 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Recipes for Efficient and Compact Vision-Language Models
Mar 17, 2026Deploying vision-language models (VLMs) in resource-constrained settings demands low latency and high throughput, yet existing compact VLMs often fall short of the inference speedups their smaller parameter counts suggest. To explain this discrepancy, we conduct an empirical end-to-end efficiency analysis and systematically profile inference to identify the dominant bottlenecks. Based on these findings, we develop optimization recipes tailored to compact VLMs that substantially reduce latency while preserving accuracy. These techniques cut time to first token (TTFT) by 53% on InternVL3-2B and by 93% on SmolVLM-256M. Our recipes are broadly applicable across both VLM architectures and common serving frameworks, providing practical guidance for building efficient VLM systems. Beyond efficiency, we study how to extend compact VLMs with structured perception outputs and introduce the resulting model family, ArgusVLM. Across diverse benchmarks, ArgusVLM achieves strong performance while maintaining a compact and efficient design.
UniCompress: Token Compression for Unified Vision-Language Understanding and Generation
Mar 11, 2026Unified models aim to support both understanding and generation by encoding images into discrete tokens and processing them alongside text within a single autoregressive framework. This unified design offers architectural simplicity and cross-modal synergy, which facilitates shared parameterization, consistent training objectives, and seamless transfer between modalities. However, the large number of visual tokens required by such models introduces substantial computation and memory overhead, and this inefficiency directly hinders deployment in resource constrained scenarios such as embodied AI systems. In this work, we propose a unified token compression algorithm UniCompress that significantly reduces visual token count while preserving performance on both image understanding and generation tasks. Our method introduces a plug-in compression and decompression mechanism guided with learnable global meta tokens. The framework is lightweight and modular, enabling efficient integration into existing models without full retraining. Experimental results show that our approach reduces image tokens by up to 4 times, achieves substantial gains in inference latency and training cost, and incurs only minimal performance degradation, which demonstrates the promise of token-efficient unified modeling for real world multimodal applications.
UNIFORM: Unifying Knowledge from Large-scale and Diverse Pre-trained Models
Aug 27, 2025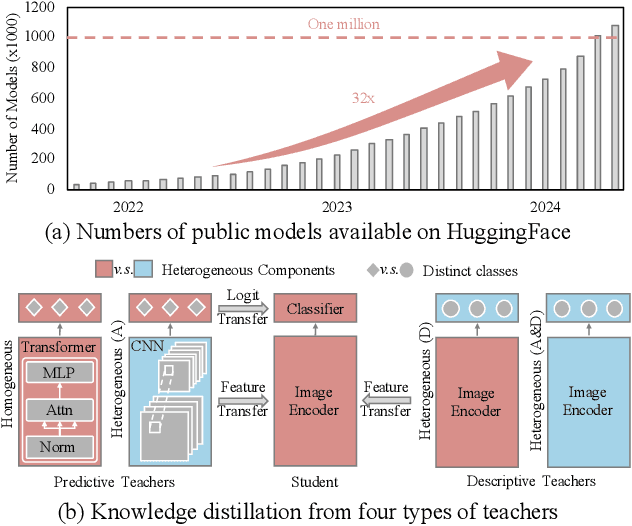
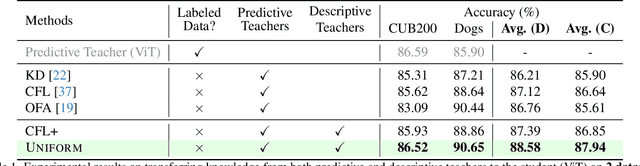
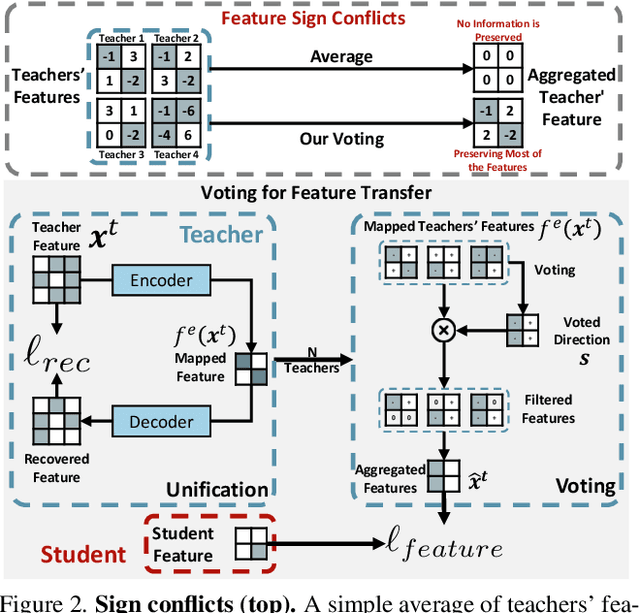
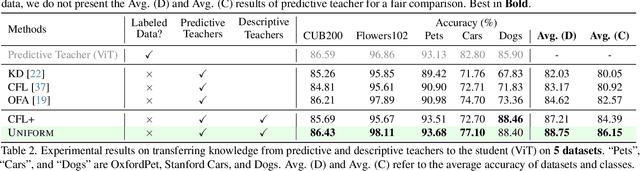
In the era of deep learning, the increasing number of pre-trained models available online presents a wealth of knowledge. These models, developed with diverse architectures and trained on varied datasets for different tasks, provide unique interpretations of the real world. Their collective consensus is likely universal and generalizable to unseen data. However, effectively harnessing this collective knowledge poses a fundamental challenge due to the heterogeneity of pre-trained models. Existing knowledge integration solutions typically rely on strong assumptions about training data distributions and network architectures, limiting them to learning only from specific types of models and resulting in data and/or inductive biases. In this work, we introduce a novel framework, namely UNIFORM, for knowledge transfer from a diverse set of off-the-shelf models into one student model without such constraints. Specifically, we propose a dedicated voting mechanism to capture the consensus of knowledge both at the logit level -- incorporating teacher models that are capable of predicting target classes of interest -- and at the feature level, utilizing visual representations learned on arbitrary label spaces. Extensive experiments demonstrate that UNIFORM effectively enhances unsupervised object recognition performance compared to strong knowledge transfer baselines. Notably, it exhibits remarkable scalability by benefiting from over one hundred teachers, while existing methods saturate at a much smaller scale.
Seeing Further on the Shoulders of Giants: Knowledge Inheritance for Vision Foundation Models
Aug 20, 2025Vision foundation models (VFMs) are predominantly developed using data-centric methods. These methods require training on vast amounts of data usually with high-quality labels, which poses a bottleneck for most institutions that lack both large-scale data and high-end GPUs. On the other hand, many open-source vision models have been pretrained on domain-specific data, enabling them to distill and represent core knowledge in a form that is transferable across diverse applications. Even though these models are highly valuable assets, they remain largely under-explored in empowering the development of a general-purpose VFM. In this paper, we presents a new model-driven approach for training VFMs through joint knowledge transfer and preservation. Our method unifies multiple pre-trained teacher models in a shared latent space to mitigate the ``imbalanced transfer'' issue caused by their distributional gaps. Besides, we introduce a knowledge preservation strategy to take a general-purpose teacher as a knowledge base for integrating knowledge from the remaining purpose-specific teachers using an adapter module. By unifying and aggregating existing models, we build a powerful VFM to inherit teachers' expertise without needing to train on a large amount of labeled data. Our model not only provides generalizable visual features, but also inherently supports multiple downstream tasks. Extensive experiments demonstrate that our VFM outperforms existing data-centric models across four fundamental vision tasks, including image classification, object detection, semantic and instance segmentation.
InvSeg: Test-Time Prompt Inversion for Semantic Segmentation
Oct 15, 2024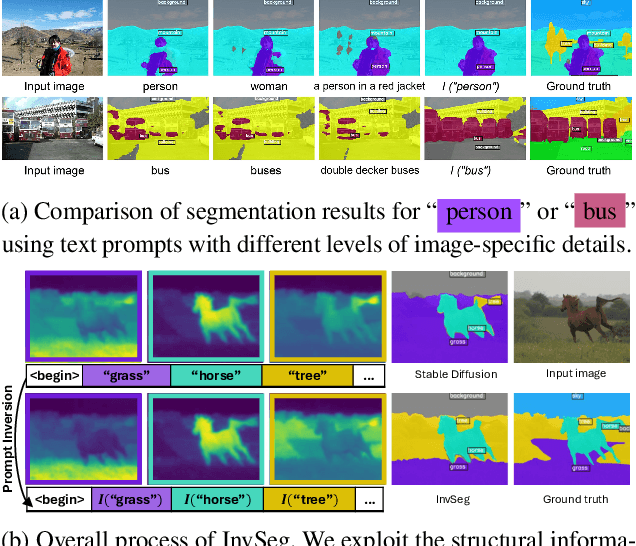
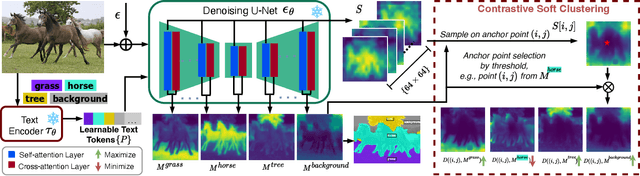
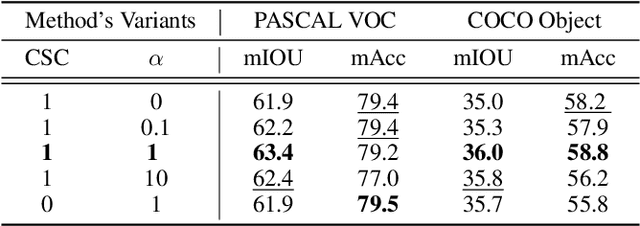
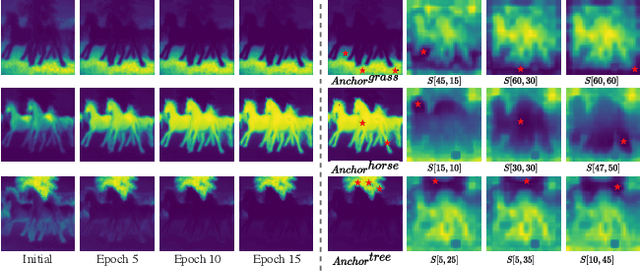
Visual-textual correlations in the attention maps derived from text-to-image diffusion models are proven beneficial to dense visual prediction tasks, e.g., semantic segmentation. However, a significant challenge arises due to the input distributional discrepancy between the context-rich sentences used for image generation and the isolated class names typically employed in semantic segmentation, hindering the diffusion models from capturing accurate visual-textual correlations. To solve this, we propose InvSeg, a test-time prompt inversion method that tackles open-vocabulary semantic segmentation by inverting image-specific visual context into text prompt embedding space, leveraging structure information derived from the diffusion model's reconstruction process to enrich text prompts so as to associate each class with a structure-consistent mask. Specifically, we introduce Contrastive Soft Clustering (CSC) to align derived masks with the image's structure information, softly selecting anchors for each class and calculating weighted distances to push inner-class pixels closer while separating inter-class pixels, thereby ensuring mask distinction and internal consistency. By incorporating sample-specific context, InvSeg learns context-rich text prompts in embedding space and achieves accurate semantic alignment across modalities. Experiments show that InvSeg achieves state-of-the-art performance on the PASCAL VOC and Context datasets. Project page: https://jylin8100.github.io/InvSegProject/.
MLLM as Video Narrator: Mitigating Modality Imbalance in Video Moment Retrieval
Jun 25, 2024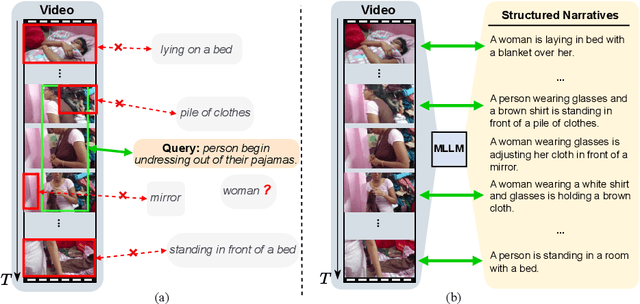

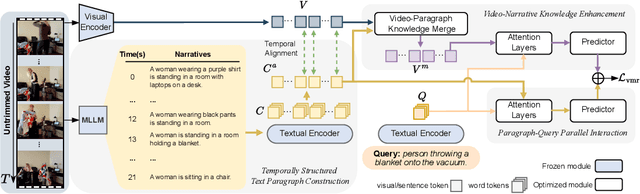
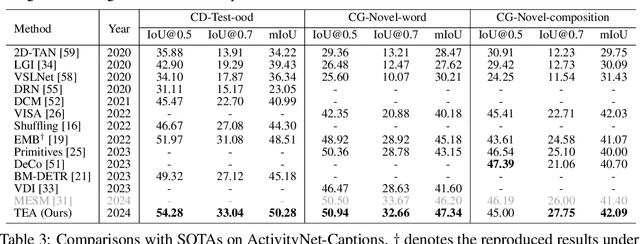
Video Moment Retrieval (VMR) aims to localize a specific temporal segment within an untrimmed long video given a natural language query. Existing methods often suffer from inadequate training annotations, i.e., the sentence typically matches with a fraction of the prominent video content in the foreground with limited wording diversity. This intrinsic modality imbalance leaves a considerable portion of visual information remaining unaligned with text. It confines the cross-modal alignment knowledge within the scope of a limited text corpus, thereby leading to sub-optimal visual-textual modeling and poor generalizability. By leveraging the visual-textual understanding capability of multi-modal large language models (MLLM), in this work, we take an MLLM as a video narrator to generate plausible textual descriptions of the video, thereby mitigating the modality imbalance and boosting the temporal localization. To effectively maintain temporal sensibility for localization, we design to get text narratives for each certain video timestamp and construct a structured text paragraph with time information, which is temporally aligned with the visual content. Then we perform cross-modal feature merging between the temporal-aware narratives and corresponding video temporal features to produce semantic-enhanced video representation sequences for query localization. Subsequently, we introduce a uni-modal narrative-query matching mechanism, which encourages the model to extract complementary information from contextual cohesive descriptions for improved retrieval. Extensive experiments on two benchmarks show the effectiveness and generalizability of our proposed method.
Hybrid-Learning Video Moment Retrieval across Multi-Domain Labels
Jun 03, 2024Video moment retrieval (VMR) is to search for a visual temporal moment in an untrimmed raw video by a given text query description (sentence). Existing studies either start from collecting exhaustive frame-wise annotations on the temporal boundary of target moments (fully-supervised), or learn with only the video-level video-text pairing labels (weakly-supervised). The former is poor in generalisation to unknown concepts and/or novel scenes due to restricted dataset scale and diversity under expensive annotation costs; the latter is subject to visual-textual mis-correlations from incomplete labels. In this work, we introduce a new approach called hybrid-learning video moment retrieval to solve the problem by knowledge transfer through adapting the video-text matching relationships learned from a fully-supervised source domain to a weakly-labelled target domain when they do not share a common label space. Our aim is to explore shared universal knowledge between the two domains in order to improve model learning in the weakly-labelled target domain. Specifically, we introduce a multiplE branch Video-text Alignment model (EVA) that performs cross-modal (visual-textual) matching information sharing and multi-modal feature alignment to optimise domain-invariant visual and textual features as well as per-task discriminative joint video-text representations. Experiments show EVA's effectiveness in exploring temporal segment annotations in a source domain to help learn video moment retrieval without temporal labels in a target domain.
UniTSyn: A Large-Scale Dataset Capable of Enhancing the Prowess of Large Language Models for Program Testing
Feb 04, 2024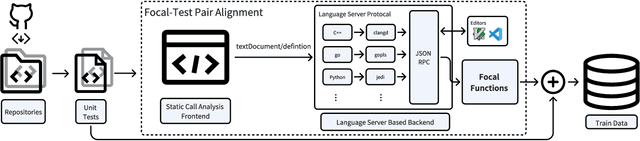
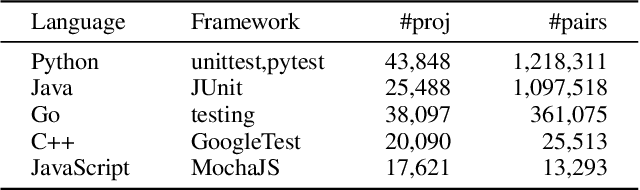
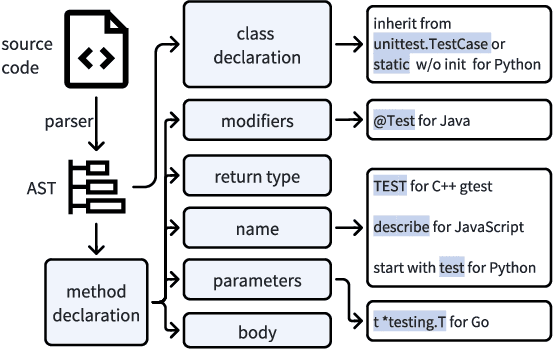
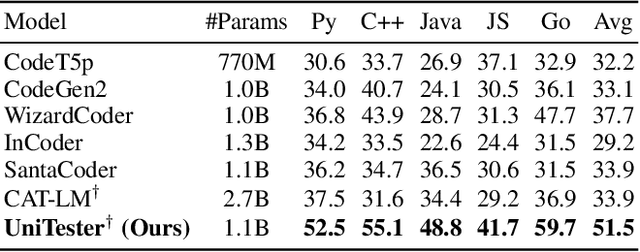
The remarkable capability of large language models (LLMs) in generating high-quality code has drawn increasing attention in the software testing community. However, existing code LLMs often demonstrate unsatisfactory capabilities in generating accurate and complete tests since they were trained on code snippets collected without differentiating between code for testing purposes and other code. In this paper, we present a large-scale dataset UniTSyn, which is capable of enhancing the prowess of LLMs for Unit Test Synthesis. Associating tests with the tested functions is crucial for LLMs to infer the expected behavior and the logic paths to be verified. By leveraging Language Server Protocol, UniTSyn achieves the challenging goal of collecting focal-test pairs without per-project execution setups or per-language heuristics that tend to be fragile and difficult to scale. It contains 2.7 million focal-test pairs across five mainstream programming languages, making it possible to be utilized for enhancing the test generation ability of LLMs. The details of UniTSyn can be found in Table 1. Our experiments demonstrate that, by building an autoregressive model based on UniTSyn, we can achieve significant benefits in learning and understanding unit test representations, resulting in improved generation accuracy and code coverage across all evaluated programming languages. Code and data will be publicly available.
Generative Video Diffusion for Unseen Cross-Domain Video Moment Retrieval
Jan 29, 2024Video Moment Retrieval (VMR) requires precise modelling of fine-grained moment-text associations to capture intricate visual-language relationships. Due to the lack of a diverse and generalisable VMR dataset to facilitate learning scalable moment-text associations, existing methods resort to joint training on both source and target domain videos for cross-domain applications. Meanwhile, recent developments in vision-language multimodal models pre-trained on large-scale image-text and/or video-text pairs are only based on coarse associations (weakly labelled). They are inadequate to provide fine-grained moment-text correlations required for cross-domain VMR. In this work, we solve the problem of unseen cross-domain VMR, where certain visual and textual concepts do not overlap across domains, by only utilising target domain sentences (text prompts) without accessing their videos. To that end, we explore generative video diffusion for fine-grained editing of source videos controlled by the target sentences, enabling us to simulate target domain videos. We address two problems in video editing for optimising unseen domain VMR: (1) generation of high-quality simulation videos of different moments with subtle distinctions, (2) selection of simulation videos that complement existing source training videos without introducing harmful noise or unnecessary repetitions. On the first problem, we formulate a two-stage video diffusion generation controlled simultaneously by (1) the original video structure of a source video, (2) subject specifics, and (3) a target sentence prompt. This ensures fine-grained variations between video moments. On the second problem, we introduce a hybrid selection mechanism that combines two quantitative metrics for noise filtering and one qualitative metric for leveraging VMR prediction on simulation video selection.
Code Representation Pre-training with Complements from Program Executions
Sep 04, 2023Large language models (LLMs) for natural language processing have been grafted onto programming language modeling for advancing code intelligence. Although it can be represented in the text format, code is syntactically more rigorous in order to be properly compiled or interpreted to perform a desired set of behaviors given any inputs. In this case, existing works benefit from syntactic representations to learn from code less ambiguously in the forms of abstract syntax tree, control-flow graph, etc. However, programs with the same purpose can be implemented in various ways showing different syntactic representations while the ones with similar implementations can have distinct behaviors. Though trivially demonstrated during executions, such semantics about functionality are challenging to be learned directly from code, especially in an unsupervised manner. Hence, in this paper, we propose FuzzPretrain to explore the dynamic information of programs revealed by their test cases and embed it into the feature representations of code as complements. The test cases are obtained with the assistance of a customized fuzzer and are only required during pre-training. FuzzPretrain yielded more than 6%/9% mAP improvements on code search over its counterparts trained with only source code or AST, respectively. Our extensive experimental results show the benefits of learning discriminative code representations with program executions.