 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvariant Features in Language Models: Geometric Characterization and Model Attribution
May 07, 2026Language models exhibit strong robustness to paraphrasing, suggesting that semantic information may be encoded through stable internal representations, yet the structure and origin of such invariance remain unclear. We propose a local geometric framework in which semantically equivalent inputs occupy structured regions in latent space, with paraphrastic variation along nuisance directions and semantic identity preserved in invariant subspaces. Building on this view, we make three contributions: (1) a geometric characterization of invariant latent features, (2) a contrastive subspace discovery method that separates semantic-changing from semantic-preserving variation, and (3) an application of invariant representations to zero-shot model attribution. Across models and layers, empirical results support these contributions. Invariant structure emerges in specific depth regions, semantic displacement lies largely outside the nuisance subspace, and representation-level interventions indicate a causal role of invariant components in model outputs. Invariant representations also capture model-specific geometric patterns, enabling accurate attribution. These findings suggest that semantic invariance can be viewed as a local geometric property of latent representations, offering a principled perspective on how language models organize meaning.
Multi-function Robotized Surgical Dissector for Endoscopic Pulmonary Thromboendarterectomy: Preclinical Study and Evaluation
Feb 03, 2026Patients suffering chronic severe pulmonary thromboembolism need Pulmonary Thromboendarterectomy (PTE) to remove the thromb and intima located inside pulmonary artery (PA). During the surgery, a surgeon holds tweezers and a dissector to delicately strip the blockage, but available tools for this surgery are rigid and straight, lacking distal dexterity to access into thin branches of PA. Therefore, this work presents a novel robotized dissector based on concentric push/pull robot (CPPR) structure, enabling entering deep thin branch of tortuous PA. Compared with conventional rigid dissectors, our design characterizes slenderness and dual-segment-bending dexterity. Owing to the hollow and thin-walled structure of the CPPR-based dissector as it has a slender body of 3.5mm in diameter, the central lumen accommodates two channels for irrigation and tip tool, and space for endoscopic camera's signal wire. To provide accurate surgical manipulation, optimization-based kinematics model was established, realizing a 2mm accuracy in positioning the tip tool (60mm length) under open-loop control strategy. As such, with the endoscopic camera, traditional PTE is possible to be upgraded as endoscopic PTE. Basic physic performance of the robotized dissector including stiffness, motion accuracy and maneuverability was evaluated through experiments. Surgery simulation on ex vivo porcine lung also demonstrates its dexterity and notable advantages in PTE.
Interpretable Dual-Stream Learning for Local Wind Hazard Prediction in Vulnerable Communities
May 20, 2025


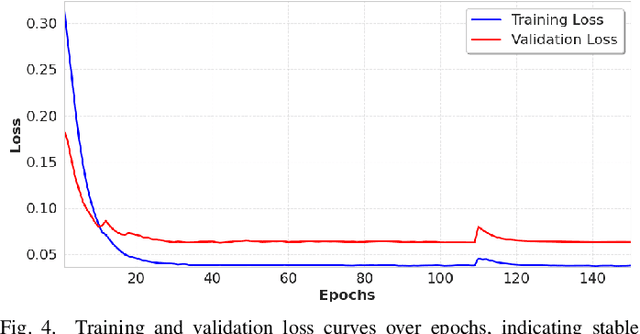
Wind hazards such as tornadoes and straight-line winds frequently affect vulnerable communities in the Great Plains of the United States, where limited infrastructure and sparse data coverage hinder effective emergency response. Existing forecasting systems focus primarily on meteorological elements and often fail to capture community-specific vulnerabilities, limiting their utility for localized risk assessment and resilience planning. To address this gap, we propose an interpretable dual-stream learning framework that integrates structured numerical weather data with unstructured textual event narratives. Our architecture combines a Random Forest and RoBERTa-based transformer through a late fusion mechanism, enabling robust and context-aware wind hazard prediction. The system is tailored for underserved tribal communities and supports block-level risk assessment. Experimental results show significant performance gains over traditional baselines. Furthermore, gradient-based sensitivity and ablation studies provide insight into the model's decision-making process, enhancing transparency and operational trust. The findings demonstrate both predictive effectiveness and practical value in supporting emergency preparedness and advancing community resilience.
Text-Guided Image Invariant Feature Learning for Robust Image Watermarking
Mar 18, 2025



Ensuring robustness in image watermarking is crucial for and maintaining content integrity under diverse transformations. Recent self-supervised learning (SSL) approaches, such as DINO, have been leveraged for watermarking but primarily focus on general feature representation rather than explicitly learning invariant features. In this work, we propose a novel text-guided invariant feature learning framework for robust image watermarking. Our approach leverages CLIP's multimodal capabilities, using text embeddings as stable semantic anchors to enforce feature invariance under distortions. We evaluate the proposed method across multiple datasets, demonstrating superior robustness against various image transformations. Compared to state-of-the-art SSL methods, our model achieves higher cosine similarity in feature consistency tests and outperforms existing watermarking schemes in extraction accuracy under severe distortions. These results highlight the efficacy of our method in learning invariant representations tailored for robust deep learning-based watermarking.
A Neural Network Architecture Based on Attention Gate Mechanism for 3D Magnetotelluric Forward Modeling
Mar 14, 2025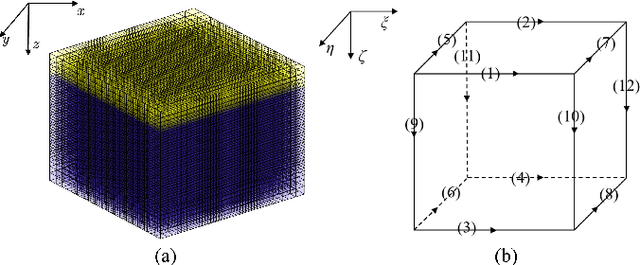
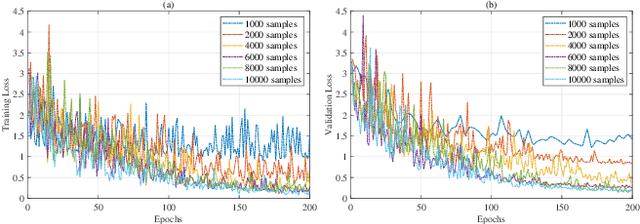
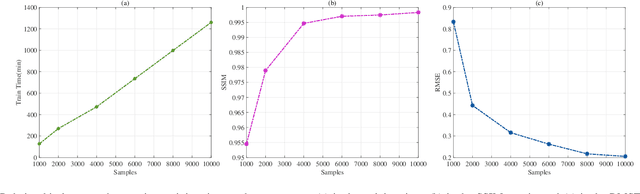
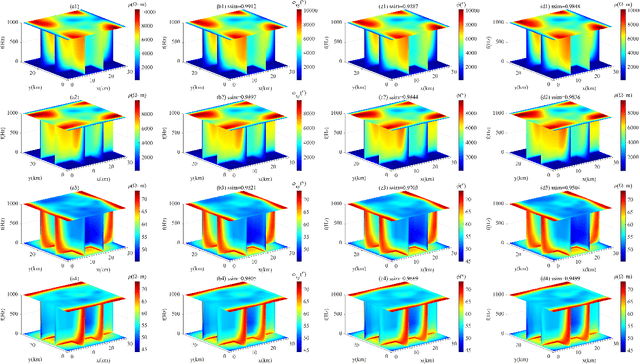
Traditional three-dimensional magnetotelluric (MT) numerical forward modeling methods, such as the finite element method (FEM) and finite volume method (FVM), suffer from high computational costs and low efficiency due to limitations in mesh refinement and computational resources. We propose a novel neural network architecture named MTAGU-Net, which integrates an attention gating mechanism for 3D MT forward modeling. Specifically, a dual-path attention gating module is designed based on forward response data images and embedded in the skip connections between the encoder and decoder. This module enables the fusion of critical anomaly information from shallow feature maps during the decoding of deep feature maps, significantly enhancing the network's capability to extract features from anomalous regions. Furthermore, we introduce a synthetic model generation method utilizing 3D Gaussian random field (GRF), which accurately replicates the electrical structures of real-world geological scenarios with high fidelity. Numerical experiments demonstrate that MTAGU-Net outperforms conventional 3D U-Net in terms of convergence stability and prediction accuracy, with the structural similarity index (SSIM) of the forward response data consistently exceeding 0.98. Moreover, the network can accurately predict forward response data on previously unseen datasets models, demonstrating its strong generalization ability and validating the feasibility and effectiveness of this method in practical applications.
Ultra-slender Coaxial Antagonistic Tubular Robot for Ambidextrous Manipulation
Dec 25, 2024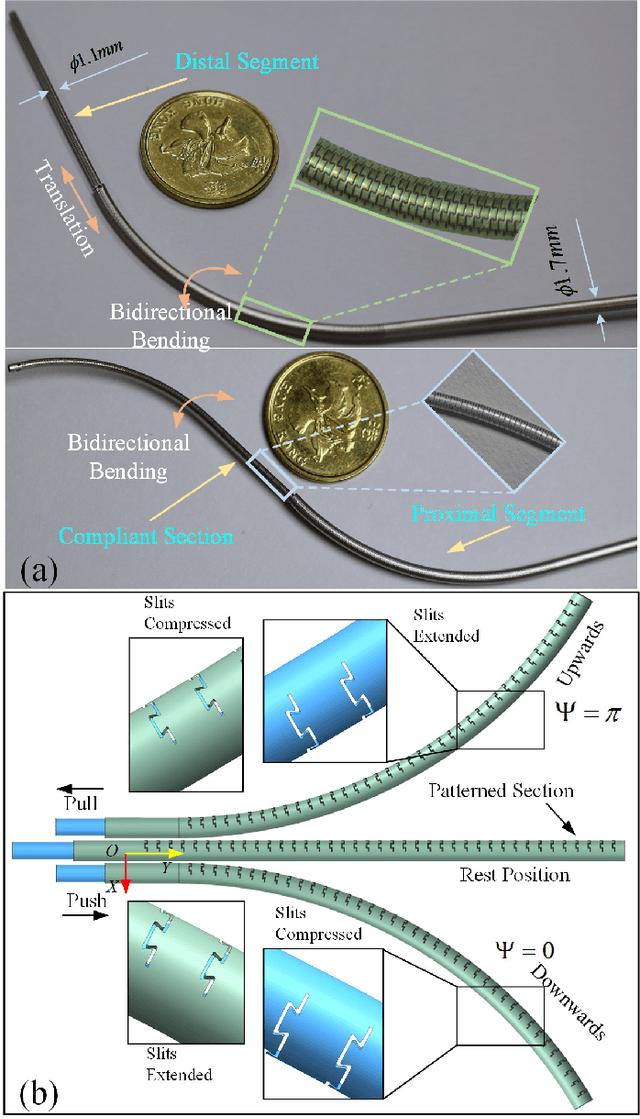

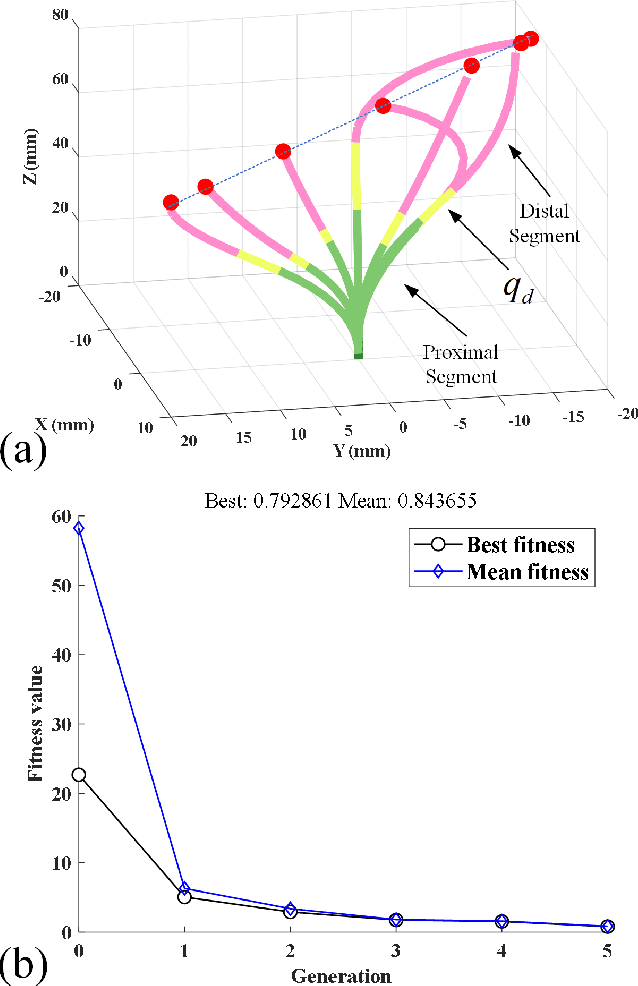

As soft continuum manipulators characterize terrific compliance and maneuverability in narrow unstructured space, low stiffness and limited dexterity are two obvious shortcomings in practical applications. To address the issues, a novel asymmetric coaxial antagonistic tubular robot (CATR) arm with high stiffness has been proposed, where two asymmetrically patterned metal tubes were fixed at the tip end with a shift angle of 180{\deg} and axial actuation force at the other end deforms the tube. Delicately designed and optimized steerable section and fully compliant section enable the soft manipulator high dexterity and stiffness. The basic kinetostatics model of a single segment was established on the basis of geometric and statics, and constrained optimization algorithm promotes finding the actuation inputs for a given desired task configuration. In addition, we have specifically built the design theory for the slits patterned on the tube surface, taking both bending angle and stiffness into account. Experiments demonstrate that the proposed robot arm is dexterous and has greater stiffness compared with same-size continuum robots. Furthermore, experiments also showcase the potential in minimally invasive surgery.
Watermarking Language Models through Language Models
Nov 07, 2024

This paper presents a novel framework for watermarking language models through prompts generated by language models. The proposed approach utilizes a multi-model setup, incorporating a Prompting language model to generate watermarking instructions, a Marking language model to embed watermarks within generated content, and a Detecting language model to verify the presence of these watermarks. Experiments are conducted using ChatGPT and Mistral as the Prompting and Marking language models, with detection accuracy evaluated using a pretrained classifier model. Results demonstrate that the proposed framework achieves high classification accuracy across various configurations, with 95% accuracy for ChatGPT, 88.79% for Mistral. These findings validate the and adaptability of the proposed watermarking strategy across different language model architectures. Hence the proposed framework holds promise for applications in content attribution, copyright protection, and model authentication.
CALF: Benchmarking Evaluation of LFQA Using Chinese Examinations
Oct 02, 2024



Long-Form Question Answering (LFQA) refers to generating in-depth, paragraph-level responses to open-ended questions. Although lots of LFQA methods are developed, evaluating LFQA effectively and efficiently remains challenging due to its high complexity and cost. Therefore, there is no standard benchmark for LFQA evaluation till now. To address this gap, we make the first attempt by proposing a well-constructed, reference-based benchmark named Chinese exAmination for LFQA Evaluation (CALF), aiming to rigorously assess the performance of automatic evaluation metrics for LFQA. The CALF benchmark is derived from Chinese examination questions that have been translated into English. It includes up to 1476 examples consisting of knowledge-intensive and nuanced responses. Our evaluation comprises three different settings to ana lyze the behavior of automatic metrics comprehensively. We conducted extensive experiments on 7 traditional evaluation metrics, 3 prompt-based metrics, and 3 trained evaluation metrics, and tested on agent systems for the LFQA evaluation. The results reveal that none of the current automatic evaluation metrics shows comparable performances with humans, indicating that they cannot capture dense information contained in long-form responses well. In addition, we provide a detailed analysis of the reasons why automatic evaluation metrics fail when evaluating LFQA, offering valuable insights to advance LFQA evaluation systems. Dataset and associated codes can be accessed at our GitHub repository.
EVA-Score: Evaluation of Long-form Summarization on Informativeness through Extraction and Validation
Jul 06, 2024
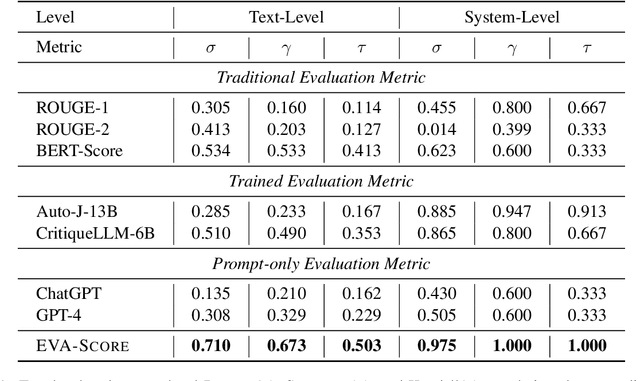


Summarization is a fundamental task in natural language processing (NLP) and since large language models (LLMs), such as GPT-4 and Claude, come out, increasing attention has been paid to long-form summarization whose input sequences are much longer, indicating more information contained. The current evaluation metrics either use similarity-based metrics like ROUGE and BERTScore which rely on similarity and fail to consider informativeness or LLM-based metrics, lacking quantitative analysis of information richness and are rather subjective. In this paper, we propose a new evaluation metric called EVA-Score using Atomic Fact Chain Generation and Document-level Relation Extraction together to automatically calculate the informativeness and give a definite number as an information score. Experiment results show that our metric shows a state-of-the-art correlation with humans. We also re-evaluate the performance of LLMs on long-form summarization comprehensively from the information aspect, forecasting future ways to use LLMs for long-form summarization.
Deep Learning-based Text-in-Image Watermarking
Apr 19, 2024In this work, we introduce a novel deep learning-based approach to text-in-image watermarking, a method that embeds and extracts textual information within images to enhance data security and integrity. Leveraging the capabilities of deep learning, specifically through the use of Transformer-based architectures for text processing and Vision Transformers for image feature extraction, our method sets new benchmarks in the domain. The proposed method represents the first application of deep learning in text-in-image watermarking that improves adaptivity, allowing the model to intelligently adjust to specific image characteristics and emerging threats. Through testing and evaluation, our method has demonstrated superior robustness compared to traditional watermarking techniques, achieving enhanced imperceptibility that ensures the watermark remains undetectable across various image contents.