 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Token Attacks Cannot Reliably Audit Unlearning in Large Language Models
Feb 20, 2025Large language models (LLMs) have become increasingly popular. Their emergent capabilities can be attributed to their massive training datasets. However, these datasets often contain undesirable or inappropriate content, e.g., harmful texts, personal information, and copyrighted material. This has promoted research into machine unlearning that aims to remove information from trained models. In particular, approximate unlearning seeks to achieve information removal by strategically editing the model rather than complete model retraining. Recent work has shown that soft token attacks (STA) can successfully extract purportedly unlearned information from LLMs, thereby exposing limitations in current unlearning methodologies. In this work, we reveal that STAs are an inadequate tool for auditing unlearning. Through systematic evaluation on common unlearning benchmarks (Who Is Harry Potter? and TOFU), we demonstrate that such attacks can elicit any information from the LLM, regardless of (1) the deployed unlearning algorithm, and (2) whether the queried content was originally present in the training corpus. Furthermore, we show that STA with just a few soft tokens (1-10) can elicit random strings over 400-characters long. Thus showing that STAs are too powerful, and misrepresent the effectiveness of the unlearning methods. Our work highlights the need for better evaluation baselines, and more appropriate auditing tools for assessing the effectiveness of unlearning in LLMs.
LATTEO: A Framework to Support Learning Asynchronously Tempered with Trusted Execution and Obfuscation
Feb 07, 2025The privacy vulnerabilities of the federated learning (FL) paradigm, primarily caused by gradient leakage, have prompted the development of various defensive measures. Nonetheless, these solutions have predominantly been crafted for and assessed in the context of synchronous FL systems, with minimal focus on asynchronous FL. This gap arises in part due to the unique challenges posed by the asynchronous setting, such as the lack of coordinated updates, increased variability in client participation, and the potential for more severe privacy risks. These concerns have stymied the adoption of asynchronous FL. In this work, we first demonstrate the privacy vulnerabilities of asynchronous FL through a novel data reconstruction attack that exploits gradient updates to recover sensitive client data. To address these vulnerabilities, we propose a privacy-preserving framework that combines a gradient obfuscation mechanism with Trusted Execution Environments (TEEs) for secure asynchronous FL aggregation at the network edge. To overcome the limitations of conventional enclave attestation, we introduce a novel data-centric attestation mechanism based on Multi-Authority Attribute-Based Encryption. This mechanism enables clients to implicitly verify TEE-based aggregation services, effectively handle on-demand client participation, and scale seamlessly with an increasing number of asynchronous connections. Our gradient obfuscation mechanism reduces the structural similarity index of data reconstruction by 85% and increases reconstruction error by 400%, while our framework improves attestation efficiency by lowering average latency by up to 1500% compared to RA-TLS, without additional overhead.
Imperceptible Adversarial Examples in the Physical World
Nov 25, 2024



Adversarial examples in the digital domain against deep learning-based computer vision models allow for perturbations that are imperceptible to human eyes. However, producing similar adversarial examples in the physical world has been difficult due to the non-differentiable image distortion functions in visual sensing systems. The existing algorithms for generating physically realizable adversarial examples often loosen their definition of adversarial examples by allowing unbounded perturbations, resulting in obvious or even strange visual patterns. In this work, we make adversarial examples imperceptible in the physical world using a straight-through estimator (STE, a.k.a. BPDA). We employ STE to overcome the non-differentiability -- applying exact, non-differentiable distortions in the forward pass of the backpropagation step, and using the identity function in the backward pass. Our differentiable rendering extension to STE also enables imperceptible adversarial patches in the physical world. Using printout photos, and experiments in the CARLA simulator, we show that STE enables fast generation of $\ell_\infty$ bounded adversarial examples despite the non-differentiable distortions. To the best of our knowledge, this is the first work demonstrating imperceptible adversarial examples bounded by small $\ell_\infty$ norms in the physical world that force zero classification accuracy in the global perturbation threat model and cause near-zero ($4.22\%$) AP50 in object detection in the patch perturbation threat model. We urge the community to re-evaluate the threat of adversarial examples in the physical world.
Buffer-based Gradient Projection for Continual Federated Learning
Sep 03, 2024Continual Federated Learning (CFL) is essential for enabling real-world applications where multiple decentralized clients adaptively learn from continuous data streams. A significant challenge in CFL is mitigating catastrophic forgetting, where models lose previously acquired knowledge when learning new information. Existing approaches often face difficulties due to the constraints of device storage capacities and the heterogeneous nature of data distributions among clients. While some CFL algorithms have addressed these challenges, they frequently rely on unrealistic assumptions about the availability of task boundaries (i.e., knowing when new tasks begin). To address these limitations, we introduce Fed-A-GEM, a federated adaptation of the A-GEM method (Chaudhry et al., 2019), which employs a buffer-based gradient projection approach. Fed-A-GEM alleviates catastrophic forgetting by leveraging local buffer samples and aggregated buffer gradients, thus preserving knowledge across multiple clients. Our method is combined with existing CFL techniques, enhancing their performance in the CFL context. Our experiments on standard benchmarks show consistent performance improvements across diverse scenarios. For example, in a task-incremental learning scenario using the CIFAR-100 dataset, our method can increase the accuracy by up to 27%. Our code is available at https://github.com/shenghongdai/Fed-A-GEM.
Distributed Training of Large Graph Neural Networks with Variable Communication Rates
Jun 25, 2024Training Graph Neural Networks (GNNs) on large graphs presents unique challenges due to the large memory and computing requirements. Distributed GNN training, where the graph is partitioned across multiple machines, is a common approach to training GNNs on large graphs. However, as the graph cannot generally be decomposed into small non-interacting components, data communication between the training machines quickly limits training speeds. Compressing the communicated node activations by a fixed amount improves the training speeds, but lowers the accuracy of the trained GNN. In this paper, we introduce a variable compression scheme for reducing the communication volume in distributed GNN training without compromising the accuracy of the learned model. Based on our theoretical analysis, we derive a variable compression method that converges to a solution equivalent to the full communication case, for all graph partitioning schemes. Our empirical results show that our method attains a comparable performance to the one obtained with full communication. We outperform full communication at any fixed compression ratio for any communication budget.
Enhancing O-RAN Security: Evasion Attacks and Robust Defenses for Graph Reinforcement Learning-based Connection Management
May 06, 2024Adversarial machine learning, focused on studying various attacks and defenses on machine learning (ML) models, is rapidly gaining importance as ML is increasingly being adopted for optimizing wireless systems such as Open Radio Access Networks (O-RAN). A comprehensive modeling of the security threats and the demonstration of adversarial attacks and defenses on practical AI based O-RAN systems is still in its nascent stages. We begin by conducting threat modeling to pinpoint attack surfaces in O-RAN using an ML-based Connection management application (xApp) as an example. The xApp uses a Graph Neural Network trained using Deep Reinforcement Learning and achieves on average 54% improvement in the coverage rate measured as the 5th percentile user data rates. We then formulate and demonstrate evasion attacks that degrade the coverage rates by as much as 50% through injecting bounded noise at different threat surfaces including the open wireless medium itself. Crucially, we also compare and contrast the effectiveness of such attacks on the ML-based xApp and a non-ML based heuristic. We finally develop and demonstrate robust training-based defenses against the challenging physical/jamming-based attacks and show a 15% improvement in the coverage rates when compared to employing no defense over a range of noise budgets
Investigating the Adversarial Robustness of Density Estimation Using the Probability Flow ODE
Oct 10, 2023



Beyond their impressive sampling capabilities, score-based diffusion models offer a powerful analysis tool in the form of unbiased density estimation of a query sample under the training data distribution. In this work, we investigate the robustness of density estimation using the probability flow (PF) neural ordinary differential equation (ODE) model against gradient-based likelihood maximization attacks and the relation to sample complexity, where the compressed size of a sample is used as a measure of its complexity. We introduce and evaluate six gradient-based log-likelihood maximization attacks, including a novel reverse integration attack. Our experimental evaluations on CIFAR-10 show that density estimation using the PF ODE is robust against high-complexity, high-likelihood attacks, and that in some cases adversarial samples are semantically meaningful, as expected from a robust estimator.
Resource-Efficient Federated Hyperdimensional Computing
Jun 02, 2023
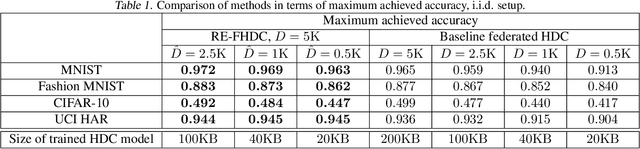


In conventional federated hyperdimensional computing (HDC), training larger models usually results in higher predictive performance but also requires more computational, communication, and energy resources. If the system resources are limited, one may have to sacrifice the predictive performance by reducing the size of the HDC model. The proposed resource-efficient federated hyperdimensional computing (RE-FHDC) framework alleviates such constraints by training multiple smaller independent HDC sub-models and refining the concatenated HDC model using the proposed dropout-inspired procedure. Our numerical comparison demonstrates that the proposed framework achieves a comparable or higher predictive performance while consuming less computational and wireless resources than the baseline federated HDC implementation.
Multi-Task Model Personalization for Federated Supervised SVM in Heterogeneous Networks
Apr 01, 2023Federated systems enable collaborative training on highly heterogeneous data through model personalization, which can be facilitated by employing multi-task learning algorithms. However, significant variation in device computing capabilities may result in substantial degradation in the convergence rate of training. To accelerate the learning procedure for diverse participants in a multi-task federated setting, more efficient and robust methods need to be developed. In this paper, we design an efficient iterative distributed method based on the alternating direction method of multipliers (ADMM) for support vector machines (SVMs), which tackles federated classification and regression. The proposed method utilizes efficient computations and model exchange in a network of heterogeneous nodes and allows personalization of the learning model in the presence of non-i.i.d. data. To further enhance privacy, we introduce a random mask procedure that helps avoid data inversion. Finally, we analyze the impact of the proposed privacy mechanisms and participant hardware and data heterogeneity on the system performance.
Streaming Encoding Algorithms for Scalable Hyperdimensional Computing
Sep 28, 2022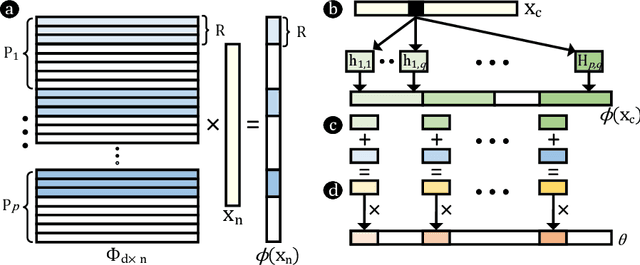


Hyperdimensional computing (HDC) is a paradigm for data representation and learning originating in computational neuroscience. HDC represents data as high-dimensional, low-precision vectors which can be used for a variety of information processing tasks like learning or recall. The mapping to high-dimensional space is a fundamental problem in HDC, and existing methods encounter scalability issues when the input data itself is high-dimensional. In this work, we explore a family of streaming encoding techniques based on hashing. We show formally that these methods enjoy comparable guarantees on performance for learning applications while being substantially more efficient than existing alternatives. We validate these results experimentally on a popular high-dimensional classification problem and show that our approach easily scales to very large data sets.