 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColor When It Counts: Grayscale-Guided Online Triggering for Always-On Streaming Video Sensing
Mar 23, 2026Always-on sensing is essential for next-generation edge/wearable AI systems, yet continuous high-fidelity RGB video capture remains prohibitively expensive for resource-constrained mobile and edge platforms. We present a new paradigm for efficient streaming video understanding: grayscale-always, color-on-demand. Through preliminary studies, we discover that color is not always necessary. Sparse RGB frames suffice for comparable performance when temporal structure is preserved via continuous grayscale streams. Building on this insight, we propose ColorTrigger, an online training-free trigger that selectively activates color capture based on windowed grayscale affinity analysis. Designed for real-time edge deployment, ColorTrigger uses lightweight quadratic programming to detect chromatic redundancy causally, coupled with credit-budgeted control and dynamic token routing to jointly reduce sensing and inference costs. On streaming video understanding benchmarks, ColorTrigger achieves 91.6% of full-color baseline performance while using only 8.1% RGB frames, demonstrating substantial color redundancy in natural videos and enabling practical always-on video sensing on resource-constrained devices.
Egocentric Co-Pilot: Web-Native Smart-Glasses Agents for Assistive Egocentric AI
Mar 01, 2026What if accessing the web did not require a screen, a stable desk, or even free hands? For people navigating crowded cities, living with low vision, or experiencing cognitive overload, smart glasses coupled with AI agents could turn the web into an always-on assistive layer over daily life. We present Egocentric Co-Pilot, a web-native neuro-symbolic framework that runs on smart glasses and uses a Large Language Model (LLM) to orchestrate a toolbox of perception, reasoning, and web tools. An egocentric reasoning core combines Temporal Chain-of-Thought with Hierarchical Context Compression to support long-horizon question answering and decision support over continuous first-person video, far beyond a single model's context window. Additionally, a lightweight multimodal intent layer maps noisy speech and gaze into structured commands. We further implement and evaluate a cloud-native WebRTC pipeline integrating streaming speech, video, and control messages into a unified channel for smart glasses and browsers. In parallel, we deploy an on-premise WebSocket baseline, exposing concrete trade-offs between local inference and cloud offloading in terms of latency, mobility, and resource use. Experiments on Egolife and HD-EPIC demonstrate competitive or state-of-the-art egocentric QA performance, and a human-in-the-loop study on smart glasses shows higher task completion and user satisfaction than leading commercial baselines. Taken together, these results indicate that web-connected egocentric co-pilots can be a practical path toward more accessible, context-aware assistance in everyday life. By grounding operation in web-native communication primitives and modular, auditable tool use, Egocentric Co-Pilot offers a concrete blueprint for assistive, always-on web agents that support education, accessibility, and social inclusion for people who may benefit most from contextual, egocentric AI.
EgoGraph: Temporal Knowledge Graph for Egocentric Video Understanding
Feb 27, 2026Ultra-long egocentric videos spanning multiple days present significant challenges for video understanding. Existing approaches still rely on fragmented local processing and limited temporal modeling, restricting their ability to reason over such extended sequences. To address these limitations, we introduce EgoGraph, a training-free and dynamic knowledge-graph construction framework that explicitly encodes long-term, cross-entity dependencies in egocentric video streams. EgoGraph employs a novel egocentric schema that unifies the extraction and abstraction of core entities, such as people, objects, locations, and events, and structurally reasons about their attributes and interactions, yielding a significantly richer and more coherent semantic representation than traditional clip-based video models. Crucially, we develop a temporal relational modeling strategy that captures temporal dependencies across entities and accumulates stable long-term memory over multiple days, enabling complex temporal reasoning. Extensive experiments on the EgoLifeQA and EgoR1-bench benchmarks demonstrate that EgoGraph achieves state-of-the-art performance on long-term video question answering, validating its effectiveness as a new paradigm for ultra-long egocentric video understanding.
Optimizing Multimodal LLMs for Egocentric Video Understanding: A Solution for the HD-EPIC VQA Challenge
Jan 15, 2026Multimodal Large Language Models (MLLMs) struggle with complex video QA benchmarks like HD-EPIC VQA due to ambiguous queries/options, poor long-range temporal reasoning, and non-standardized outputs. We propose a framework integrating query/choice pre-processing, domain-specific Qwen2.5-VL fine-tuning, a novel Temporal Chain-of-Thought (T-CoT) prompting for multi-step reasoning, and robust post-processing. This system achieves 41.6% accuracy on HD-EPIC VQA, highlighting the need for holistic pipeline optimization in demanding video understanding. Our code, fine-tuned models are available at https://github.com/YoungSeng/Egocentric-Co-Pilot.
Plug-and-Play Clarifier: A Zero-Shot Multimodal Framework for Egocentric Intent Disambiguation
Nov 12, 2025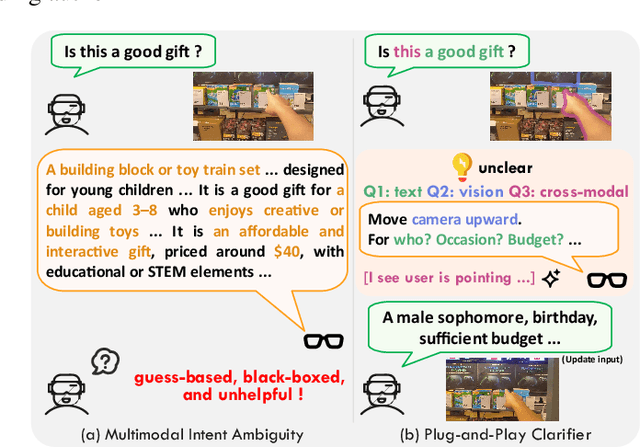
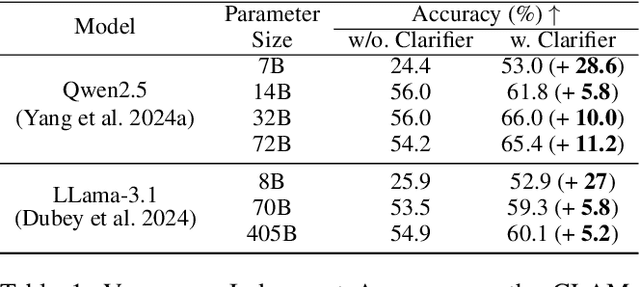
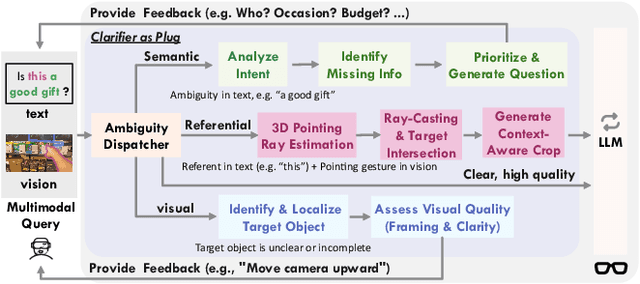
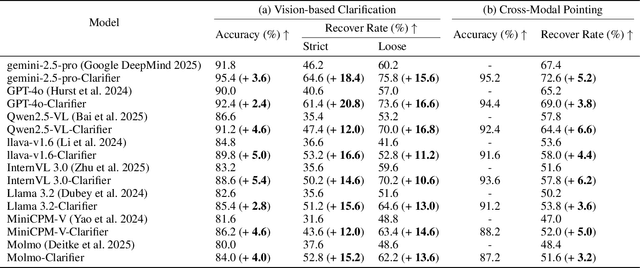
The performance of egocentric AI agents is fundamentally limited by multimodal intent ambiguity. This challenge arises from a combination of underspecified language, imperfect visual data, and deictic gestures, which frequently leads to task failure. Existing monolithic Vision-Language Models (VLMs) struggle to resolve these multimodal ambiguous inputs, often failing silently or hallucinating responses. To address these ambiguities, we introduce the Plug-and-Play Clarifier, a zero-shot and modular framework that decomposes the problem into discrete, solvable sub-tasks. Specifically, our framework consists of three synergistic modules: (1) a text clarifier that uses dialogue-driven reasoning to interactively disambiguate linguistic intent, (2) a vision clarifier that delivers real-time guidance feedback, instructing users to adjust their positioning for improved capture quality, and (3) a cross-modal clarifier with grounding mechanism that robustly interprets 3D pointing gestures and identifies the specific objects users are pointing to. Extensive experiments demonstrate that our framework improves the intent clarification performance of small language models (4--8B) by approximately 30%, making them competitive with significantly larger counterparts. We also observe consistent gains when applying our framework to these larger models. Furthermore, our vision clarifier increases corrective guidance accuracy by over 20%, and our cross-modal clarifier improves semantic answer accuracy for referential grounding by 5%. Overall, our method provides a plug-and-play framework that effectively resolves multimodal ambiguity and significantly enhances user experience in egocentric interaction.
MLLM as Video Narrator: Mitigating Modality Imbalance in Video Moment Retrieval
Jun 25, 2024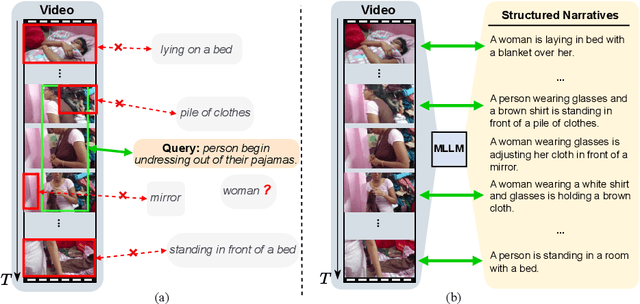

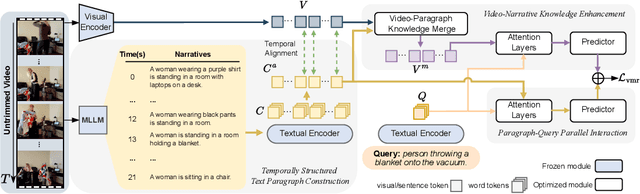
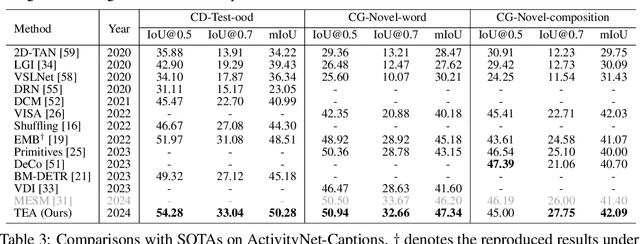
Video Moment Retrieval (VMR) aims to localize a specific temporal segment within an untrimmed long video given a natural language query. Existing methods often suffer from inadequate training annotations, i.e., the sentence typically matches with a fraction of the prominent video content in the foreground with limited wording diversity. This intrinsic modality imbalance leaves a considerable portion of visual information remaining unaligned with text. It confines the cross-modal alignment knowledge within the scope of a limited text corpus, thereby leading to sub-optimal visual-textual modeling and poor generalizability. By leveraging the visual-textual understanding capability of multi-modal large language models (MLLM), in this work, we take an MLLM as a video narrator to generate plausible textual descriptions of the video, thereby mitigating the modality imbalance and boosting the temporal localization. To effectively maintain temporal sensibility for localization, we design to get text narratives for each certain video timestamp and construct a structured text paragraph with time information, which is temporally aligned with the visual content. Then we perform cross-modal feature merging between the temporal-aware narratives and corresponding video temporal features to produce semantic-enhanced video representation sequences for query localization. Subsequently, we introduce a uni-modal narrative-query matching mechanism, which encourages the model to extract complementary information from contextual cohesive descriptions for improved retrieval. Extensive experiments on two benchmarks show the effectiveness and generalizability of our proposed method.
Hybrid-Learning Video Moment Retrieval across Multi-Domain Labels
Jun 03, 2024Video moment retrieval (VMR) is to search for a visual temporal moment in an untrimmed raw video by a given text query description (sentence). Existing studies either start from collecting exhaustive frame-wise annotations on the temporal boundary of target moments (fully-supervised), or learn with only the video-level video-text pairing labels (weakly-supervised). The former is poor in generalisation to unknown concepts and/or novel scenes due to restricted dataset scale and diversity under expensive annotation costs; the latter is subject to visual-textual mis-correlations from incomplete labels. In this work, we introduce a new approach called hybrid-learning video moment retrieval to solve the problem by knowledge transfer through adapting the video-text matching relationships learned from a fully-supervised source domain to a weakly-labelled target domain when they do not share a common label space. Our aim is to explore shared universal knowledge between the two domains in order to improve model learning in the weakly-labelled target domain. Specifically, we introduce a multiplE branch Video-text Alignment model (EVA) that performs cross-modal (visual-textual) matching information sharing and multi-modal feature alignment to optimise domain-invariant visual and textual features as well as per-task discriminative joint video-text representations. Experiments show EVA's effectiveness in exploring temporal segment annotations in a source domain to help learn video moment retrieval without temporal labels in a target domain.
Relax Image-Specific Prompt Requirement in SAM: A Single Generic Prompt for Segmenting Camouflaged Objects
Dec 18, 2023Camouflaged object detection (COD) approaches heavily rely on pixel-level annotated datasets. Weakly-supervised COD (WSCOD) approaches use sparse annotations like scribbles or points to reduce annotation effort, but this can lead to decreased accuracy. The Segment Anything Model (SAM) shows remarkable segmentation ability with sparse prompts like points. However, manual prompt is not always feasible, as it may not be accessible in real-world application. Additionally, it only provides localization information instead of semantic one, which can intrinsically cause ambiguity in interpreting the targets. In this work, we aim to eliminate the need for manual prompt. The key idea is to employ Cross-modal Chains of Thought Prompting (CCTP) to reason visual prompts using the semantic information given by a generic text prompt. To that end, we introduce a test-time adaptation per-instance mechanism called Generalizable SAM (GenSAM) to automatically enerate and optimize visual prompts the generic task prompt for WSCOD. In particular, CCTP maps a single generic text prompt onto image-specific consensus foreground and background heatmaps using vision-language models, acquiring reliable visual prompts. Moreover, to test-time adapt the visual prompts, we further propose Progressive Mask Generation (PMG) to iteratively reweight the input image, guiding the model to focus on the targets in a coarse-to-fine manner. Crucially, all network parameters are fixed, avoiding the need for additional training. Experiments demonstrate the superiority of GenSAM. Experiments on three benchmarks demonstrate that GenSAM outperforms point supervision approaches and achieves comparable results to scribble supervision ones, solely relying on general task descriptions as prompts. our codes is in: https://lwpyh.github.io/GenSAM/.