 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvSeg: Test-Time Prompt Inversion for Semantic Segmentation
Paper and Code
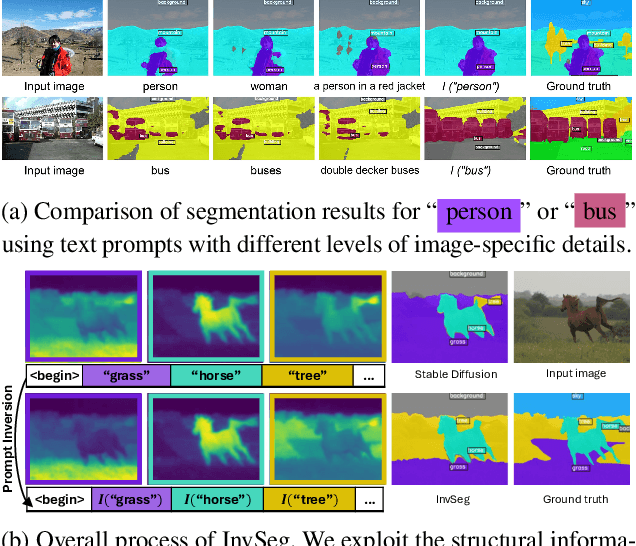
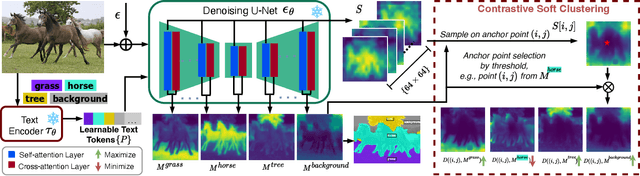
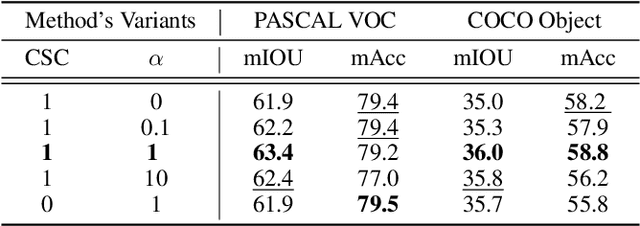
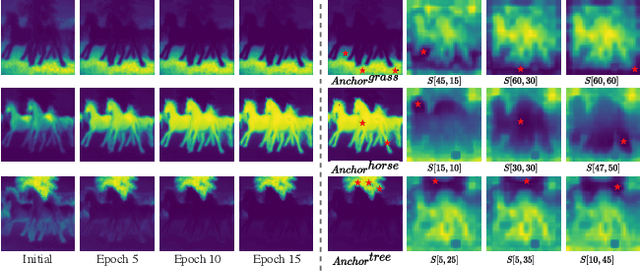
Visual-textual correlations in the attention maps derived from text-to-image diffusion models are proven beneficial to dense visual prediction tasks, e.g., semantic segmentation. However, a significant challenge arises due to the input distributional discrepancy between the context-rich sentences used for image generation and the isolated class names typically employed in semantic segmentation, hindering the diffusion models from capturing accurate visual-textual correlations. To solve this, we propose InvSeg, a test-time prompt inversion method that tackles open-vocabulary semantic segmentation by inverting image-specific visual context into text prompt embedding space, leveraging structure information derived from the diffusion model's reconstruction process to enrich text prompts so as to associate each class with a structure-consistent mask. Specifically, we introduce Contrastive Soft Clustering (CSC) to align derived masks with the image's structure information, softly selecting anchors for each class and calculating weighted distances to push inner-class pixels closer while separating inter-class pixels, thereby ensuring mask distinction and internal consistency. By incorporating sample-specific context, InvSeg learns context-rich text prompts in embedding space and achieves accurate semantic alignment across modalities. Experiments show that InvSeg achieves state-of-the-art performance on the PASCAL VOC and Context datasets. Project page: https://jylin8100.github.io/InvSegProject/.