 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLATTEO: A Framework to Support Learning Asynchronously Tempered with Trusted Execution and Obfuscation
Feb 07, 2025The privacy vulnerabilities of the federated learning (FL) paradigm, primarily caused by gradient leakage, have prompted the development of various defensive measures. Nonetheless, these solutions have predominantly been crafted for and assessed in the context of synchronous FL systems, with minimal focus on asynchronous FL. This gap arises in part due to the unique challenges posed by the asynchronous setting, such as the lack of coordinated updates, increased variability in client participation, and the potential for more severe privacy risks. These concerns have stymied the adoption of asynchronous FL. In this work, we first demonstrate the privacy vulnerabilities of asynchronous FL through a novel data reconstruction attack that exploits gradient updates to recover sensitive client data. To address these vulnerabilities, we propose a privacy-preserving framework that combines a gradient obfuscation mechanism with Trusted Execution Environments (TEEs) for secure asynchronous FL aggregation at the network edge. To overcome the limitations of conventional enclave attestation, we introduce a novel data-centric attestation mechanism based on Multi-Authority Attribute-Based Encryption. This mechanism enables clients to implicitly verify TEE-based aggregation services, effectively handle on-demand client participation, and scale seamlessly with an increasing number of asynchronous connections. Our gradient obfuscation mechanism reduces the structural similarity index of data reconstruction by 85% and increases reconstruction error by 400%, while our framework improves attestation efficiency by lowering average latency by up to 1500% compared to RA-TLS, without additional overhead.
Persistent Backdoor Attacks in Continual Learning
Sep 20, 2024



Backdoor attacks pose a significant threat to neural networks, enabling adversaries to manipulate model outputs on specific inputs, often with devastating consequences, especially in critical applications. While backdoor attacks have been studied in various contexts, little attention has been given to their practicality and persistence in continual learning, particularly in understanding how the continual updates to model parameters, as new data distributions are learned and integrated, impact the effectiveness of these attacks over time. To address this gap, we introduce two persistent backdoor attacks-Blind Task Backdoor and Latent Task Backdoor-each leveraging minimal adversarial influence. Our blind task backdoor subtly alters the loss computation without direct control over the training process, while the latent task backdoor influences only a single task's training, with all other tasks trained benignly. We evaluate these attacks under various configurations, demonstrating their efficacy with static, dynamic, physical, and semantic triggers. Our results show that both attacks consistently achieve high success rates across different continual learning algorithms, while effectively evading state-of-the-art defenses, such as SentiNet and I-BAU.
Unveiling the Unseen: Exploring Whitebox Membership Inference through the Lens of Explainability
Jul 01, 2024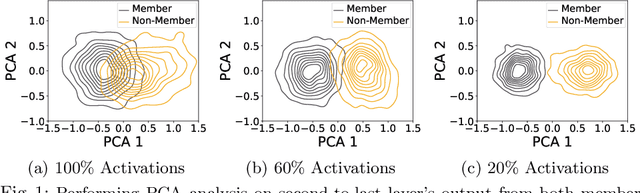
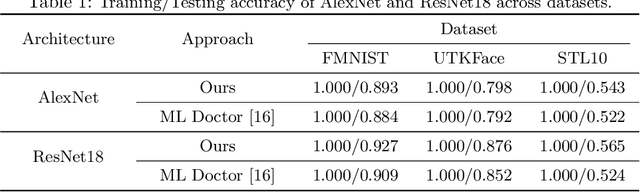
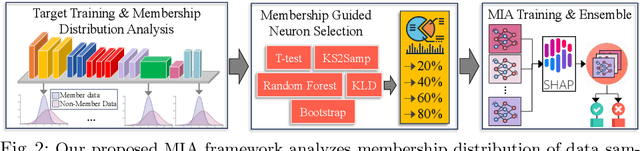
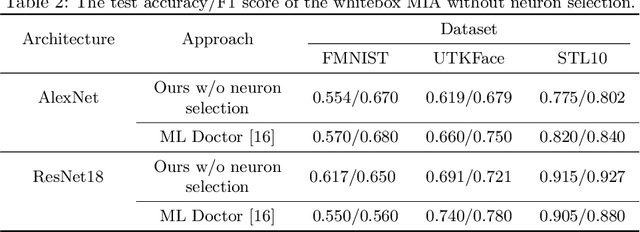
The increasing prominence of deep learning applications and reliance on personalized data underscore the urgent need to address privacy vulnerabilities, particularly Membership Inference Attacks (MIAs). Despite numerous MIA studies, significant knowledge gaps persist, particularly regarding the impact of hidden features (in isolation) on attack efficacy and insufficient justification for the root causes of attacks based on raw data features. In this paper, we aim to address these knowledge gaps by first exploring statistical approaches to identify the most informative neurons and quantifying the significance of the hidden activations from the selected neurons on attack accuracy, in isolation and combination. Additionally, we propose an attack-driven explainable framework by integrating the target and attack models to identify the most influential features of raw data that lead to successful membership inference attacks. Our proposed MIA shows an improvement of up to 26% on state-of-the-art MIA.
Silver Linings in the Shadows: Harnessing Membership Inference for Machine Unlearning
Jul 01, 2024



With the continued advancement and widespread adoption of machine learning (ML) models across various domains, ensuring user privacy and data security has become a paramount concern. In compliance with data privacy regulations, such as GDPR, a secure machine learning framework should not only grant users the right to request the removal of their contributed data used for model training but also facilitates the elimination of sensitive data fingerprints within machine learning models to mitigate potential attack - a process referred to as machine unlearning. In this study, we present a novel unlearning mechanism designed to effectively remove the impact of specific data samples from a neural network while considering the performance of the unlearned model on the primary task. In achieving this goal, we crafted a novel loss function tailored to eliminate privacy-sensitive information from weights and activation values of the target model by combining target classification loss and membership inference loss. Our adaptable framework can easily incorporate various privacy leakage approximation mechanisms to guide the unlearning process. We provide empirical evidence of the effectiveness of our unlearning approach with a theoretical upper-bound analysis through a membership inference mechanism as a proof of concept. Our results showcase the superior performance of our approach in terms of unlearning efficacy and latency as well as the fidelity of the primary task, across four datasets and four deep learning architectures.
Fides: A Generative Framework for Result Validation of Outsourced Machine Learning Workloads via TEE
Mar 31, 2023



The growing popularity of Machine Learning (ML) has led to its deployment in various sensitive domains, which has resulted in significant research focused on ML security and privacy. However, in some applications, such as autonomous driving, integrity verification of the outsourced ML workload is more critical-a facet that has not received much attention. Existing solutions, such as multi-party computation and proof-based systems, impose significant computation overhead, which makes them unfit for real-time applications. We propose Fides, a novel framework for real-time validation of outsourced ML workloads. Fides features a novel and efficient distillation technique-Greedy Distillation Transfer Learning-that dynamically distills and fine-tunes a space and compute-efficient verification model for verifying the corresponding service model while running inside a trusted execution environment. Fides features a client-side attack detection model that uses statistical analysis and divergence measurements to identify, with a high likelihood, if the service model is under attack. Fides also offers a re-classification functionality that predicts the original class whenever an attack is identified. We devised a generative adversarial network framework for training the attack detection and re-classification models. The extensive evaluation shows that Fides achieves an accuracy of up to 98% for attack detection and 94% for re-classification.
DLWIoT: Deep Learning-based Watermarking for Authorized IoT Onboarding
Oct 18, 2020
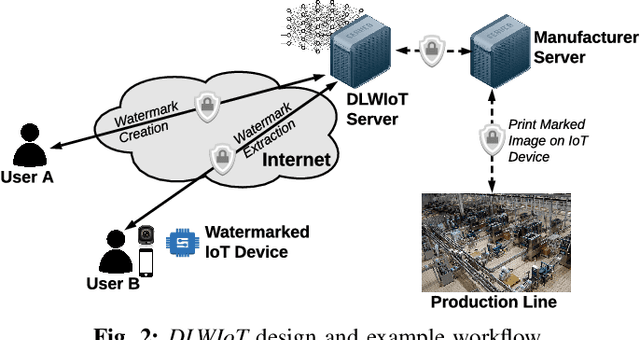
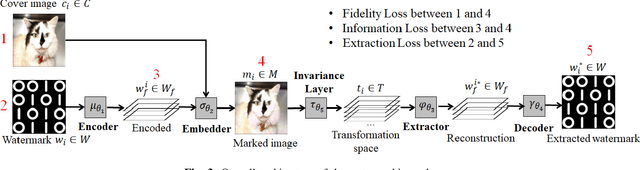
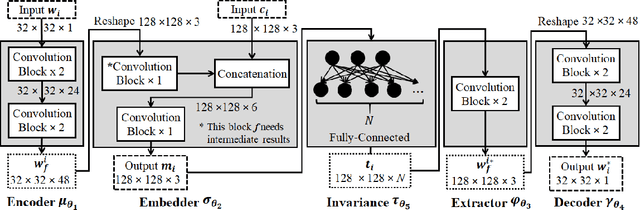
The onboarding of IoT devices by authorized users constitutes both a challenge and a necessity in a world, where the number of IoT devices and the tampering attacks against them continuously increase. Commonly used onboarding techniques today include the use of QR codes, pin codes, or serial numbers. These techniques typically do not protect against unauthorized device access-a QR code is physically printed on the device, while a pin code may be included in the device packaging. As a result, any entity that has physical access to a device can onboard it onto their network and, potentially, tamper it (e.g.,install malware on the device). To address this problem, in this paper, we present a framework, called Deep Learning-based Watermarking for authorized IoT onboarding (DLWIoT), featuring a robust and fully automated image watermarking scheme based on deep neural networks. DLWIoT embeds user credentials into carrier images (e.g., QR codes printed on IoT devices), thus enables IoT onboarding only by authorized users. Our experimental results demonstrate the feasibility of DLWIoT, indicating that authorized users can onboard IoT devices with DLWIoT within 2.5-3sec.