 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrect after Answer: Enhancing Multi-Span Question Answering with Post-Processing Method
Oct 22, 2024



Multi-Span Question Answering (MSQA) requires models to extract one or multiple answer spans from a given context to answer a question. Prior work mainly focuses on designing specific methods or applying heuristic strategies to encourage models to predict more correct predictions. However, these models are trained on gold answers and fail to consider the incorrect predictions. Through a statistical analysis, we observe that models with stronger abilities do not predict less incorrect predictions compared with other models. In this work, we propose Answering-Classifying-Correcting (ACC) framework, which employs a post-processing strategy to handle incorrect predictions. Specifically, the ACC framework first introduces a classifier to classify the predictions into three types and exclude "wrong predictions", then introduces a corrector to modify "partially correct predictions". Experiments on several MSQA datasets show that ACC framework significantly improves the Exact Match (EM) scores, and further analysis demostrates that ACC framework efficiently reduces the number of incorrect predictions, improving the quality of predictions.
A Lightweight Multi Aspect Controlled Text Generation Solution For Large Language Models
Oct 18, 2024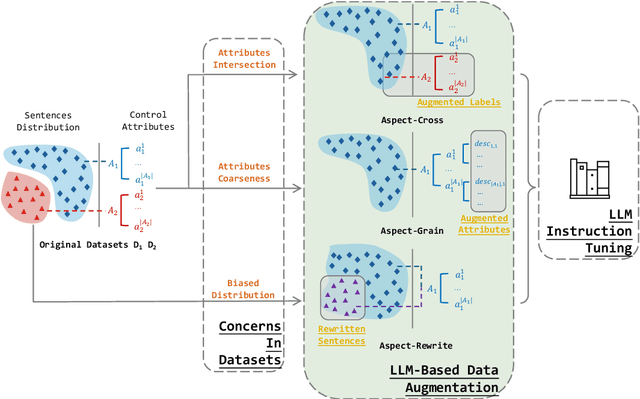
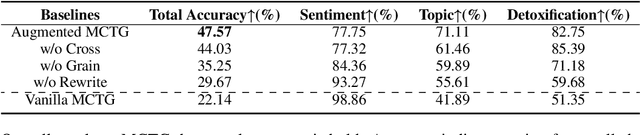


Large language models (LLMs) show remarkable abilities with instruction tuning. However, they fail to achieve ideal tasks when lacking high-quality instruction tuning data on target tasks. Multi-Aspect Controllable Text Generation (MCTG) is a representative task for this dilemma, where aspect datasets are usually biased and correlated. Existing work exploits additional model structures and strategies for solutions, limiting adaptability to LLMs. To activate MCTG ability of LLMs, we propose a lightweight MCTG pipeline based on data augmentation. We analyze bias and correlations in traditional datasets, and address these concerns with augmented control attributes and sentences. Augmented datasets are feasible for instruction tuning. In our experiments, LLMs perform better in MCTG after data augmentation, with a 20% accuracy rise and less aspect correlations.
InvSeg: Test-Time Prompt Inversion for Semantic Segmentation
Oct 15, 2024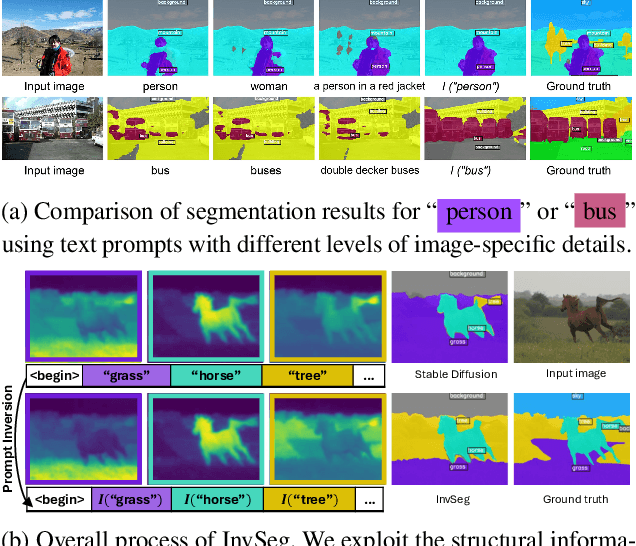
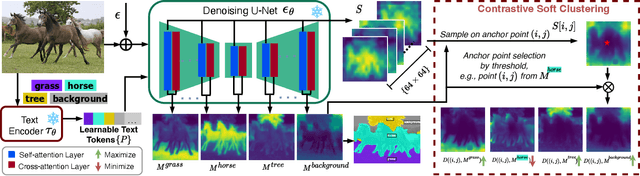
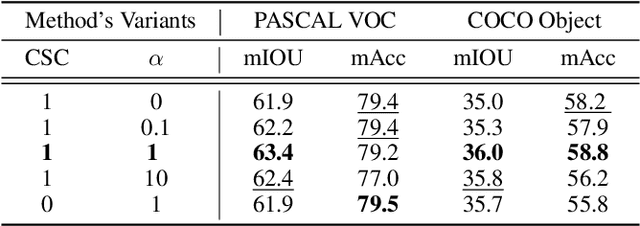
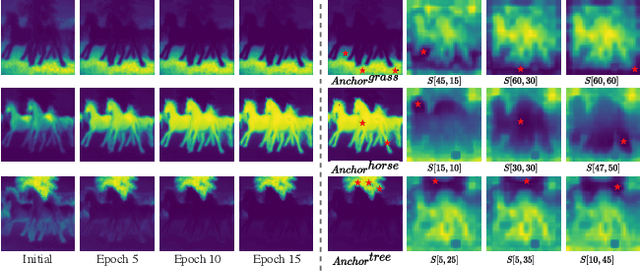
Visual-textual correlations in the attention maps derived from text-to-image diffusion models are proven beneficial to dense visual prediction tasks, e.g., semantic segmentation. However, a significant challenge arises due to the input distributional discrepancy between the context-rich sentences used for image generation and the isolated class names typically employed in semantic segmentation, hindering the diffusion models from capturing accurate visual-textual correlations. To solve this, we propose InvSeg, a test-time prompt inversion method that tackles open-vocabulary semantic segmentation by inverting image-specific visual context into text prompt embedding space, leveraging structure information derived from the diffusion model's reconstruction process to enrich text prompts so as to associate each class with a structure-consistent mask. Specifically, we introduce Contrastive Soft Clustering (CSC) to align derived masks with the image's structure information, softly selecting anchors for each class and calculating weighted distances to push inner-class pixels closer while separating inter-class pixels, thereby ensuring mask distinction and internal consistency. By incorporating sample-specific context, InvSeg learns context-rich text prompts in embedding space and achieves accurate semantic alignment across modalities. Experiments show that InvSeg achieves state-of-the-art performance on the PASCAL VOC and Context datasets. Project page: https://jylin8100.github.io/InvSegProject/.
Leveraging Hallucinations to Reduce Manual Prompt Dependency in Promptable Segmentation
Aug 27, 2024Promptable segmentation typically requires instance-specific manual prompts to guide the segmentation of each desired object. To minimize such a need, task-generic promptable segmentation has been introduced, which employs a single task-generic prompt to segment various images of different objects in the same task. Current methods use Multimodal Large Language Models (MLLMs) to reason detailed instance-specific prompts from a task-generic prompt for improving segmentation accuracy. The effectiveness of this segmentation heavily depends on the precision of these derived prompts. However, MLLMs often suffer hallucinations during reasoning, resulting in inaccurate prompting. While existing methods focus on eliminating hallucinations to improve a model, we argue that MLLM hallucinations can reveal valuable contextual insights when leveraged correctly, as they represent pre-trained large-scale knowledge beyond individual images. In this paper, we utilize hallucinations to mine task-related information from images and verify its accuracy for enhancing precision of the generated prompts. Specifically, we introduce an iterative Prompt-Mask Cycle generation framework (ProMaC) with a prompt generator and a mask generator.The prompt generator uses a multi-scale chain of thought prompting, initially exploring hallucinations for extracting extended contextual knowledge on a test image.These hallucinations are then reduced to formulate precise instance-specific prompts, directing the mask generator to produce masks that are consistent with task semantics by mask semantic alignment. The generated masks iteratively induce the prompt generator to focus more on task-relevant image areas and reduce irrelevant hallucinations, resulting jointly in better prompts and masks. Experiments on 5 benchmarks demonstrate the effectiveness of ProMaC. Code given in https://lwpyh.github.io/ProMaC/.
Toward Exploring the Code Understanding Capabilities of Pre-trained Code Generation Models
Jun 18, 2024Recently, large code generation models trained in a self-supervised manner on extensive unlabeled programming language data have achieved remarkable success. While these models acquire vast amounts of code knowledge, they perform poorly on code understanding tasks, such as code search and clone detection, as they are specifically trained for generation. Pre-training a larger encoder-only architecture model from scratch on massive code data can improve understanding performance. However, this approach is costly and time-consuming, making it suboptimal. In this paper, we pioneer the transfer of knowledge from pre-trained code generation models to code understanding tasks, significantly reducing training costs. We examine effective strategies for enabling decoder-only models to acquire robust code representations. Furthermore, we introduce CL4D, a contrastive learning method designed to enhance the representation capabilities of decoder-only models. Comprehensive experiments demonstrate that our approach achieves state-of-the-art performance in understanding tasks such as code search and clone detection. Our analysis shows that our method effectively reduces the distance between semantically identical samples in the representation space. These findings suggest the potential for unifying code understanding and generation tasks using a decoder-only structured model.
Relax Image-Specific Prompt Requirement in SAM: A Single Generic Prompt for Segmenting Camouflaged Objects
Dec 18, 2023Camouflaged object detection (COD) approaches heavily rely on pixel-level annotated datasets. Weakly-supervised COD (WSCOD) approaches use sparse annotations like scribbles or points to reduce annotation effort, but this can lead to decreased accuracy. The Segment Anything Model (SAM) shows remarkable segmentation ability with sparse prompts like points. However, manual prompt is not always feasible, as it may not be accessible in real-world application. Additionally, it only provides localization information instead of semantic one, which can intrinsically cause ambiguity in interpreting the targets. In this work, we aim to eliminate the need for manual prompt. The key idea is to employ Cross-modal Chains of Thought Prompting (CCTP) to reason visual prompts using the semantic information given by a generic text prompt. To that end, we introduce a test-time adaptation per-instance mechanism called Generalizable SAM (GenSAM) to automatically enerate and optimize visual prompts the generic task prompt for WSCOD. In particular, CCTP maps a single generic text prompt onto image-specific consensus foreground and background heatmaps using vision-language models, acquiring reliable visual prompts. Moreover, to test-time adapt the visual prompts, we further propose Progressive Mask Generation (PMG) to iteratively reweight the input image, guiding the model to focus on the targets in a coarse-to-fine manner. Crucially, all network parameters are fixed, avoiding the need for additional training. Experiments demonstrate the superiority of GenSAM. Experiments on three benchmarks demonstrate that GenSAM outperforms point supervision approaches and achieves comparable results to scribble supervision ones, solely relying on general task descriptions as prompts. our codes is in: https://lwpyh.github.io/GenSAM/.
GridCLIP: One-Stage Object Detection by Grid-Level CLIP Representation Learning
Mar 16, 2023
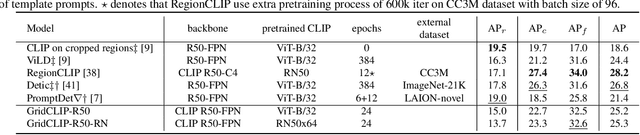


A vision-language foundation model pretrained on very large-scale image-text paired data has the potential to provide generalizable knowledge representation for downstream visual recognition and detection tasks, especially on supplementing the undersampled categories in downstream model training. Recent studies utilizing CLIP for object detection have shown that a two-stage detector design typically outperforms a one-stage detector, while requiring more expensive training resources and longer inference time. In this work, we propose a one-stage detector GridCLIP that narrows its performance gap to those of two-stage detectors, with approximately 43 and 5 times faster than its two-stage counterpart (ViLD) in the training and test process respectively. GridCLIP learns grid-level representations to adapt to the intrinsic principle of one-stage detection learning by expanding the conventional CLIP image-text holistic mapping to a more fine-grained, grid-text alignment. This differs from the region-text mapping in two-stage detectors that apply CLIP directly by treating regions as images. Specifically, GridCLIP performs Grid-level Alignment to adapt the CLIP image-level representations to grid-level representations by aligning to CLIP category representations to learn the annotated (especially frequent) categories. To learn generalizable visual representations of broader categories, especially undersampled ones, we perform Image-level Alignment during training to propagate broad pre-learned categories in the CLIP image encoder from the image-level to the grid-level representations. Experiments show that the learned CLIP-based grid-level representations boost the performance of undersampled (infrequent and novel) categories, reaching comparable detection performance on the LVIS benchmark.
FDAN: Flow-guided Deformable Alignment Network for Video Super-Resolution
May 12, 2021


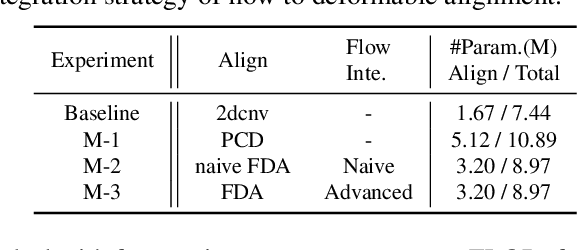
Most Video Super-Resolution (VSR) methods enhance a video reference frame by aligning its neighboring frames and mining information on these frames. Recently, deformable alignment has drawn extensive attention in VSR community for its remarkable performance, which can adaptively align neighboring frames with the reference one. However, we experimentally find that deformable alignment methods still suffer from fast motion due to locally loss-driven offset prediction and lack explicit motion constraints. Hence, we propose a Matching-based Flow Estimation (MFE) module to conduct global semantic feature matching and estimate optical flow as coarse offset for each location. And a Flow-guided Deformable Module (FDM) is proposed to integrate optical flow into deformable convolution. The FDM uses the optical flow to warp the neighboring frames at first. And then, the warped neighboring frames and the reference one are used to predict a set of fine offsets for each coarse offset. In general, we propose an end-to-end deep network called Flow-guided Deformable Alignment Network (FDAN), which reaches the state-of-the-art performance on two benchmark datasets while is still competitive in computation and memory consumption.