for converting research-grade segmentation models into maintainable, deployment-ready components for on-premises clinical workflows in real-world health systems.
ReCo-KD: Region- and Context-Aware Knowledge Distillation for Efficient 3D Medical Image Segmentation
Jan 13, 2026Accurate 3D medical image segmentation is vital for diagnosis and treatment planning, but state-of-the-art models are often too large for clinics with limited computing resources. Lightweight architectures typically suffer significant performance loss. To address these deployment and speed constraints, we propose Region- and Context-aware Knowledge Distillation (ReCo-KD), a training-only framework that transfers both fine-grained anatomical detail and long-range contextual information from a high-capacity teacher to a compact student network. The framework integrates Multi-Scale Structure-Aware Region Distillation (MS-SARD), which applies class-aware masks and scale-normalized weighting to emphasize small but clinically important regions, and Multi-Scale Context Alignment (MS-CA), which aligns teacher-student affinity patterns across feature levels. Implemented on nnU-Net in a backbone-agnostic manner, ReCo-KD requires no custom student design and is easily adapted to other architectures. Experiments on multiple public 3D medical segmentation datasets and a challenging aggregated dataset show that the distilled lightweight model attains accuracy close to the teacher while markedly reducing parameters and inference latency, underscoring its practicality for clinical deployment.
KnowMe-Bench: Benchmarking Person Understanding for Lifelong Digital Companions
Jan 08, 2026Existing long-horizon memory benchmarks mostly use multi-turn dialogues or synthetic user histories, which makes retrieval performance an imperfect proxy for person understanding. We present \BenchName, a publicly releasable benchmark built from long-form autobiographical narratives, where actions, context, and inner thoughts provide dense evidence for inferring stable motivations and decision principles. \BenchName~reconstructs each narrative into a flashback-aware, time-anchored stream and evaluates models with evidence-linked questions spanning factual recall, subjective state attribution, and principle-level reasoning. Across diverse narrative sources, retrieval-augmented systems mainly improve factual accuracy, while errors persist on temporally grounded explanations and higher-level inferences, highlighting the need for memory mechanisms beyond retrieval. Our data is in \href{KnowMeBench}{https://github.com/QuantaAlpha/KnowMeBench}.
ComfySearch: Autonomous Exploration and Reasoning for ComfyUI Workflows
Jan 07, 2026AI-generated content has progressed from monolithic models to modular workflows, especially on platforms like ComfyUI, allowing users to customize complex creative pipelines. However, the large number of components in ComfyUI and the difficulty of maintaining long-horizon structural consistency under strict graph constraints frequently lead to low pass rates and workflows of limited quality. To tackle these limitations, we present ComfySearch, an agentic framework that can effectively explore the component space and generate functional ComfyUI pipelines via validation-guided workflow construction. Experiments demonstrate that ComfySearch substantially outperforms existing methods on complex and creative tasks, achieving higher executability (pass) rates, higher solution rates, and stronger generalization.
Fed-SE: Federated Self-Evolution for Privacy-Constrained Multi-Environment LLM Agents
Dec 09, 2025LLM agents are widely deployed in complex interactive tasks, yet privacy constraints often preclude centralized optimization and co-evolution across dynamic environments. While Federated Learning (FL) has proven effective on static datasets, its extension to the open-ended self-evolution of agents remains underexplored. Directly applying standard FL is challenging: heterogeneous tasks and sparse, trajectory-level rewards introduce severe gradient conflicts, destabilizing the global optimization process. To bridge this gap, we propose Fed-SE, a Federated Self-Evolution framework for LLM agents. Fed-SE establishes a local evolution-global aggregation paradigm. Locally, agents employ parameter-efficient fine-tuning on filtered, high-return trajectories to achieve stable gradient updates. Globally, Fed-SE aggregates updates within a low-rank subspace that disentangles environment-specific dynamics, effectively reducing negative transfer across clients. Experiments across five heterogeneous environments demonstrate that Fed-SE improves average task success rates by approximately 18% over federated baselines, validating its effectiveness in robust cross-environment knowledge transfer in privacy-constrained deployments.
ETT-CKGE: Efficient Task-driven Tokens for Continual Knowledge Graph Embedding
Jun 09, 2025Continual Knowledge Graph Embedding (CKGE) seeks to integrate new knowledge while preserving past information. However, existing methods struggle with efficiency and scalability due to two key limitations: (1) suboptimal knowledge preservation between snapshots caused by manually designed node/relation importance scores that ignore graph dependencies relevant to the downstream task, and (2) computationally expensive graph traversal for node/relation importance calculation, leading to slow training and high memory overhead. To address these limitations, we introduce ETT-CKGE (Efficient, Task-driven, Tokens for Continual Knowledge Graph Embedding), a novel task-guided CKGE method that leverages efficient task-driven tokens for efficient and effective knowledge transfer between snapshots. Our method introduces a set of learnable tokens that directly capture task-relevant signals, eliminating the need for explicit node scoring or traversal. These tokens serve as consistent and reusable guidance across snapshots, enabling efficient token-masked embedding alignment between snapshots. Importantly, knowledge transfer is achieved through simple matrix operations, significantly reducing training time and memory usage. Extensive experiments across six benchmark datasets demonstrate that ETT-CKGE consistently achieves superior or competitive predictive performance, while substantially improving training efficiency and scalability compared to state-of-the-art CKGE methods. The code is available at: https://github.com/lijingzhu1/ETT-CKGE/tree/main
ACAM-KD: Adaptive and Cooperative Attention Masking for Knowledge Distillation
Mar 08, 2025



Dense visual prediction tasks, such as detection and segmentation, are crucial for time-critical applications (e.g., autonomous driving and video surveillance). While deep models achieve strong performance, their efficiency remains a challenge. Knowledge distillation (KD) is an effective model compression technique, but existing feature-based KD methods rely on static, teacher-driven feature selection, failing to adapt to the student's evolving learning state or leverage dynamic student-teacher interactions. To address these limitations, we propose Adaptive student-teacher Cooperative Attention Masking for Knowledge Distillation (ACAM-KD), which introduces two key components: (1) Student-Teacher Cross-Attention Feature Fusion (STCA-FF), which adaptively integrates features from both models for a more interactive distillation process, and (2) Adaptive Spatial-Channel Masking (ASCM), which dynamically generates importance masks to enhance both spatial and channel-wise feature selection. Unlike conventional KD methods, ACAM-KD adapts to the student's evolving needs throughout the entire distillation process. Extensive experiments on multiple benchmarks validate its effectiveness. For instance, on COCO2017, ACAM-KD improves object detection performance by up to 1.4 mAP over the state-of-the-art when distilling a ResNet-50 student from a ResNet-101 teacher. For semantic segmentation on Cityscapes, it boosts mIoU by 3.09 over the baseline with DeepLabV3-MobileNetV2 as the student model.
Multi-dimension Transformer with Attention-based Filtering for Medical Image Segmentation
May 20, 2024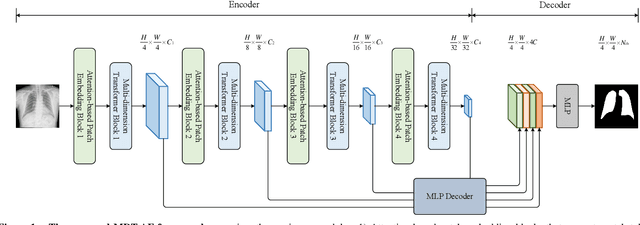
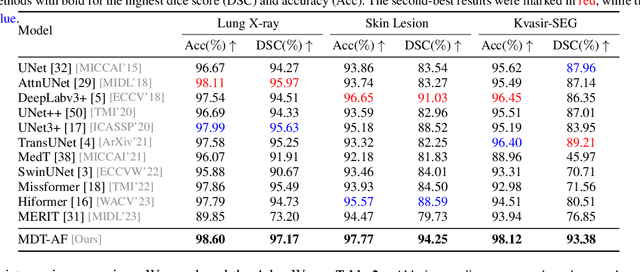
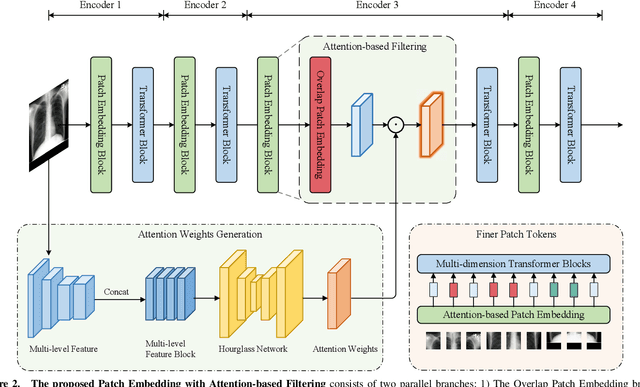
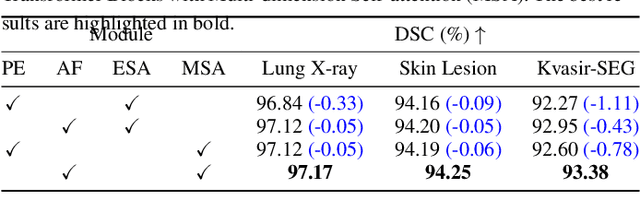
The accurate segmentation of medical images is crucial for diagnosing and treating diseases. Recent studies demonstrate that vision transformer-based methods have significantly improved performance in medical image segmentation, primarily due to their superior ability to establish global relationships among features and adaptability to various inputs. However, these methods struggle with the low signal-to-noise ratio inherent to medical images. Additionally, the effective utilization of channel and spatial information, which are essential for medical image segmentation, is limited by the representation capacity of self-attention. To address these challenges, we propose a multi-dimension transformer with attention-based filtering (MDT-AF), which redesigns the patch embedding and self-attention mechanism for medical image segmentation. MDT-AF incorporates an attention-based feature filtering mechanism into the patch embedding blocks and employs a coarse-to-fine process to mitigate the impact of low signal-to-noise ratio. To better capture complex structures in medical images, MDT-AF extends the self-attention mechanism to incorporate spatial and channel dimensions, enriching feature representation. Moreover, we introduce an interaction mechanism to improve the feature aggregation between spatial and channel dimensions. Experimental results on three public medical image segmentation benchmarks show that MDT-AF achieves state-of-the-art (SOTA) performance.