 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProRL Agent: Rollout-as-a-Service for RL Training of Multi-Turn LLM Agents
Mar 19, 2026Multi-turn LLM agents are increasingly important for solving complex, interactive tasks, and reinforcement learning (RL) is a key ingredient for improving their long-horizon behavior. However, RL training requires generating large numbers of sandboxed rollout trajectories, and existing infrastructures often couple rollout orchestration with the training loop, making systems hard to migrate and maintain. Under the rollout-as-a-service philosophy, we present ProRL Agent , a scalable infrastructure that serves the full agentic rollout lifecycle through an API service. ProRL Agent also provides standardized and extensible sandbox environments that support diverse agentic tasks in rootless HPC settings. We validate ProRL Agent through RL training on software engineering, math, STEM, and coding tasks. ProRL Agent is open-sourced and integrated as part of NVIDIA NeMo Gym.
GraphThinker: Reinforcing Video Reasoning with Event Graph Thinking
Feb 19, 2026Video reasoning requires understanding the causal relationships between events in a video. However, such relationships are often implicit and costly to annotate manually. While existing multimodal large language models (MLLMs) often infer event relations through dense captions or video summaries for video reasoning, such modeling still lacks causal understanding. Without explicit causal structure modeling within and across video events, these models suffer from hallucinations during the video reasoning. In this work, we propose GraphThinker, a reinforcement finetuning-based method that constructs structural event-level scene graphs and enhances visual grounding to jointly reduce hallucinations in video reasoning. Specifically, we first employ an MLLM to construct an event-based video scene graph (EVSG) that explicitly models both intra- and inter-event relations, and incorporate these formed scene graphs into the MLLM as an intermediate thinking process. We also introduce a visual attention reward during reinforcement finetuning, which strengthens video grounding and further mitigates hallucinations. We evaluate GraphThinker on two datasets, RexTime and VidHalluc, where it shows superior ability to capture object and event relations with more precise event localization, reducing hallucinations in video reasoning compared to prior methods.
Golden Goose: A Simple Trick to Synthesize Unlimited RLVR Tasks from Unverifiable Internet Text
Jan 30, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has become a cornerstone for unlocking complex reasoning in Large Language Models (LLMs). Yet, scaling up RL is bottlenecked by limited existing verifiable data, where improvements increasingly saturate over prolonged training. To overcome this, we propose Golden Goose, a simple trick to synthesize unlimited RLVR tasks from unverifiable internet text by constructing a multiple-choice question-answering version of the fill-in-the-middle task. Given a source text, we prompt an LLM to identify and mask key reasoning steps, then generate a set of diverse, plausible distractors. This enables us to leverage reasoning-rich unverifiable corpora typically excluded from prior RLVR data construction (e.g., science textbooks) to synthesize GooseReason-0.7M, a large-scale RLVR dataset with over 0.7 million tasks spanning mathematics, programming, and general scientific domains. Empirically, GooseReason effectively revives models saturated on existing RLVR data, yielding robust, sustained gains under continuous RL and achieving new state-of-the-art results for 1.5B and 4B-Instruct models across 15 diverse benchmarks. Finally, we deploy Golden Goose in a real-world setting, synthesizing RLVR tasks from raw FineWeb scrapes for the cybersecurity domain, where no prior RLVR data exists. Training Qwen3-4B-Instruct on the resulting data GooseReason-Cyber sets a new state-of-the-art in cybersecurity, surpassing a 7B domain-specialized model with extensive domain-specific pre-training and post-training. This highlights the potential of automatically scaling up RLVR data by exploiting abundant, reasoning-rich, unverifiable internet text.
Part I: Tricks or Traps? A Deep Dive into RL for LLM Reasoning
Aug 11, 2025Reinforcement learning for LLM reasoning has rapidly emerged as a prominent research area, marked by a significant surge in related studies on both algorithmic innovations and practical applications. Despite this progress, several critical challenges remain, including the absence of standardized guidelines for employing RL techniques and a fragmented understanding of their underlying mechanisms. Additionally, inconsistent experimental settings, variations in training data, and differences in model initialization have led to conflicting conclusions, obscuring the key characteristics of these techniques and creating confusion among practitioners when selecting appropriate techniques. This paper systematically reviews widely adopted RL techniques through rigorous reproductions and isolated evaluations within a unified open-source framework. We analyze the internal mechanisms, applicable scenarios, and core principles of each technique through fine-grained experiments, including datasets of varying difficulty, model sizes, and architectures. Based on these insights, we present clear guidelines for selecting RL techniques tailored to specific setups, and provide a reliable roadmap for practitioners navigating the RL for the LLM domain. Finally, we reveal that a minimalist combination of two techniques can unlock the learning capability of critic-free policies using vanilla PPO loss. The results demonstrate that our simple combination consistently improves performance, surpassing strategies like GRPO and DAPO.
Uncertainty-quantified Rollout Policy Adaptation for Unlabelled Cross-domain Temporal Grounding
Aug 08, 2025Video Temporal Grounding (TG) aims to temporally locate video segments matching a natural language description (a query) in a long video. While Vision-Language Models (VLMs) are effective at holistic semantic matching, they often struggle with fine-grained temporal localisation. Recently, Group Relative Policy Optimisation (GRPO) reformulates the inference process as a reinforcement learning task, enabling fine-grained grounding and achieving strong in-domain performance. However, GRPO relies on labelled data, making it unsuitable in unlabelled domains. Moreover, because videos are large and expensive to store and process, performing full-scale adaptation introduces prohibitive latency and computational overhead, making it impractical for real-time deployment. To overcome both problems, we introduce a Data-Efficient Unlabelled Cross-domain Temporal Grounding method, from which a model is first trained on a labelled source domain, then adapted to a target domain using only a small number of unlabelled videos from the target domain. This approach eliminates the need for target annotation and keeps both computational and storage overhead low enough to run in real time. Specifically, we introduce. Uncertainty-quantified Rollout Policy Adaptation (URPA) for cross-domain knowledge transfer in learning video temporal grounding without target labels. URPA generates multiple candidate predictions using GRPO rollouts, averages them to form a pseudo label, and estimates confidence from the variance across these rollouts. This confidence then weights the training rewards, guiding the model to focus on reliable supervision. Experiments on three datasets across six cross-domain settings show that URPA generalises well using only a few unlabelled target videos. Codes will be released once published.
ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models
May 30, 2025Recent advances in reasoning-centric language models have highlighted reinforcement learning (RL) as a promising method for aligning models with verifiable rewards. However, it remains contentious whether RL truly expands a model's reasoning capabilities or merely amplifies high-reward outputs already latent in the base model's distribution, and whether continually scaling up RL compute reliably leads to improved reasoning performance. In this work, we challenge prevailing assumptions by demonstrating that prolonged RL (ProRL) training can uncover novel reasoning strategies that are inaccessible to base models, even under extensive sampling. We introduce ProRL, a novel training methodology that incorporates KL divergence control, reference policy resetting, and a diverse suite of tasks. Our empirical analysis reveals that RL-trained models consistently outperform base models across a wide range of pass@k evaluations, including scenarios where base models fail entirely regardless of the number of attempts. We further show that reasoning boundary improvements correlates strongly with task competence of base model and training duration, suggesting that RL can explore and populate new regions of solution space over time. These findings offer new insights into the conditions under which RL meaningfully expands reasoning boundaries in language models and establish a foundation for future work on long-horizon RL for reasoning. We release model weights to support further research: https://huggingface.co/nvidia/Nemotron-Research-Reasoning-Qwen-1.5B
ViSMaP: Unsupervised Hour-long Video Summarisation by Meta-Prompting
Apr 22, 2025We introduce ViSMap: Unsupervised Video Summarisation by Meta Prompting, a system to summarise hour long videos with no-supervision. Most existing video understanding models work well on short videos of pre-segmented events, yet they struggle to summarise longer videos where relevant events are sparsely distributed and not pre-segmented. Moreover, long-form video understanding often relies on supervised hierarchical training that needs extensive annotations which are costly, slow and prone to inconsistency. With ViSMaP we bridge the gap between short videos (where annotated data is plentiful) and long ones (where it's not). We rely on LLMs to create optimised pseudo-summaries of long videos using segment descriptions from short ones. These pseudo-summaries are used as training data for a model that generates long-form video summaries, bypassing the need for expensive annotations of long videos. Specifically, we adopt a meta-prompting strategy to iteratively generate and refine creating pseudo-summaries of long videos. The strategy leverages short clip descriptions obtained from a supervised short video model to guide the summary. Each iteration uses three LLMs working in sequence: one to generate the pseudo-summary from clip descriptions, another to evaluate it, and a third to optimise the prompt of the generator. This iteration is necessary because the quality of the pseudo-summaries is highly dependent on the generator prompt, and varies widely among videos. We evaluate our summaries extensively on multiple datasets; our results show that ViSMaP achieves performance comparable to fully supervised state-of-the-art models while generalising across domains without sacrificing performance. Code will be released upon publication.
LeetCodeDataset: A Temporal Dataset for Robust Evaluation and Efficient Training of Code LLMs
Apr 20, 2025
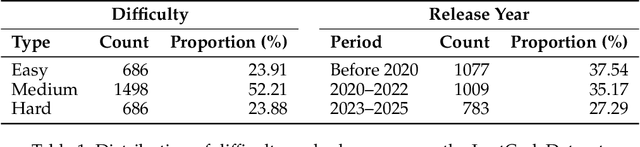
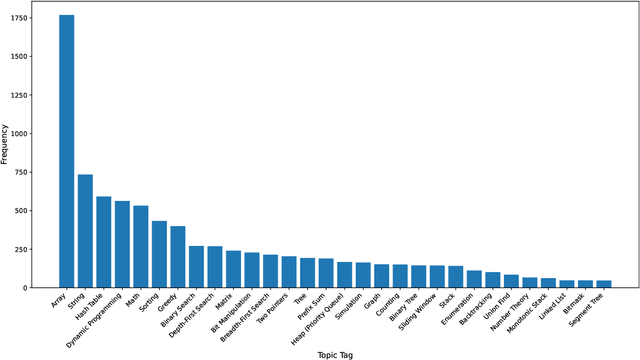
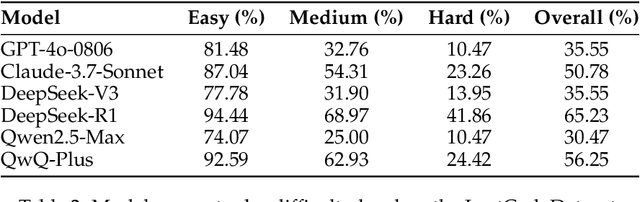
We introduce LeetCodeDataset, a high-quality benchmark for evaluating and training code-generation models, addressing two key challenges in LLM research: the lack of reasoning-focused coding benchmarks and self-contained training testbeds. By curating LeetCode Python problems with rich metadata, broad coverage, 100+ test cases per problem, and temporal splits (pre/post July 2024), our dataset enables contamination-free evaluation and efficient supervised fine-tuning (SFT). Experiments show reasoning models significantly outperform non-reasoning counterparts, while SFT with only 2.6K model-generated solutions achieves performance comparable to 110K-sample counterparts. The dataset and evaluation framework are available on Hugging Face and Github.
V-STaR: Benchmarking Video-LLMs on Video Spatio-Temporal Reasoning
Mar 14, 2025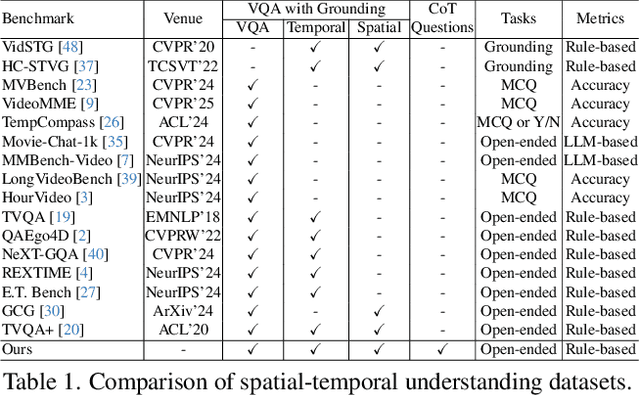
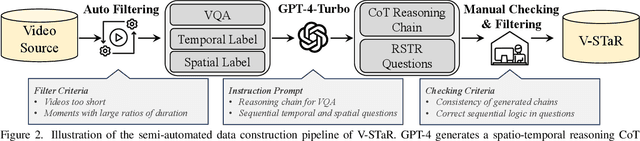

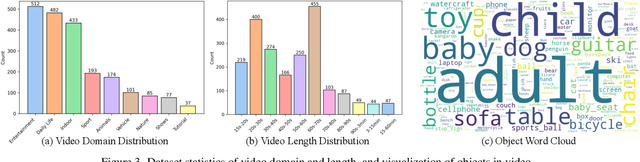
Human processes video reasoning in a sequential spatio-temporal reasoning logic, we first identify the relevant frames ("when") and then analyse the spatial relationships ("where") between key objects, and finally leverage these relationships to draw inferences ("what"). However, can Video Large Language Models (Video-LLMs) also "reason through a sequential spatio-temporal logic" in videos? Existing Video-LLM benchmarks primarily focus on assessing object presence, neglecting relational reasoning. Consequently, it is difficult to measure whether a model truly comprehends object interactions (actions/events) in videos or merely relies on pre-trained "memory" of co-occurrences as biases in generating answers. In this work, we introduce a Video Spatio-Temporal Reasoning (V-STaR) benchmark to address these shortcomings. The key idea is to decompose video understanding into a Reverse Spatio-Temporal Reasoning (RSTR) task that simultaneously evaluates what objects are present, when events occur, and where they are located while capturing the underlying Chain-of-thought (CoT) logic. To support this evaluation, we construct a dataset to elicit the spatial-temporal reasoning process of Video-LLMs. It contains coarse-to-fine CoT questions generated by a semi-automated GPT-4-powered pipeline, embedding explicit reasoning chains to mimic human cognition. Experiments from 14 Video-LLMs on our V-STaR reveal significant gaps between current Video-LLMs and the needs for robust and consistent spatio-temporal reasoning.
CoS: Chain-of-Shot Prompting for Long Video Understanding
Feb 10, 2025



Multi-modal Large Language Models (MLLMs) struggle with long videos due to the need for excessive visual tokens. These tokens exceed massively the context length of MLLMs, resulting in filled by redundant task-irrelevant shots. How to select shots is an unsolved critical problem: sparse sampling risks missing key details, while exhaustive sampling overwhelms the model with irrelevant content, leading to video misunderstanding. To solve this problem, we propose Chain-of-Shot prompting (CoS). The key idea is to frame shot selection as test-time visual prompt optimisation, choosing shots adaptive to video understanding semantic task by optimising shots-task alignment. CoS has two key parts: (1) a binary video summary mechanism that performs pseudo temporal grounding, discovering a binary coding to identify task-relevant shots, and (2) a video co-reasoning module that deploys the binary coding to pair (learning to align) task-relevant positive shots with irrelevant negative shots. It embeds the optimised shot selections into the original video, facilitating a focus on relevant context to optimize long video understanding. Experiments across three baselines and five datasets demonstrate the effectiveness and adaptability of CoS. Code given in https://lwpyh.github.io/CoS.