 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubspace Control: Turning Constrained Model Steering into Controllable Spectral Optimization
Apr 05, 2026Foundation models, such as large language models (LLMs), are powerful but often require customization before deployment to satisfy practical constraints such as safety, privacy, and task-specific requirements, leading to "constrained" optimization problems for model steering and adaptation. However, solving such problems remains largely underexplored and is particularly challenging due to interference between the primary objective and constraint objectives during optimization. In this paper, we propose a subspace control framework for constrained model training. Specifically, (i) we first analyze, from a model merging perspective, how spectral cross-task interference arises and show that it can be resolved via a one-shot solution that orthogonalizes the merged subspace; (ii) we establish a connection between this solution and gradient orthogonalization in the spectral optimizer Muon; and (iii) building on these insights, we introduce SIFT (spectral interference-free training), which leverages a localization scheme to selectively intervene during optimization, enabling controllable updates that mitigate objective-constraint conflicts. We evaluate SIFT across four representative applications: (a) machine unlearning, (b) safety alignment, (c) text-to-speech adaptation, and (d) hallucination mitigation. Compared to both control-based and control-free baselines, SIFT consistently achieves substantial and robust performance improvements across all tasks. Code is available at https://github.com/OPTML-Group/SIFT.
Differentiable Initialization-Accelerated CPU-GPU Hybrid Combinatorial Scheduling
Mar 30, 2026This paper presents a hybrid CPU-GPU framework for solving combinatorial scheduling problems formulated as Integer Linear Programming (ILP). While scheduling underpins many optimization tasks in computing systems, solving these problems optimally at scale remains a long-standing challenge due to their NP-hard nature. We introduce a novel approach that combines differentiable optimization with classical ILP solving. Specifically, we utilize differentiable presolving to rapidly generate high-quality partial solutions, which serve as warm-starts for commercial ILP solvers (CPLEX, Gurobi) and rising open-source solver HiGHS. This method enables significantly improved early pruning compared to state-of-the-art standalone solvers. Empirical results across industry-scale benchmarks demonstrate up to a $10\times$ performance gain over baselines, narrowing the optimality gap to $<0.1\%$. This work represents the first demonstration of utilizing differentiable optimization to initialize exact ILP solvers for combinatorial scheduling, opening new opportunities to integrate machine learning infrastructure with classical exact optimization methods across broader domains.
GaloisSAT: Differentiable Boolean Satisfiability Solving via Finite Field Algebra
Mar 25, 2026Boolean satisfiability (SAT) problem, the first problem proven to be NP-complete, has become a fundamental challenge in computational complexity, with widespread applications in optimization and verification across many domains. Despite significant algorithmic advances over the past two decades, the performance of SAT solvers has improved at a limited pace. Notably, the 2025 competition winner shows only about a 2X improvement over the 2006 winner in SAT Competition performance after nearly 20 years of effort. This paper introduces GaloisSAT, a novel hybrid GPU-CPU SAT solver that integrates a differentiable SAT solving engine powered by modern machine learning infrastructure on GPUs, followed by a traditional CDCL-based SAT solving stage on CPUs. GaloisSAT is benchmarked against the latest versions of state-of-the-art solvers, Kissat and CaDiCaL, using the SAT Competition 2024 benchmark suite. Results demonstrate substantial improvements in the official SAT Competition metric PAR-2 (penalized average runtime with a timeout of 5,000 seconds and a penalty factor of 2). Specifically, GaloisSAT achieves an 8.41X speedup in the satisfiable category and a 1.29X speedup in the unsatisfiable category compared to the strongest baselines.
HIPO: Instruction Hierarchy via Constrained Reinforcement Learning
Mar 17, 2026Hierarchical Instruction Following (HIF) refers to the problem of prompting large language models with a priority-ordered stack of instructions. Standard methods like RLHF and DPO typically fail in this problem since they mainly optimize for a single objective, failing to explicitly enforce system prompt compliance. Meanwhile, supervised fine-tuning relies on mimicking filtered, compliant data, which fails to establish the priority asymmetry at the algorithmic level. In this paper, we introduce \textsc{HIPO}, a novel alignment framework that formulates HIF as a Constrained Markov Decision Process. \textsc{HIPO} elevates system prompts from mere input context to strict algorithmic boundaries. Using a primal-dual safe reinforcement learning approach, the algorithm dynamically enforces system prompt compliance as an explicit constraint, maximizing user utility strictly within this feasible region. Extensive evaluations across diverse model architectures (e.g., Qwen, Phi, Llama) demonstrate that \textsc{HIPO} significantly improves both system compliance and user utility. Furthermore, mechanistic analysis reveals that this constrained optimization autonomously drives the model to shift its attention toward long-range system tokens, providing a principled foundation for reliable LLM deployment in complex workflows.
Active Causal Experimentalist (ACE): Learning Intervention Strategies via Direct Preference Optimization
Feb 02, 2026Discovering causal relationships requires controlled experiments, but experimentalists face a sequential decision problem: each intervention reveals information that should inform what to try next. Traditional approaches such as random sampling, greedy information maximization, and round-robin coverage treat each decision in isolation, unable to learn adaptive strategies from experience. We propose Active Causal Experimentalist (ACE), which learns experimental design as a sequential policy. Our key insight is that while absolute information gains diminish as knowledge accumulates (making value-based RL unstable), relative comparisons between candidate interventions remain meaningful throughout. ACE exploits this via Direct Preference Optimization, learning from pairwise intervention comparisons rather than non-stationary reward magnitudes. Across synthetic benchmarks, physics simulations, and economic data, ACE achieves 70-71% improvement over baselines at equal intervention budgets (p < 0.001, Cohen's d ~ 2). Notably, the learned policy autonomously discovers that collider mechanisms require concentrated interventions on parent variables, a theoretically-grounded strategy that emerges purely from experience. This suggests preference-based learning can recover principled experimental strategies, complementing theory with learned domain adaptation.
Search-Augmented Masked Diffusion Models for Constrained Generation
Feb 02, 2026Discrete diffusion models generate sequences by iteratively denoising samples corrupted by categorical noise, offering an appealing alternative to autoregressive decoding for structured and symbolic generation. However, standard training targets a likelihood-based objective that primarily matches the data distribution and provides no native mechanism for enforcing hard constraints or optimizing non-differentiable properties at inference time. This work addresses this limitation and introduces Search-Augmented Masked Diffusion (SearchDiff), a training-free neurosymbolic inference framework that integrates informed search directly into the reverse denoising process. At each denoising step, the model predictions define a proposal set that is optimized under a user-specified property satisfaction, yielding a modified reverse transition that steers sampling toward probable and feasible solutions. Experiments in biological design and symbolic reasoning illustrate that SearchDiff substantially improves constraint satisfaction and property adherence, while consistently outperforming discrete diffusion and autoregressive baselines.
Monotonicity as an Architectural Bias for Robust Language Models
Feb 02, 2026Large language models (LLMs) are known to exhibit brittle behavior under adversarial prompts and jailbreak attacks, even after extensive alignment and fine-tuning. This fragility reflects a broader challenge of modern neural language models: small, carefully structured perturbations in high-dimensional input spaces can induce large and unpredictable changes in internal semantic representations and output. We investigate monotonicity as an architectural inductive bias for improving the robustness of Transformer-based language models. Monotonicity constrains semantic transformations so that strengthening information, evidence, or constraints cannot lead to regressions in the corresponding internal representations. Such order-preserving behavior has long been exploited in control and safety-critical systems to simplify reasoning and improve robustness, but has traditionally been viewed as incompatible with the expressivity required by neural language models. We show that this trade-off is not inherent. By enforcing monotonicity selectively in the feed-forward sublayers of sequence-to-sequence Transformers -- while leaving attention mechanisms unconstrained -- we obtain monotone language models that preserve the performance of their pretrained counterparts. This architectural separation allows negation, contradiction, and contextual interactions to be introduced explicitly through attention, while ensuring that subsequent semantic refinement is order-preserving. Empirically, monotonicity substantially improves robustness: adversarial attack success rates drop from approximately 69% to 19%, while standard summarization performance degrades only marginally.
Neurosymbolic LoRA: Why and When to Tune Weights vs. Rewrite Prompts
Jan 19, 2026Large language models (LLMs) can be adapted either through numerical updates that alter model parameters or symbolic manipulations that work on discrete prompts or logical constraints. While numerical fine-tuning excels at injecting new factual knowledge, symbolic updates offer flexible control of style and alignment without retraining. We introduce a neurosymbolic LoRA framework that dynamically combines these two complementary strategies. Specifically, we present a unified monitoring signal and a reward-based classifier to decide when to employ LoRA for deeper factual reconstruction and when to apply TextGrad for token-level edits. Our approach remains memory-efficient by offloading the symbolic transformations to an external LLM only when needed. Additionally, the refined prompts produced during symbolic editing serve as high-quality, reusable training data, an important benefit in data-scarce domains like mathematical reasoning. Extensive experiments across multiple LLM backbones show that neurosymbolic LoRA consistently outperforms purely numerical or purely symbolic baselines, demonstrating superior adaptability and improved performance. Our findings highlight the value of interleaving numerical and symbolic updates to unlock a new level of versatility in language model fine-tuning.
On the Dataless Training of Neural Networks
Oct 29, 2025This paper surveys studies on the use of neural networks for optimization in the training-data-free setting. Specifically, we examine the dataless application of neural network architectures in optimization by re-parameterizing problems using fully connected (or MLP), convolutional, graph, and quadratic neural networks. Although MLPs have been used to solve linear programs a few decades ago, this approach has recently gained increasing attention due to its promising results across diverse applications, including those based on combinatorial optimization, inverse problems, and partial differential equations. The motivation for this setting stems from two key (possibly over-lapping) factors: (i) data-driven learning approaches are still underdeveloped and have yet to demonstrate strong results, as seen in combinatorial optimization, and (ii) the availability of training data is inherently limited, such as in medical image reconstruction and other scientific applications. In this paper, we define the dataless setting and categorize it into two variants based on how a problem instance -- defined by a single datum -- is encoded onto the neural network: (i) architecture-agnostic methods and (ii) architecture-specific methods. Additionally, we discuss similarities and clarify distinctions between the dataless neural network (dNN) settings and related concepts such as zero-shot learning, one-shot learning, lifting in optimization, and over-parameterization.
Neuro-Symbolic AI for Cybersecurity: State of the Art, Challenges, and Opportunities
Sep 08, 2025
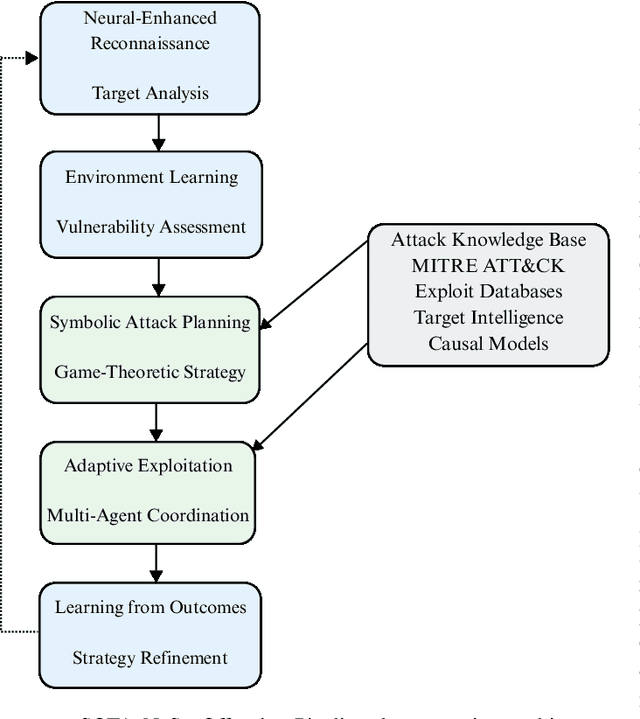


Traditional Artificial Intelligence (AI) approaches in cybersecurity exhibit fundamental limitations: inadequate conceptual grounding leading to non-robustness against novel attacks; limited instructibility impeding analyst-guided adaptation; and misalignment with cybersecurity objectives. Neuro-Symbolic (NeSy) AI has emerged with the potential to revolutionize cybersecurity AI. However, there is no systematic understanding of this emerging approach. These hybrid systems address critical cybersecurity challenges by combining neural pattern recognition with symbolic reasoning, enabling enhanced threat understanding while introducing concerning autonomous offensive capabilities that reshape threat landscapes. In this survey, we systematically characterize this field by analyzing 127 publications spanning 2019-July 2025. We introduce a Grounding-Instructibility-Alignment (G-I-A) framework to evaluate these systems, focusing on both cyber defense and cyber offense across network security, malware analysis, and cyber operations. Our analysis shows advantages of multi-agent NeSy architectures and identifies critical implementation challenges including standardization gaps, computational complexity, and human-AI collaboration requirements that constrain deployment. We show that causal reasoning integration is the most transformative advancement, enabling proactive defense beyond correlation-based approaches. Our findings highlight dual-use implications where autonomous systems demonstrate substantial capabilities in zero-day exploitation while achieving significant cost reductions, altering threat dynamics. We provide insights and future research directions, emphasizing the urgent need for community-driven standardization frameworks and responsible development practices that ensure advancement serves defensive cybersecurity objectives while maintaining societal alignment.